

Dave Smith使用Excel电子表格深入浅出地讲解了SVD++的原理
电子说
描述
编者按:Dave Smith使用Excel电子表格深入浅出地讲解了SVD++(基于协同过滤的推荐算法)的原理。
网络货架无穷无尽,寻找想看的影视剧可能让你筋疲力竭。幸运的是,对抗选择疲惫是Netflix的工作……它干得不错。干得太好了。
Netflix魔法般地向你推荐完美的电影,让你的眼睛紧紧地粘在屏幕上,将你的拖延变为沙发上的放纵。
该死的Netflix。你有什么秘密?你怎么能如此了解我们?
Netflix又胜利了……
其实这“魔法”惊人地简单,这篇教程将通过循序渐进的电子表格揭示这一秘密。你可以下载Excel格式的电子表格(推荐),或者使用Google Sheets(运算较慢,由于兼容性问题,缺了一张图):
https://drive.google.com/open?id=1y4X8H56TS6M7AXAU7yIm0EyxhqNUy1sz
如果无法访问Google网盘,可以在论智公众号(ID: jqr_AI)后台留言excel获取替代下载地址。
尽管自从Netflix Prize competition竞赛之后,出现了一大堆关于推荐系统的论文和视频,但其中的大部分要么对初学者而言技术性过强,要么过于抽象,难以实践。
在本文中,我们将从头创建一个电影推荐系统,仅仅使用直白的英语解释和你可以在Excel中操作的公式。所有梯度下降通过手工推导得到,你可以使用Excel微调模型的超参数,加深你的直观理解。
你将学习:
实现SVD++的一个版本的精确步骤,SVD++曾赢得一百万美元的Netflix大奖。
机器到底是如何学习的(梯度下降)。看看Netflix是如何在你没有明确告知的情况下学习你的电影品味的。
超参数调整。 看看如何调整模型超参数(学习率、L2正则化、epoch数、权重初始化)得到更好的预测。
模型评估和可视化。 学习训练数据和测试数据的不同,如何预防过拟合,如何可视化模型特征。
在简短地介绍推荐系统之后,我将带领你创建一个预测一些好莱坞明星的电影评分的模型,整个过程共分为四部分:
模型概览
观看魔法秀(权重初始化、训练)
魔法揭秘(梯度下降、导数)
我将逐步讲解机器学习魔法背后的数学,我将使用实数作为例子代入批量梯度下降的公式(不会使用“宏”或者Excel求解器之类的东西隐藏细节)。

模型评估和可视化
本文适合哪些人?
想要入门推荐系统的人。
Fast.AI的深度学习课程的学生。
充满好奇心,对机器学习感兴趣的人。
特别感谢Fast.AI的Jeremy Howard和Rachel Thomas。这里的电子表格受到了他们的协同过滤课程的启发(相关代码见git.io/fNVW9)。他们呈现的电子表格依赖Excel内置的求解器进行幕后的优化计算;而我这里的电子表格展示了梯度下降计算的每一步,并允许你微调模型的超参数。
如果这份电子表格对你有帮助,请注册我创建的邮件列表,注册后可以收到更多后续的电子表格,帮助你入门机器学习和创建神经网络。
excelwithml.com
推荐系统简介
电影推荐系统可以简化为两大类:
协同过滤(询问密友)
和
基于内容的过滤(标签匹配)
协同过滤
协同过滤基于类似行为进行推荐。
如果Ross和Rachel过去喜欢类似的东西,那么我们将Rachel喜欢而Ross没看过的电影向Ross推荐。你可以将他们看成是“协同”过滤网络货架上的噪音的“品味分身”。如果两个用户的评分有强相关性,那么我们就认定这两个用户“相似”。评分可以是隐式的,也可以是显示的:
隐式(沉溺)—— 整个周末,Ross和Rachel都沉溺于老剧《老友记》。尽管他们没人点赞,但我们相当确定他们喜欢《老友记》(以及他们可能有点自恋)。
显式(喜欢)—— Ross和Rachel都点了赞。
协同过滤有两种:近邻方法和潜因子模型(矩阵分解的一种形式)。本文将聚焦一种称为SVD++的潜因子模型。
基于内容的过滤
基于你过去喜欢的内容的明确标签(类型、演员,等等),Netflix向你推荐具有类似标签的新内容。
一万美元大奖得主是……
在电影推荐的场景下,当数据集足够大的时候,协同过滤(CF)轻而易举就能击败基于内容的过滤。
虽然有无数混合这两大类的变体,但出人意料的是,当CF模型足够好时,加上元数据并没有帮助。
为什么会这样?
人会说谎,行动不会。让数据自己说话
人们声称自己喜欢什么(用户设置,调查,等等)和他们的行为之间有一道巨大的鸿沟。最好让人们的观看行为自己说话。(窍门:想要改善Netflix推荐?访问/WiViewingActivity清理你的观看记录,移除你不喜欢的项。)
2009年,Netflix奖励了一队研究人员一百万美元,这个团队开发了一个算法,将Netflix的预测精确度提升了10%. 尽管获胜算法实际上是超过100种算法的集成,SVD++(一种协同过滤算法)是其中最关键的算法之一,贡献了大多数收益,目前仍在生产环境中使用。
我们将创建的SVD++模型(奇异值分解逼近)和Simon Funk的博客文章Netflix Update: Try This at Home中提到差不多。这篇不出名的文章是2006年Simon在Netflix竞赛开始时写的,首次提出了SVD++模型。在SVD++模型成功之后,几乎所有的Netflix竞赛参加者都用它。
SVD++关键想法:
奇异值(电影评价)可以被“分解”,也就是由一组潜因子(用户偏好和电影特征)决定,直觉上,潜因子表示类型、演员之类的特征。
可以通过梯度下降和已知电影评价迭代学习潜因子。
影响某人评价的用户/电影偏置同样可以学习。
简单而强大。让我们深入一点。
1.1 数据
出于简单性,本文的模型使用了30项虚假的评价(5用户 x 6电影)。
1.2 分割数据——训练集和测试集
我们将使用25项评价来训练模型,剩下5项评价测试模型的精确度。
我们的目标是创建一个在25项已知评价(训练数据)上表现良好的系统,并希望它在5项隐藏(但已知)评价(测试数据)上做出良好的预测。
如果我们有更多数据,我们本可以将数据分为3组——训练集(约70%)、验证集(约20%)、测试集(约10%)。
1.3 评价预测公式
评价预测是用户/电影特征的矩阵乘法(“点积”)加上用户偏置,再加上电影偏置。
形式化定义:

上式中,等式左侧表示用户i对电影j的预测评价。u1、u2、u3为用户潜因子,m1、m2、m3为电影潜因子,ubias为用户偏置,mbias为电影偏置。
1.3.1 用户/电影特征
直觉上说,这些特征表示类型、演员、片长、导演、年代等因素。尽管我们并不清楚每项特征代表什么,但是当我们将其可视化后(见第四部分)我们可以凭直觉猜测它们可能代表什么。
出于简单性,我使用了3项特征,但实际的模型可能有50、100乃至更多特征。特征过多时,模型将“过拟合/记忆”你的训练数据,难以很好地推广到测试数据的预测上。
如果用户的第1项特征(让我们假定它表示“喜剧”)值较高,同时电影的“喜剧”特征的值也很高,那么电影的评价会比较高。
1.3.2 用户/电影偏置
用户偏置取决于评价标准的宽严程度。如果Netflix上所有的平均评分是3.5,而你的所有评分的均值是4.0,那么你的偏置是0.5. 电影偏置同理。如果《泰坦尼克号》的所有用户的评分均值为4.25,那么它的偏置是0.75(= 4.25 - 3.50)。
1.4 RMSE —— 评估预测精确度
RMSE = Root Mean Squared Error (均方根误差)
RMSE是一个数字,尝试回答以下问题“平均而言,预测评价和实际平均差了几颗星(1-5)?”
RMSE越低,意味着预测越准……
上图为RMSE计算过程示意图。左侧为三个用户,“Actual Ratings”为用户的实际评分,“Predictions”为预测评分。计算共分4步:
计算误差(预测 - 实际)
对误差取平方
计算平方误差的均值
取均值的平方根
观察:
我们只在意绝对值差异。 相比实际评分高估了1分的预测,和相比实际评分低估了1分的预测,误差相等,均为1。
RMSE是误差同数量级的平均,而不是误差绝对值的平均。在我们上面的例子中,误差绝对值的平均是0.75(1 + 1 + 0.25 = 2.25,2.25 / 3 = 0.75),但RMSE是0.8292. RMSE给较大的误差更高的权重,这很有用,因为我们更不希望有较大的误差。
RMSE形式化定义:

同样,上式中i表示用户,j表示电影。戴帽的r表示预测评价,r表示实际评价。
1.5 超参数调整
通过电子表格的下拉过滤器,可以调整模型的3个超参数。你应该测试下每种超参数,看看它们对误差的影响。
训练epoch数 —— 1个epoch意味着整个训练集都过了一遍
学习率 —— 控制调整权重/偏置的速度
L2(lambda)惩罚因子 —— 帮助模型预防过拟合训练数据,以更好地概括未见测试数据
模型超参数
现在,让我们看一场魔法秀,看看模型是如何从随机权重开始,学习最优权重的。
观看梯度下降如何运作感觉就像看了一场大卫·布莱恩的魔术秀。
他到底是怎么知道我会在52张牌中选这张的呢?
等等,他刚刚是不是浮空了?
最后你深感敬畏,想要知道魔术是如何变的。我会分两步演示,接着揭露魔法背后的数学。
2.1 “抽一张卡,随便抽一张”(权重初始化)
在训练开始,用户/电影特征的权重是随机分配的,接着算法在训练中学习最佳的权重。
为了揭示这看起来有多么“疯狂”,我们可以随机猜测数字,然后让计算机学习最佳数字。下面是两种权重初始化方案的比较:
简单 —— 用户特征我随机选择了0.1、0.2、0.3,剩下的特征都分配0.1.
Kaiming He —— 更正式、更好的初始化方法,从高斯分布(“钟形曲线”)中随机抽样作为权重,高斯分布的均值为零,标准差由特征个数决定(细节见后)。
2.2 “观赏魔术”(查看训练误差)
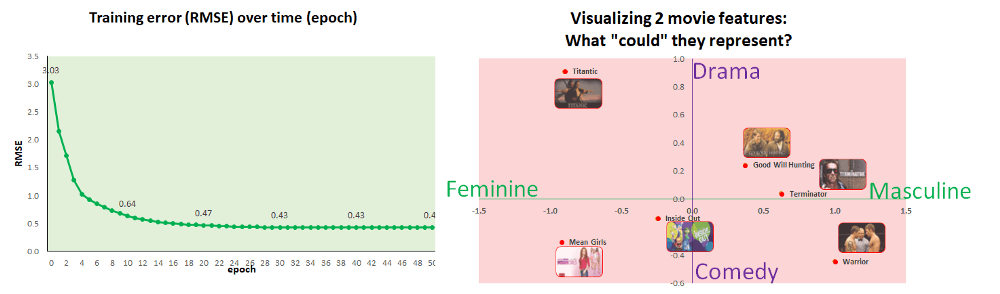
看看使用以上两种方案学习权重最佳值的效果,从开始(epoch 0)到结束(epoch 50),RMSE训练误差是如何变化的:
如你所见,两种权重初始化方案在训练结束后都收敛到相似的“误差”(0.12和0.17),但Kaiming He方法收敛得更快。
关键点:无论我们开始的权重是什么样的,机器将随着时间推移学到良好的值。
注意:如果你想要试验其他初始化权重,可以在电子表格的“hyperparametersandinitial_wts”表的G3-J7、N3-Q8单元格中输入你自己的值。权重取值范围为-1到1.
想要了解更多关于Kaiming He初始化的内容,请接着读下去;否则,可以直接跳到第3部分学习算法的数学。
Kaiming He权重初始化
权重 = 正态分布随机抽样,分布均值为0,标准差为(=SquareRoot(2/特征数))
电子表格中的值由以下公式得到:=NORMINV(RAND(),0,SQRT(2/3))
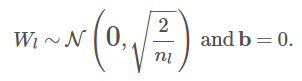
现在,是时候书呆一点,一步一步地了解梯度下降的数学了。
如果你不是真想知道魔法是如何起效的,那么可以跳过这一部分,直接看第4部分。
梯度下降是在训练时使用的迭代算法,通过梯度下降更新电影特征、用户偏好的权重和偏置,以做出更好的预测。
梯度下降的一般周期为:
定义一个最小化权重的代价/损失函数
计算预测
计算梯度(每个权重的代价变动)
在最小化代价的方向上“一点点地”(学习率)更新每个权重
重复第2-4步
你可以访问电子表格的“training”(训练)表,其中第11-16行是更新Tina Fey的第一项用户特征的过程。
由于数据集很小,我们将使用批量梯度下降。这意味着我们在训练时将使用整个数据集(在我们的例子中,一个用户的所有电影),而不是像随机梯度下降之类的算法一样每次迭代一个样本(在我们的例子中,一个用户的一部电影),当数据集较大时,随机梯度下降更快。
3.1 定义最小化的代价函数
我们将使用下面的公式,我们的目标是找到合适的潜因子(矩阵U、M)的值,以最小化SSE(平方误差之和)加上一个帮助模型提升概括性的L2权重惩罚项。
下面是Excel中的代价函数计算。计算过程忽略了1/2系数,因为它们仅用于梯度下降以简化数学。
L2正则化和过拟合
我们加入了权重惩罚(L2正则化或“岭回归”)以防止潜因子值过高。这确保模型没有“过拟合”(也就是记忆)训练数据,否则模型在未见的测试电影上表现不会好。
之前,我们没有使用L2正则化惩罚(系数为0)的情况下训练模型,50个epoch后,RMSE训练误差为0.12.
但是模型在测试数据上的表现如何呢?
在上图中,我们看到,测试集上的RMSE为2.54,显然我们的模型过拟合了训练数据。
我们将L2惩罚系数从0.000改为0.300后,模型在未见测试数据上的表现好一点了:
3.2 计算预测
我们将计算Tina的电影预测。我们将忽略《泰坦尼克号》,因为它在测试数据集中,不在训练数据集中。
我们之前给出过预测的计算公式(1.3节),为了便于查看,这里再重复一遍:

3.3 计算梯度
目标是找到误差对应于将更新的权重的梯度(“坡度”)。
得出梯度之后,稍微将权重“移动一点点”,沿着梯度的反方向“下降”,在对每个权重进行这一操作后,下一epoch的代价应该会低一些。
“移动一点点”具体移动多少,取决于学习率。在得到梯度(3.3)之后,会用到学习率。
梯度下降法则:将权重往梯度的反方向移动,以减少误差
第1步:计算Tina Fey的第一个潜因子的代价梯度(u1)。
1.1 整理代价目标函数,取代价在Tina Fey的第一个潜因子(u1)上的偏导数。
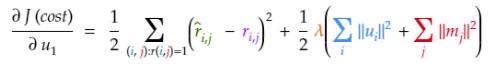

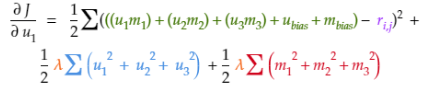
1.3 将公式每部分中的u1视为常数,取u1在公式每部分的代价上的偏导数。
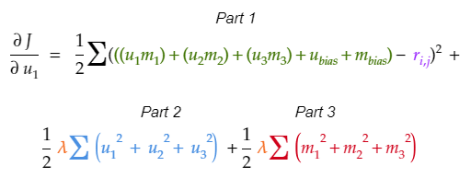
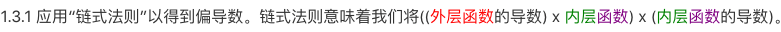

1.3.2 应用“幂法则”以得到偏导数。根据幂法则,指数为2,所以将指数降1,并乘上系数1/2. u2和u3视作常数,变为0.
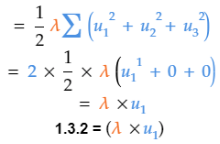
1.3.3 应用“常数法则”以得到偏导数。
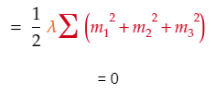
由于u1对这些项毫无影响,结果是0.1.3.3 = 01.4 结合1.3.1、1.3.2、1.3.3得到代价在u1上的偏导数。
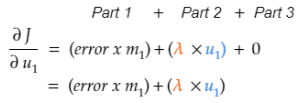
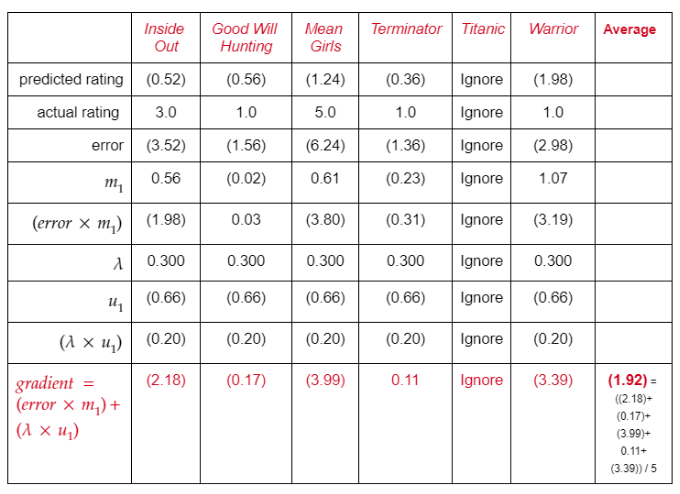
第2步:对训练集中Tina看过的每部电影,利用前面的公式计算梯度,接着计算Tina看过的所有电影的平均梯度。
3.4 更新权重


“training”(训练)表的X11-X16单元格对应上面的计算过程。
你可以看到,电影特征和用户/电影偏置以类似的方式更新。
每一个训练epoch更新所有的电影/用户特征及偏置。
现在我们已经训练好了模型,让我们可视化电影的2个潜因子。
如果我们的模型更复杂,包括10、20、50+潜因子,我们可以使用一种称为“主成分分析(PCA)”的技术提取出最重要的特征,接着将其可视化。
相反,我们的模型仅仅包括3项特征,所以我们将可视化其中的2项特征,基于学习到的特征将每部电影绘制在图像上。绘制图像之后,我们可以解释每项特征“可能代表什么”。
从直觉出发,电影特征1可能解释为悲剧与喜剧,而电影特征3可能解释为男性向与女性向。
这不是完美的解释,但还算一种合理的解释。《勇士》(warrior)一般归为剧情片,而不是喜剧片。不过其他电影基本符合以上解释。
总结
电影评价由一个电影向量和一个用户向量组成。在你评价了一些电影之后(显式或隐式),推荐系统将利用群体的智慧和你的评价预测你可能喜欢的其他电影。向量(或“潜因子”)的维度取决于数据集的大小,可以通过试错法确定。
我鼓励你实际操作下电子表格,看看改变模型的超参数会带来什么改变。
-
excel电子表格教程2008-05-21 12001
-
labview中什么是电子表格字符串2011-11-16 8175
-
“读取电子表格文件”函数无法读取EXCEL中的数据2012-09-06 23053
-
LABVIEW 电子表格问题2013-09-12 5604
-
怎么调用电脑的excel文件直接写入到labview的电子表格么2015-08-22 3925
-
labview可以读取哪些类型的电子表格?2015-09-10 2933
-
电子表格排序 程序2016-06-09 10734
-
面板怎么保存到两个excel电子表格中2018-10-25 2713
-
LabVIEW电子表格读写2019-07-09 2778
-
电子表格处理软件Excel培训讲义2009-03-11 1213
-
电子表格是如何影响数字货币的2019-05-17 2062
-
AN-253:使用电子表格查找运算放大器噪声2021-04-21 706
-
EasySMU Excel控件电子表格2021-05-28 886
-
将Excel XLSX电子表格导入ASP.NET Core中的TX文本控件和C#中的Windows窗体2023-03-30 2142
-
传统电子表格Excel和Teable多维表格数据库的区别?2024-10-23 2080
全部0条评论

快来发表一下你的评论吧 !
