

一个优秀的算法工程师必须具备哪些素质?
描述
导言
怎样成为一名优秀的算法工程师?这是很多从事人工智能学术研究和产品研发的同学都关心的一个问题。面对市场对人才的大量需求与供给的严重不足,以及高薪水的诱惑,越来越多的人开始学习这个方向的技术,或者打算向人工智能转型。市面上各种鱼龙混杂的培训班以及误导人的文章会把很多初学者带入歧途,浮躁的跟风将会让你最后收获甚微,根本达不到企业的用人要求。为了更好的帮助大家学习和成长,少走弯路,在今天的文章里,SIGAI的作者以自己的亲身经历和思考,为大家写下对这一问题的理解与答案。
首先来看一个高度相关的问题:一个优秀的算法工程师必须具备哪些素质?我们给出的答案是这样的:
数学知识
编程能力
机器学习与深度学习的知识
应用方向的知识
对自己所做的问题的思考和经验
除去教育背景,逻辑思维,学习能力,沟通能力等其他方面的因素,大多数公司在考察算法工程师的技术水平时都会考虑上面这几个因素。接下来我们将按照这几个方面进行展开,详细的说明如何学习这些方面的知识以及积累经验。
数学知识
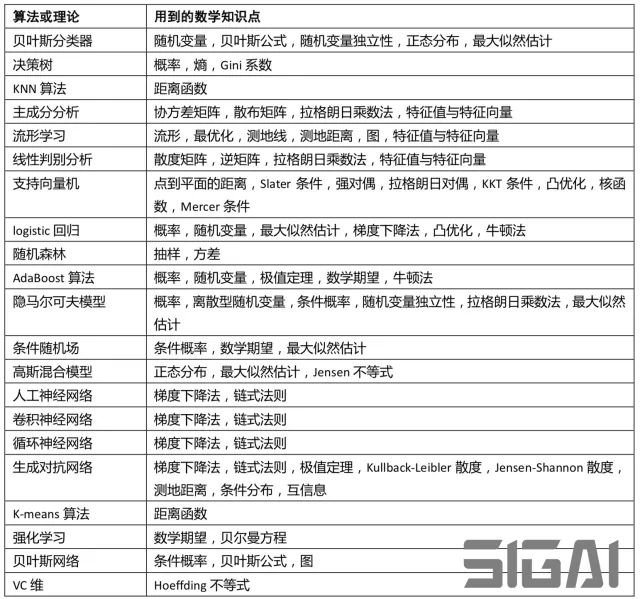
与其他工作方向如app、服务器开发相比,以及与计算机科学的其他方向如网络,数据库,分布式计算等相比,人工智能尤其是机器学习属于数学知识密集的方向。在各种书籍,论文,算法中都充斥着大量的数学公式,这让很多打算入门的人或者开始学习的人感到明显的压力。首先我们考虑一个最核心的问题:机器学习和深度学习究竟需要哪些数学知识?在SIGAI之前的公众号文章“学好机器学习需要哪些数学知识”里,我们已经给出了答案。先看下面这张表:
更多算法工程师的必读文章,请关注SIGAICN公众号
上面的表给出了各种典型的机器学习算法所用到的数学知识点。我们之前已经总结过,理解绝大多数算法和理论,有微积分/高等数学,线性代数,概率论,最优化方法的知识就够了。除流形学习需要简单的微分几何概念之外,深层次的数学知识如实变函数,泛函分析等主要用在一些基础理论结果的证明上,即使不能看懂证明过程,也不影响我们使用具体的机器学习算法。概率图模型、流形学习中基于图的模型会用到图论的一些基本知识,如果学习过离散数学或者数据结构,这些概念很容易理解。除此之外,某些算法会用到离散数学中的树的概念,但很容易理解。
如果你已经学过这些大学数学课,只要把所需的知识点复习一遍就够了。对于微积分,通俗易懂而又被广为采用的是同济版的高等数学:
在机器学习中主要用到了微分部分,积分用的非常少。具体的,用到了下面的概念:
导数和偏导数的定义与计算方法,与函数性质的关系
梯度向量的定义
极值定理,可导函数在极值点处导数或梯度必须为0
雅克比矩阵,这是向量到向量映射函数的偏导数构成的矩阵,在求导推导中会用到
Hessian矩阵,这是2阶导数对多元函数的推广,与函数的极值有密切的联系
凸函数的定义与判断方法
泰勒展开公式
拉格朗日乘数法,用于求解带等式约束的极值问题
其中最核心的是多元函数的泰勒展开公式,根据它我们可以推导出梯度下降法,牛顿法,拟牛顿法等一系列最优化方法。
如果你想要深入的学习微积分,可以阅读数学系的教程,称为数学分析:
与工科的高等数学偏重计算不同,它里面有大量的理论证明,对于锻炼数学思维非常有帮助。北大张筑生先生所著的数学分析可谓是国内这方面教材的精品。
下面来看线性代数,同样是同济版的教材:
如果想更全面系统的学习线性代数,可以看这本书:
相比之下,线性代数用的更多。具体用到的知识点有:
向量和它的各种运算,包括加法,减法,数乘,转置,内积
向量和矩阵的范数,L1范数和L2范数
矩阵和它的各种运算,包括加法,减法,乘法,数乘
逆矩阵的定义与性质
行列式的定义与计算方法
二次型的定义
矩阵的正定性
特征值与特征向量
奇异值分解
线性方程组的数值解
机器学习算法处理的数据一般都是向量、矩阵或者张量。经典的机器学习算法输入的数据都是特征向量,深度学习算法在处理图像时输入的2维的矩阵或者3维的张量。掌握这些概念是你理解机器学习和深度学习算法的基础。
概率论国内理工科专业使用最多的是浙大版的教材:
如果把机器学习所处理的样本数据看作随机变量/向量,就可以用概率论的方法对问题进行建模,这代表了机器学习中很大一类方法。在机器学习里用到的概率论知识点有:
随机事件的概念,概率的定义与计算方法
随机变量与概率分布,尤其是连续型随机变量的概率密度函数和分布函数
条件概率与贝叶斯公式
常用的概率分布,包括正态分布,伯努利二项分布,均匀分布
随机变量的均值与方差,协方差
随机变量的独立性
最大似然估计
这些知识不超出普通理工科概率论教材的范围。
最后来说最优化,几乎所有机器学习算法归根到底都是在求解最优化问题。求解最优化问题的指导思想是在极值点出函数的导数/梯度必须为0。因此你必须理解梯度下降法,牛顿法这两种常用的算法,它们的迭代公式都可以从泰勒展开公式而得到。
凸优化是机器学习中经常会提及的一个概念,这是一类特殊的优化问题,它的优化变量的可行域是凸集,目标函数是凸函数。凸优化最好的性质是它的所有局部最优解就是全局最优解,因此求解时不会陷入局部最优解。如果一个问题被证明为是凸优化问题,基本上已经宣告此问题得到了解决。在机器学习中,线性回归、岭回归、支持向量机、logistic回归等很多算法求解的都是凸优化问题。
拉格朗日对偶为带等式和不等式约束条件的优化问题构造拉格朗日函数,将其变为原问题,这两个问题是等价的。通过这一步变换,将带约束条件的问题转换成不带约束条件的问题。通过变换原始优化变量和拉格朗日乘子的优化次序,进一步将原问题转换为对偶问题,如果满足某种条件,原问题和对偶问题是等价的。这种方法的意义在于可以将一个不易于求解的问题转换成更容易求解的问题。在支持向量机中有拉格朗日对偶的应用。
KKT条件是拉格朗日乘数法对带不等式约束问题的推广,它给出了带等式和不等式约束的优化问题在极值点处所必须满足的条件。在支持向量机中也有它的应用。
如果你没有学过最优化方法这门课也不用担心,这些方法根据微积分和线性代数的基础知识可以很容易推导出来。如果需要系统的学习这方面的知识,可以阅读《凸优化》,《非线性规划》两本经典教材。
编程能力
编程能力是学好机器学习和深度学习的又一大基础。对于计算机类专业的学生,由于本科已经学了c语言,c++,数据结构与算法,因此这方面一般不存在问题。对于非计算机专业的人来说,要真正学好机器学习和深度学习,这些知识是绕不开的。
虽然现在大家热衷于学习python,但要作为一名真正的算法工程师,还是应该好好学习一下c++,至少,机器学习和深度学习的很多底层开源库都是用它写的;很多公司线上的产品,无论是运行在服务器端,还是嵌入式端,都是用c++写的。此外,如果你是应届生,在校园招聘时不少公司都会面试你c++的知识。
C++最经典的教材无疑是c++ primer:
对做算法的人来说,这本书其实不用全部看,把常用的点学完就够了。对于进阶,Effective c++是很好的选择,不少公司的面试题就直接出自这本书的知识点:
接下来说python,相比c++来说,学习的门槛要低很多,找一本通俗易懂的入门教程学习一遍即可。
数据结构和算法是编写很多程序的基础,对于机器学习和深度学习程序也不例外。很多算法的实现都依赖于数组,链表,数,排序,查找之类的数据结构和基础算法。如果有时间和精力,把算法导论啃一遍,你会有不一样的感受:
对于应届生来说,学完它对于你通过大互联网和人工智能公司校园招聘的技术面试也非常有用。
上面说的只是编程语言的程序设计的理论知识,我们还要考虑实际动手能力。对于开发环境如gcc/g++,visual studio之类的工具,以及gdb之类的调试工具需要做到熟练使用。如果是在linux上开发,对linux的常用命令也要熟记于心。这方面的知识看各种具体的知识点和教程即可。另外,对于编程的一些常识,如进程,线程,虚拟内存,文件系统等,你最好也要进行了解。
机器学习与深度学习
在说完了数学和编程基础之后,下面我来看核心的内容,机器学习和深度学习知识。机器学习是现阶段解决很多人工智能问题的核心方法,尤其是深度学习,因此它们是算法工程师的核心知识。在这里有一个问题:是否需要先学机器学习,还是直接学深度学习?如果是一个专业的算法工程师,我的建议是先学机器学习。至少,你要知道机器学习中的基本概念, 过拟合,生成模型,ROC曲线等,上来就看深度学习,如没有背景知识你将不知所云。另外,神经网络只是机器学习中的一类方法,对于很多问题,其他机器学习算法如logistic回归,随机森林,GBDT,决策树等还在被大规模使用,因此你不要把自己局限在神经网络的小圈子里。
首先来看机器学习,这方面的教材很多,周志华老师的机器学习,李航老师的统计学习方法是国内的经典。这里我们介绍国外的经典教材,首先是PRML:
此书深厚,内容全面,涵盖了有监督学习,无监督学习的主要方法,理论推导和证明详细深入,是机器学习的经典。此外还有模式分类这本书,在这里不详细介绍。
深度学习目前最权威的教程是下面这本书:
它涵盖了深度学习的方方面面,从理论到工程,但美中不足的是对应于介绍的相对较少。
强化学习是机器学习很独特的一个分支,大多数人对它不太了解,这方面的教程非常少,我们推荐下面这本书:
美中不足的是这本书对深度强化学习没有介绍,因为出版的较早。不知最新的版本有没有加上这方面的内容。
在这里需要强调的是,你的知识要系统化,有整体感。很多同学都感觉到自己学的机器学习太零散,缺乏整体感。这需要你多思考算法之间的关系,演化历史之类的问题,这样你就做到胸中有图-机器学习算法地图。其实,SIGAI在之前的公众号文章“机器学习算法地图”里已经给你总结出来了。
开源库
上面介绍了机器学习和深度学习的理论教材,下面来说实践问题。我们无需重复造车轮子,熟练的使用主流的开源库是需要掌握的一项技能。对于经典的机器学习,常用的库的有:
libsvm
liblinear
XGBoost
OpenCV
HTK
Weka
在这里我们不一一列举。借助于这些库,我们可以方便的完成自己的实验,或是研发自己的产品。对于深度学习,目前常用的有:
Caffe
TensorFlow
MXNet
除此之外,还有其他的。对于你要用到的开源库,一定要理解它的原理,以及使用中的一些细节问题。例如很多算法要求输入的数据先做归一化,否则效果会非常差,而且面临浮点数溢出的问题,这些实际经验需要你在使用中摸索。如果有精力把这些库的核心代码分析一遍,你对实现机器学习算法将会更有底气。以深度学习为例,最核心的代码无非是实现:
各种层,包括它们的正向传播和反向传播
激活函数的实现
损失函数的实现
输入数据的处理
求解器,实现各种梯度下降法
这些代码的量并不大,沉下心来,我相信一周之内肯定能分析完。看完之后你会有一种豁然开朗的感觉。
应用方向的知识
接下来是各个方向的知识,与机器学习有关的应用方向当前主要有:
机器视觉
语音识别
自然语言处理
数据挖掘
知识图谱
推荐系统
除此之外,还有其他一些特定小方向,在这里不一一列举。这些具体的应用方向一般都有自己的教材,如果你以后要从事此方向的研究,系统的学习一遍是必须的。
实践经验与思考
在说完理论与实践知识之后,最后我们来说经验与思考。在你确定要做某一个方向之后,对这个方向的方法要有一个全面系统的认识,很多方法是一脉相承的,如果只追求时髦看最新的算法,你很难做出学术上的创新,以及工程上的优化。对于本问题所有的经典论文,都应该化时间细度,清楚的理解它们解决了什么问题,是怎么解决的,还有哪些问题没有解决。例如:
机器视觉目标检测中的遮挡问题
推荐系统中的冷启动问题
自然语言处理中文分词中的歧义切分问题
只有经过大量的编程和实验训练,以及持续的思考,你才能算得上对这个方向深刻理解,以至于有自己的理解。很多同学对自己实现轮上的算法没有底气,解决这个问题最快的途径就是看论文算法的开源代码,在github上有丰富的资源,选择一些合适的,研究一下别人是怎么实现的,你就能明白怎么实现自己的网络结构和损失函数,照葫芦画瓢即可。
计算机以及人工智能是一个偏实践的学科,它的方法和理论既需要我们有扎实的理论功底,又需要有丰富的实践能力与经验。这两个方面构成了算法工程师最主要的素质。科学的学习路径能够让你取得好的学习效果,同时也缩短学习时间。错误和浮躁的做法则会让你最后事倍功半。这是SIGAI对想进入这个领域,或者刚进入这个领域的每个人要说的!
-
想去粤嵌教育成为一名优秀的嵌入式工程师应该具备什么样的技能呢?2017-06-05 0
-
一个优秀的硬件工程师要具备的能力2018-10-16 0
-
EMC工程师需要具备哪些技能?2019-05-30 0
-
EMC工程师必须具备的八大技能2011-01-13 1950
-
电磁兼容EMC工程师必须具备技能2011-11-23 3047
-
如何成为一个优秀的电子工程师2016-08-05 694
-
前端工程师应具备那些基本素质2018-09-20 4559
-
一名优秀的全栈工程师应当具备哪些素质?2018-08-13 2932
-
一名优秀的软件开发工程师应该具备那些素质?2018-08-20 13351
-
NET工程师应具备的基本素质有哪些2018-09-27 5001
-
成为合格的售前工程师需要具备哪些技能及素质2019-04-12 27772
-
一名优秀的性能工程师需要哪些素质2019-07-16 3369
-
如何成为一个算法工程师2019-07-29 5731
-
如何成为一名优秀的Linux工程师2019-08-21 3288
全部0条评论

快来发表一下你的评论吧 !
