

引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别
电子说
描述
引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别。
华中科技大学白翔老师团队在自然场景文本检测与识别领域成果颇丰,这篇被ECCV2018接收的论文《Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes》是其最新力作。
文章指出,最近,基于深度神经网络的模型已经主导了场景文本检测和识别领域。在该文中,研究了场景“text spotting”的问题,其旨在自然图像中同时进行文本检测和识别。
该文受到Mask R-CNN的启发提出了一种用于场景text spotting的可端到端训练的神经网络模型:Mask TextSpotter。与以前使用端到端可训练深度神经网络完成text spotting的方法不同,Mask TextSpotter利用简单且平滑的端到端学习过程,通过语义分割获得精确的文本检测和识别。此外,它在处理不规则形状的文本实例(例如,弯曲文本)方面优于之前的方法。
在 ICDAR2013、ICDAR2015和Total-Text数据库上的实验表明,所提出的方法在场景文本检测和端到端文本识别任务中都达到了state-of-the-art的水平。
弯曲形状文本检测与识别的例子:
左图是水平text spotting方法的结果,它的检测框是水平的;中间图是具有方向的text spotting方法的结果,它的检测框倾斜;右图是该文提出的Mask TextSpotter算法的结果,它的检测框不是外接矩形而是一个最小外接多边形,对这种弯曲文本达到了更精确的文本检测和识别。
▌网络架构
网络架构由四部分组成,骨干网feature pyramid network (FPN) ,文本候选区域生成网络region proposal network (RPN) ,文本包围盒回归网络Fast R-CNN ,文本实例分割与字符分割网络mask branch。
▌训练阶段
RPN首先生成大量的文本候选区域,然后这些候选区域的RoI特征被送入Fast R-CNN branch和mask branch,由它们去分别生成精确的文本候选包围盒(text candidate boxes)、文本实例分割图(text instance segmentation maps)、字符分割图(character segmentation maps)。
尤其值得一提的是Mask Branch,如下图:
它将输入的RoI(固定大小16*64)经过4层卷积层和1层反卷积层,生成38通道的图(大小32*128),包括一个全局文本实例图——它给出了文本区域的精确定位,无论文本排列的形状如何它都能分割出来,还包括36个字符图(对应于字符0~9,A~Z),一个字符背景图(排除字符后的的所有背景区域),在后处理阶段字符背景图会被用到。
这是一个多任务模型,其Loss 组成:

▌推理阶段
推理阶段mask branch的输入RoIs来自于Fast R-CNN的输出。
推理的过程如下:首先输入一幅测试图像,通过Fast R-CNN获取候选文本区域,然后通过NMS(非极大抑制)过滤掉冗余的候选区域,剩下的候选区域resize后送入mask branch,得到全局文本实例图,和字符图。通过计算全局文本实例图的轮廓可以直接得到包围文本的多边形,通过在字符图上使用提出的pixel voting方法生成字符序列。
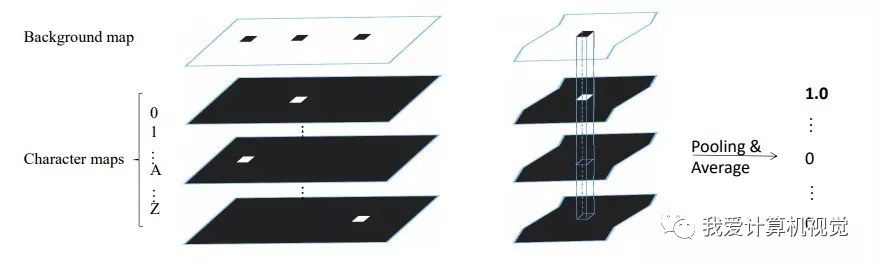
如上图所示,Pixel voting 方法根据字符背景图中每一个联通区域,计算每一字符层相应区域的平均字符概率,即得到了识别的结果。
为了在识别出来的字符序列中找到最佳匹配单词,作者在编辑距离(Edit Distance)基础上发明了加权编辑距离(Weighted Edit Distance)。

识别结果示例:
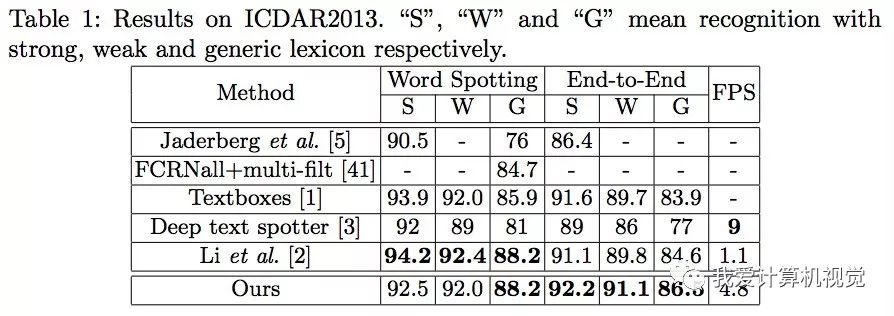
▌ICDAR2013的结果
该库主要用来验证在水平文本上的识别效果。
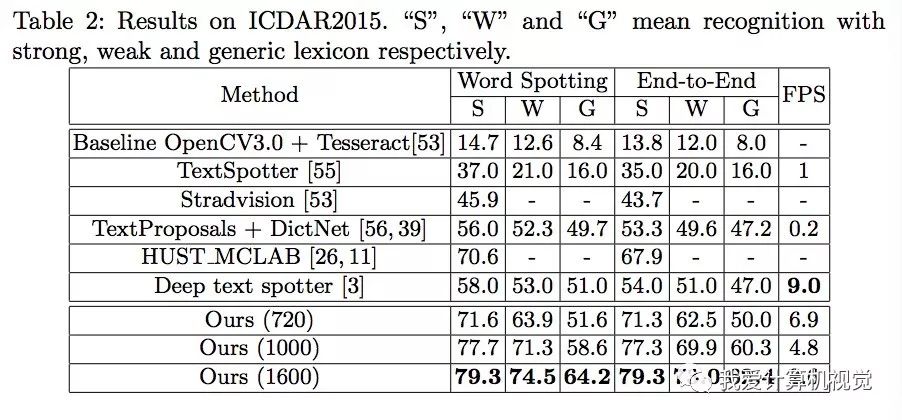
▌ICDAR2015的结果
用来验证方向变化的文本的结果。
▌Total-Text结果
验证弯曲的文本检测识别结果。

弯曲文本识别示例
▌速度
在Titan Xp 显卡上,720*1280的图像,速度可以达到6.9FPS。
▌效果分析
作者通过进一步的实验分析,发现:如果去除字符图子网络,只训练检测模型,检测的性能会下降,说明检测可以受益于识别模块。下图中Ours(det only)为只有检测的模型。

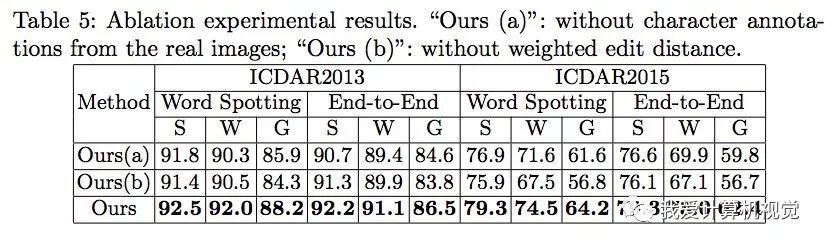
如果去除训练样本中的真实世界字符标注图像,模型依然可以达到相当竞争力的性能。下图中Ours(a)即不使用真实世界字符标注图像的训练结果。
通过加权编辑距离(weighted edit distance)和原始编辑距离的比较,发现,加权编辑距离可以明显提高识别性能。下图中Ours(b)为原始编辑距离的结果。
该文将Mask R-CNN语义分割的方法用于文本检测与识别,取得了显著的性能改进,并能成功应对任意形状的文本,其他语义分割方法是否也能拿来试一下呢?(该文目前还没有开源代码。)
-
图像分割与语义分割中的CNN模型综述2024-07-09 2723
-
PyTorch教程14.8之基于区域的CNN(R-CNN)2023-06-05 579
-
手把手教你使用LabVIEW实现Mask R-CNN图像实例分割(含源码)2023-03-21 3603
-
用于实例分割的Mask R-CNN框架2022-04-13 3465
-
基于Mask R-CNN的遥感图像处理技术综述2021-05-08 1068
-
一种基于Mask R-CNN的人脸检测及分割方法2021-04-01 1130
-
基于改进Faster R-CNN的目标检测方法2021-03-23 1011
-
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割2019-04-22 3447
-
FAIR何恺明、Ross等人最新提出实例分割的通用框架TensorMask2019-04-08 12007
-
手把手教你操作Faster R-CNN和Mask R-CNN2019-04-04 13806
-
什么是Mask R-CNN?Mask R-CNN的工作原理2018-07-20 68800
-
Mask R-CNN:自动从视频中制作目标物体的GIF动图2018-02-03 12168
-
介绍目标检测工具Faster R-CNN,包括它的构造及实现原理2018-01-27 19455
全部0条评论

快来发表一下你的评论吧 !
