

用 Python 给 Amazon 做“全身 CT”——可量产、可扩展的商品详情爬虫实战
电子说
1.4w人已加入
描述
一、技术选型:为什么选 Python 而不是 Java?
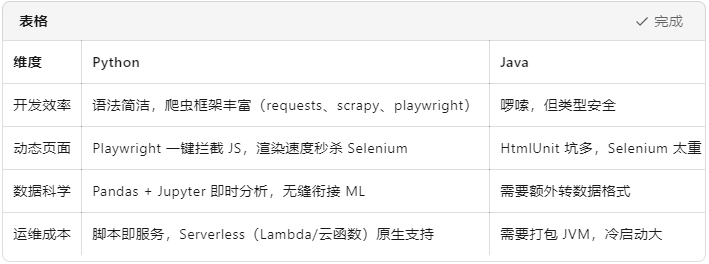
结论:“调研阶段用 Python,上线后如果 QPS 爆表再考虑 Java 重构。”
二、整体架构速览(3 分钟看懂)

三、开发前准备(5 分钟搞定)
环境
Python 3.11 + VSCode + 虚拟环境
依赖一次性装完
bash
python -m venv venv source venv/bin/activate pip install playwright pandas tqdm loguru fake-useragent aiofiles playwright install chromium # 自动下载浏览器
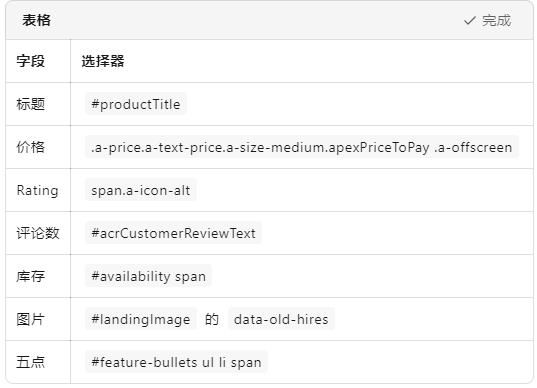
目标字段 & CSS 选择器
四、MVP:120 行代码即可跑通
单文件脚本,支持异步并发 10 个 ASIN,自动重试 429,结果直接写 amazon.csv。
Python
import asyncio, csv, re, random
from pathlib import Path
from playwright.async_api import async_playwright
from loguru import logger
from fake_useragent import UserAgent
import pandas as pd
CONCURRENCY = 10
RETRY = 3
TIMEOUT = 35_000
RESULT = "amazon.csv"
HEADERS = ["asin","title","price","rating","review_count","availability","img_url","scrape_time"]
async def scrape_one(page, asin: str) - > dict:
url = f"https://www.amazon.com/dp/{asin}"
logger.info("
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Python爬虫与Web开发库盘点2018-05-10 2652
-
0基础入门Python爬虫实战课2021-07-25 2464
-
详细用Python写网络爬虫2017-09-07 960
-
用Python写网络爬虫2021-06-01 978
-
从 0 到 1:用 PHP 爬虫优雅地拿下京东商品详情2025-09-23 1217
-
淘宝商品详情接口(item_get)企业级全解析:参数配置、签名机制与 Python 代码实战2025-09-26 1224
-
淘宝商品详情API接口技术解析与实战应用2025-11-04 646
-
# 深度解析:爬虫技术获取淘宝商品详情并封装为API的全流程应用2025-11-17 600
-
京东关键词搜索商品列表的Python爬虫实战2026-01-04 1728
-
1688 商品详情 API 调用与数据解析 Python 实战2026-02-10 567
-
告别手动!1688商品详情API让你秒级获取商品数据2026-05-09 677
-
亚马逊商品详情API 实战总结(技术复盘)2026-05-20 788
-
淘宝/天猫商品详情API 实战总结(技术复盘)2026-05-22 120
-
京东商品详情 API 实战总结(技术复盘)2026-05-25 197
-
1688商品详情API 实战总结(技术复盘)2026-05-26 137
全部0条评论

快来发表一下你的评论吧 !
