

数据挖掘与机器学习项目特征工程实战
电子说
描述
找特征这件事,Andrew Ng在深度学习网课中提到过,原课件见第3课结构化机器学习项目中的2.9和2.10两节,笔记整理如下:
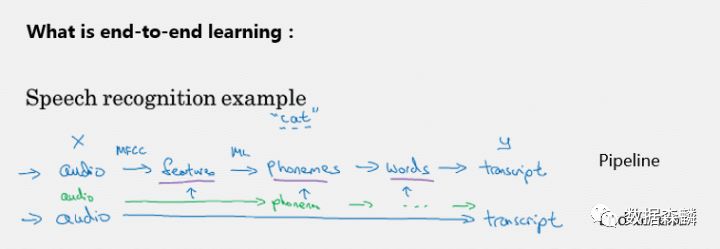

Andrew以Speech Recognition的场景为例,比较了pipeline和end-to-end两种建模方式中特征工程的差异。
其中pipeline的搭建依赖于人工设计的特征,需要依赖于人类可以理解的音节,将一段音频转化为文字;而end-to-end模型基于大量的音频素材,自动找出语音和文字间的关系,不依赖于音节而自动翻译成文字。
总而言之,除去语音和图像等特定场景,对于大部分生活中的机器学习项目,由于没有足够的训练数据支撑,我们还无法完全信任算法自动生成的特征,因而基于人工经验的特征工程依然是目前的主流。
人工经验这件事比较虚,加之许多业界的项目由于隐私性的考虑,很少会透露底层的入模特征和计算逻辑,使得目前网络上关于特征工程细节的文章少之又少。答主在这里结合自己这几年在金融领域的建模经验,介绍一些常见的数据源类型和特征计算方法,希望可以帮助刚入行或者想入行的从业者们开开脑洞。
(1)支付流水:通常包括支付账户、时间、金额、地点、目的、状态等字段,可以反映出客户的经济实力和消费习惯。其中特别的,账户间的复杂交易关系和异常金额时间地点的支付行为,都可以在反欺诈场景中应用,视为团伙作案或者反洗钱的重要指标。
(2)财富管理:基金理财类产品的申购历史记录,体现出客户的资金储备和购买偏好。对于风险偏好较低的客户,我们可以推荐小金库这类收益稳定、波动较小的债券类产品;对于追求高收益的客户,我们可以推荐在京东金融app上代销的各类基金,以及智能投顾产品。
(3)贷款信息:伴随着近几年国内现金贷以及场景贷市场的迅速发展,国家也在大力推动各家资方信贷数据的治理与共享。基于一个客户在各个平台上的贷款申请、提现、还款信息,可以刻画出这个客户的还款意愿和征信表现,从而为其下一次的信贷申请决策提供建议。常见的,多个平台申请和在贷以及当前有贷款发生90天以上逾期的用户,都会被其他平台列入自动拒绝的名单。
(4)App登录:从SDK埋点获取的各类app登录数据中,我们可以分析出用户在每个app上的停留时间,从而侧面了解这个用户的兴趣爱好,甚至预测用户的年龄和性别。例如京东、阿里等电商app登录较频繁的用户,通常以女性居多,并且消费能力较强;而抖音、快手等小视频app停留时间较长的,一般为年轻人群体。
(5)电商流水:从电商公司丰富的订单流水数据中,可以挖掘出较为完整的客户画像。客户Alice近一年内购买频繁,但是平均单笔订单金额较低,通常集中在生活用品以及水果生鲜,可以推断出Alice应该是一位家庭妇女;而客户Ben消费总金额较高,购买过车饰类产品,收货地址集中在办公场所,则大概率Ben是有车一族的白领青年。
(6)收货地址:在信贷风控场景中,通常近一年内地址数量较少、地址稳定性高的用户,贷款逾期风险更低;而对于地址变动频繁或者涉黑的用户,建议贷前申请直接拒绝,或者把这些收货地址运用到贷后催收之中。
(7)运营商信息:数据市场上比较常见的第三方数据源,可以用作各个场景下的身份证、姓名、手机号的三要素核验,以及利用在网时长和在网状态判断一个用户是否有欺诈风险。
除去上面整理的简单底层特征,在实际工作中数据分析师和算法工程师们还需要针对不同的业务场景,利用规则和模型构造一些复杂特征。
举两个实际的例子:
第一个例子,为了计算用户的年收入,可以利用近一年内支付总金额+理财总余额-信贷总负债的大公式,通过线性回归拟合出三个指标的系数,来得到每个用户预测的收入水平;
第二个例子,给自己在做的模型打个小广告,京东金融金融科技业务部基于京东集团商城、金融和物流三大自有数据源以及海量外部数据源,利用XGBoost、LightGBM、CatBoost等复杂集成树类算法,计算得到玉衡分特征,用来衡量京东客户在现金贷场景的信用等级,帮助服务的银行和小贷公司搭建信贷智能决策系统。
- 相关推荐
- 机器学习
-
【成都】招聘机器学习/数据挖掘/信号与信息处理工程师(可实习)2017-08-18 0
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 0
-
人工智能、机器学习、数据挖掘有什么区别2020-05-14 0
-
机器学习与数据挖掘方法和应用2023-09-26 0
-
机器学习与数据挖掘的关系2018-01-05 4345
-
《机器学习与数据挖掘:方法和应用》2018-06-27 783
-
代码实例及详细资料带你入门Python数据挖掘与机器学习2019-03-03 3373
-
机器学习特征工程的五个方面优点2020-03-15 3975
-
机器学习算法学习之特征工程32023-04-19 1028
-
机器学习与数据挖掘的对比与区别2023-08-17 1618
-
python数据挖掘与机器学习2023-08-17 1330
-
数据挖掘和机器学习有什么关系2023-08-17 2477
-
机器学习与数据挖掘的区别 机器学习与数据挖掘的关系2023-08-17 2090
-
机器学习中的数据预处理与特征工程2024-07-09 465
全部0条评论

快来发表一下你的评论吧 !
