

利用LSTM网络结构将车辆过去的位置包含到预测算法中
电子说
描述
摘要:在自动驾驶领域,预测变道意图一直是一个非常活跃的研究领域。然而,大多数文献都集中在单个车辆上,并且在进行预测时没有考虑邻居信息和车辆历史轨迹的累积影响。我们建议应用周围感知LSTM算法来预测车辆执行车道变换的意图,该车道变换利用车辆过去轨迹和其邻居的当前状态。我们根据真实世界的变道数据对模型进行了训练,并且能够在仿真中显示出这两个组件不仅可以提高精度,还可以提前预测变道时间,这对提高自动驾驶车辆的整体性能具有重要作用。
Ⅰ.介绍
车道变换被认为是造成交通事故的主要因素之一[1]。为了使自动驾驶车辆能够在高速公路上行驶,重要的是要预测其他车辆变换车道的意图以防止潜在的碰撞。尝试模拟驾驶员的车道变换行为已经有很多工作,可以分为几种类型:基于规则的算法[2],[3],[4],基于机器学习的算法[5],[ 6],[7]和知识表示算法[8],[9],[10]。
基于规则的算法定义了一组规则来模拟车道变换。最具代表性的是“间隙接受模型”[2],它假设驾驶员的车道变换机动是基于目标车道的超前和滞后间隙。该方法假设如果间隙达到最小可接受值,则驾驶员倾向于进行车道变换。虽然在简单的场景中直观且稳健,但是这样的方法需要大量的参数微调,这可能是繁琐且耗时的。
基于机器学习的算法为这个问题创建了一个数学模型:给定与车辆相关的特征作为输入,车辆的变道意图作为输出,这些方法试图推断映射函数,以获得最佳预测结果。该模型采用了大量分类器,如逻辑回归[5]和SVM分类器[6]。
知识表示算法开发了一个网络模型来模拟人类的推理过程。基于知识的算法在驾驶场景中的应用包括强化学习[11],课程学习[12],以及通过贝叶斯网络学习[8],[9]。但是,模型可能需要很长时间才能在学习过程中概括未知环境中的基本规则。
人力驱动车辆发起车道变换操纵的意图不仅基于车辆自身的状态,例如航向角和加速度,而且还基于其与相邻车辆的关系,例如其与前方车辆的距离。最近,一些参考文献探讨了邻近交通对自身车辆的影响。萨迪等人提出了一种算法,使自身车辆能够在其规划过程中模拟其他车辆的意图,有目的地改变其他车辆的行为[ 13 ]。此外,它还要求了解其他汽车的意图,以一种奖励的形式,而不模仿通常在人类身上发现的合作行为。作者建议使用LSTM [15]来模拟问题的顺序性质以及社交池层来模拟行人之间的相互作用。因此,他们能够在拥挤的人群中模拟行人的轨迹,每个行人都合作地调整他们未来的轨迹。然而,由于数据中的协作交互次数较少,该方法不能直接应用于车道变换问题。
在本文中,我们还提出了利用LSTM网络结构将车辆过去的位置包含到预测算法中,使系统能够提取过去的相关信息。为了模拟其他汽车对决策过程的影响,同时保持问题的易处理性,我们在网络的输入特征中加入了关于邻近车辆的信息。
为了全面了解自然驾驶行为,学习过程需要大量的驾驶和车道变换轨迹,这就是我们选择NGSIM数据集[16]来训练和验证算法的原因。我们还采用了基于Julia的NGSIM [ 17 ]平台来提取网络的输入特征,并可视化交通场景。
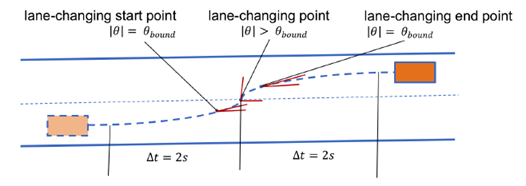
图1.变道轨迹的起点、变道点和终点。
第二节描述了从NGSIM数据集提取和预处理数据的过程。在第三节中,我们介绍了输入特性,并详细解释了具体的网络结构。然后,我们将我们的结果与第四节中的其他方法进行说明和比较。第五节总结了我们的工作成果,并提出了未来可能的工作。
Ⅱ.数据提取和处理
开源联邦高速公路管理局的下一代模拟( NGSIM )数据集[ 16 ]被挑选出来,用于提取车辆轨迹并建立车道变化预测模型,该数据集已被许多先前的研究[5]、[6]号采纳。在0:1秒的时间间隔内,数据集记录了美国101号高速公路[18]和80号州际公路(I-80)高速公路[19]上每辆车的位置,速度,加速度和车头时距信息。两个位置都包含45分钟的车辆轨迹数据。101号高速公路长640米,有5个主要车道和6个辅助车道,而I-80长号公路约500米,有6个主要车道。
我们从NGSIM中提取了6个车辆轨迹数据序列,每个序列10分钟。我们从每个15分钟的序列中删除了前5分钟,以确保每帧中有足够数量的车辆。对于每个序列,前2分钟被定义为测试集,剩余的8分钟被定义为训练集。由于数据以每秒10帧的速度记录,我们总共可以获得1200个测试时间步长和4800个训练时间步长。
车辆被标记为“打算向左改变车道”,“打算沿着车道行驶”,或者“打算在每个时间步骤改变车道”。我们标记车辆状态的方式如下。
如图1所示,我们首先收集所有车道交换点,即车辆重力点越过划分车道的虚线的点,车辆。如果车辆在时间步长t处在变道点,我们在[t-δt,t+δt](δt=2s)检查了它的轨迹,并在该时间段内计算其航向值θ。当θ到达边界值θbound :|θ|=θbound时,我们标记了这个变道轨迹的起点和终点。
图2 ( b )描述了我们标记轨迹片段的方式。对于每辆车,n个连续的时间步长被打包成一个轨迹段。如果轨迹片段的第n个时间步长是变道时间步长,则该片段是变道片段,否则它被标记为车道跟随片段。在本文中,我们将n设置为6,9和12,以确定历史轨迹长度对最终结果的影响。
图2.( A )如果预测车辆连续3个时间步长进行车道变换,则确定车道变换预测点。变道预测时间被定义为变道点和变道预测点之间的时间间隔。( b ) n个连续时间步长被打包成一个轨迹段。如果轨迹片段的第n个时间步长是车道跟随时间步长,则该片段是车道跟随片段,否则它被标记为车道改变片段。
然后,我们可以获得大约60,000个车道更换件,加400,000辆汽车用于训练。这显然涉及一个数据不平衡的问题,在这种情况下,用于训练的车道跟随件比车道变换件多得多,这将导致训练过程中的过度拟合。为了解决这个问题,我们从变道左池、变道后池和变道右池中随机选择了相同数量的片段N,将它们混合在一起作为训练数据集。为了最大限度地利用数据,N被设置为变道右侧池中的件数( 30,000件)。
然后,给定测试集中的前( n1 )个时间步长历史轨迹和邻居信息,在每个时间步长预测每辆车的变道意图。在过滤结果之后还计算了车道变换预测时间。具体地,如果预测车辆进行3个连续时间步长的车道变换,则确定车道变换预测点,并且车道变换预测时间被定义为车道变换点和车道之间的时间间隔 - 改变预测点,如图2(a)所示。
III.方法
在本论文中,我们试图预测汽车是否会改变车道以及它将合并到哪条车道。我们使用一个LSTM来使代理能够对车辆历史轨迹信息进行推理。然而,由于人类的决策行为也将取决于周围的车辆,我们也将车辆邻居信息作为网络的输入。
图3.邻居信息收集。我们首先根据自身车辆的方位和中心位置将相邻空间划分为四个部分,并根据它们与自身车辆的相对位置定义相应的相邻车辆。然后,我们收集这些相邻车辆和自身车辆之间的纵向距离作为相邻特征。如果相应位置没有邻居,我们将距离定义为500米,以推断无限距离。
在下文中,我们将描述提供给预测算法的输入特征,然后简要描述这里使用的网络架构。
A.输入功能
我们为预测算法使用两种类型的输入特征:(a)车辆自身的信息和(b)车辆的邻居信息。车辆自身的信息包括:
1)车辆加速度
2)车辆相对于道路的转向角
3)相对于车道的全球横向车辆位置
4)相对于车道的全局纵向车辆位置
车辆的邻居信息(参见图3,“自我车辆”在这里指的是我们正在估算其车道变换意图的车辆)通过以下特征提供:
1)左车道的存在(如果存在则为1,否则为0)
2)右车道的存在(如果存在则为1,否则为0)
3)自我车辆和左前方车辆之间的纵向距离
4)自我车辆和前车之间的纵向距离
5)自我车辆和右前方车辆之间的纵向距离
6)自我车辆和左后车辆之间的纵向距离
7)自我车辆和后车之间的纵向距离
8)自我车辆和右后车辆之间的纵向距离
B.网络结构
图4.用于车道变换意图预测的LSTM网络结构。
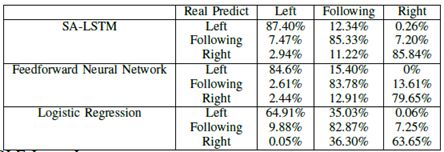
表I.改变车道预测的准确性比较
如图4所示,我们采用LSTM网络结构,来处理这种改变车道的意图预测问题。为车辆自身特征及其邻居特征选择的嵌入维度为64,LSTM网络的隐藏维度为128。我们选择学习率为0:000125,使用soft-max交叉熵损失作为训练损失:loss =-Σi=1yi´log(yi)。其中y是第i个车道改变意图的真实标签(yi´=1,意图存在,yi´=0,意图不存在。i∈{1,2,3}。 y1´是改变车道的左意图,y2´是跟随车道的意图,y3´是换车道的正确意图)。yi是经过soft-max层后第i个车道变换意图的模型的预测输出概率。
IV.结果
A.与其他网络结构的比较
我们获得了我们的结果,并将其与前馈神经网络、逻辑回归和无相邻特征输入的LSTM进行了比较,以显示添加历史轨迹和环境因素的优势。
表I和图5显示了通过我们的算法,前馈神经网络和逻辑回归计算的分类准确率。我们称之为环境感知( SA ) - LSTM的方法,基于历史轨迹信息和邻居信息的优势,在预测精度方面在所有分类类型(左转换道、右转换道和右转换道)上都优于其他两种方法。
B.不同轨迹长度的比较
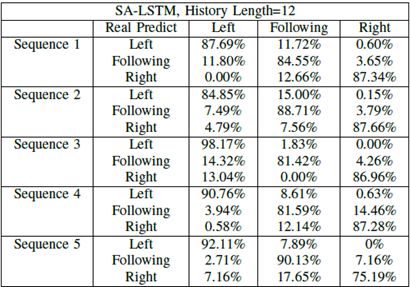
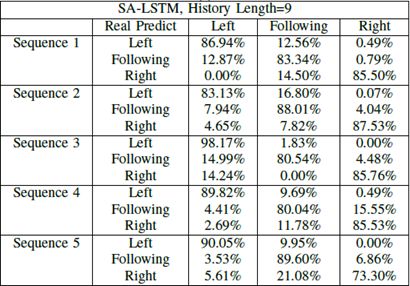
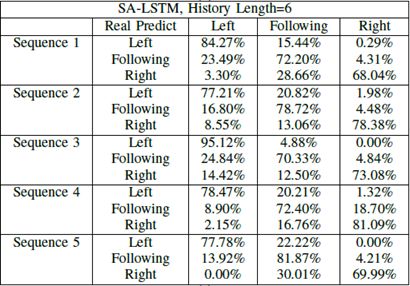
然后,我们获得并比较了不同轨迹长度的预测准确率。具体来说,我们将LSTM结构的历史轨迹长度设置为6,9和12,将它们相互比较。结果显示在表II中,并在图6中可视化。我们比较了五种不同轨迹序列的结果,以帮助我们对曲线变化趋势有一个大致的了解。在所有预测场景中,随着历史长度的增加,预测精度也会增加(左变道、右变道)。
图5所示.不同方法的预测精度比较。SA-LSTM在所有分类类型中都优于其他两种类型,包括右车道变换,车道跟随和左侧车道变换。
从常识来看,我们所拥有的历史轨迹长度越长,我们从先前轨迹获得的信息就越多,并且在最终结果中将获得更高的准确度。但是,在长度和计算时间之间需要权衡。随着长度的增加,准确度的提高也会减慢。从图中我们可以看出,与长度= 9相比,长度= 12仅获得略高的准确率。更重要的是,历史轨迹长度不能太长。否则,一些与当前变道意图无关的因素将被引入输入。基于上述分析,我们设置长度= 12是合理的,其中精度增加率在该NGSIM场景中减慢以获得准确的预测,同时节省计算能力。这种分析也可以在现实世界的应用中采用,在设置适当的历史长度参数时,应该始终考虑准确性和计算能力之间的这种权衡。
(a)
(b)
(c)
表Ⅱ.不同轨迹长度的变道预测精度比较
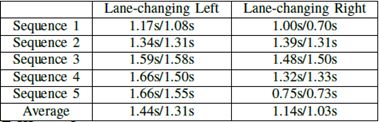
表III.有邻居和无邻居场景的变道预测时间比较
C.有无邻居场景的比较
表III描述了由有和无邻居输入特征LSTM模型生成的换道预测时间,该时间被定义为模型预测将有换道的时间和车辆实际到达换道点的时间间隔。时间间隔越长,预测就越有用。从图7可以看出,在大多数情况下,添加邻居特征会延长变道预测时间。
(a)
(b)
(c)
图6.我们比较了不同历史轨迹长度的预测精度,LSTM网络结构中的历史时间步长。对于每个测试序列,预测准确度随着历史轨迹长度的增加而增加。
(a)
(b)
图7.有和无邻居场景的预测时间比较。左侧变道预测和右侧变道预测都显示,在添加相邻要素后,预测时间增加(如果没有保持)。
V.结论
本文提出了一种LSTM网络结构,引入了相邻车辆的特征,以对每辆单独车辆进行变道意图预测。我们将我们的方法与不同的网络结构(如前馈神经网络和逻辑回归)以及没有邻居特征的LSTM结构进行了比较,以显示添加时间和空间信息的优势。我们还比较了不同历史轨迹长度之间的结构,并将其对最终预测结果的影响保存下来。未来的工作将主要集中在将算法扩展到实际场景中,并观察是否可以在真正的自动驾驶汽车上采用经过训练的网络。LSTM网络的出色表现还表明,尝试其他经常性网络结构可能会进一步改善交通情景中的预测结果。
-
LSTM神经网络在时间序列预测中的应用2024-11-13 2729
-
基于YOLOX目标检测算法的改进2023-03-06 1440
-
使用三种不同结构的LSTM神经网络结构对触觉力进行动态重建2022-10-31 2394
-
基于时空特性的ST-LSTM网络位置预测模型2021-06-11 1252
-
融合网络结构和节点属性的链接预测模型2021-06-09 754
-
基于时序特征的网络分析链路预测算法2021-06-02 953
-
基于异构网络表示方法的论文影响力预测算法2021-05-24 838
-
基于中心点的多类别车辆检测算法综述2021-05-08 1207
-
使用小型Zynq SoC芯片实现实时车辆检测算法的资料函数2019-10-30 1024
-
如何使用小型Zynq SoC硬件加速改进实时车辆检测算法的实现2019-04-26 1010
-
网络结构自动设计算法——BlockQNN2018-05-17 6237
-
异质信息网络中链路预测方法2018-03-07 1276
-
基于网络表示学习与随机游走的链路预测算法2017-11-29 1538
-
CCD图像分析方法和预测算法???2012-07-01 2603
全部0条评论

快来发表一下你的评论吧 !
