

CDN日志实时分析
今日头条
描述
摘要: CDN是互联网网站、应用上极其重要的基础设施,通过CDN可有效降低访问延时、提升体验有很大帮助,也有助于源站降低负载,容应对流量高峰,保证服务的稳定。CDN日志可实时导入日志服务,基于日志服务灵活、快捷的统计分析能力,用户对于CDN的数据分析将变得极其简单和方便。
CDN(Content Delivery Network),内容分发网络)是互联网网站、应用上极其重要的基础设施,通过CDN,终端用户可直接从边缘节点访问各种图片、视频资源,避免直接访问源站。这对于降低访问延时、提升体验有很大帮助,也有助于源站降低负载,容应对流量高峰,保证服务的稳定。在(短)视频、直播等对网络流量很大需求的领域,CDN作用尤其重要。
CDN对于网站、应用如此重要,对于CDN访问的统计分析必不可少,先看一下以下几个场景:
当前服务状态是否正常
访问PV、UV是否有波动
带宽、访问延时是否正常
缓存命中率,访问健康度如何
有人反馈服务访问异常
异常来源是否有地域特性
是否和运营商有关
错误访问和终端应用版本是否有关联
流量上涨
是正常访问还是攻击
哪些是热点资源
是否有异常客户
是否由于客户端缓存策略导致
用户行为分析
当前在线人数、访问次数
热门资源
访问来源、agent、分布等
传统分析流程
现在各家CDN厂商,通常会提供基础的监控指标,比如请求次数、带宽等信息,然后,在进行定制化分析场景下,默认指标往往不能解决所有问题,需要对原始日志进行更深入的挖掘。以下是常见的处理方式:
定期下载CDN离线日志
将数据导入Hadoop 这样的数仓系统
跑各类job(或hive)对数据进行分析,将最终结果导入Mysql
对分析结果进行实时展示
对于报表场景,以上流程没有太大问题,可以处理海量CDN的日志,但是在实时问题定位,快速验证、试错等交互式分析强烈的场景下, 该方案的弊端就显露出来:
离线模式下,数据产出实时性无法保证,延时从半小时到几小时不等
需要维护多级Pipeline,需要有脚本或工具将其串联,有开发代价
环境维护,有运维代价,任意一个环节出问题,结果都不能产出
灵活性欠佳,无法快速响应实时交互查询需求
针对这种情况, 阿里云CDN和日志服务进行了打通,CDN日志可实时导入日志服务,使用SLS的查询和SQL分析能力,来满足用户个性化、实时、交互式的分析需求:
CDN的访问日志,1分钟内可投递至日志服务
直接在日志服务控制台进行SQL查询,无需任何代码维护
秒级查询分析1亿~10亿数据
使用日志服务的Dashboard功能,制定灵活的报表
接下来,对于CDN数据各类分析需求,看看如何在日志服务上实现。在这之前,我们先看一下CDN主要的字段说明。
CDN日志格式说明
字段名字类型说明client_iptext客户端ipcontent_typetext数据类型domaintext域名hit_infotext缓存命中信息 HIT 或者 MISSmethodtext请求方法refer_domaintext请求来源域名refer_paramtext请求来源url 参数refer_uritext请求来源uriremote_iptextremote ipremote_portlongremote 端口request_sizelong请求输入大小,单位byterequest_timelong响应延时,单位毫秒response_sizelong请求返回大小,单位bytereturn_codelonghttp 状态码schemetext请求协议, 如httpuritext请求uriuri_paramtext请求参数user_agenttext请求Agent信息uuidtext标识请求的唯一idxforwordfortextforword ip 地址CDN质量和性能分析
CDN提供日志中,包含了丰富的内容,我们可以从多个维度对CDN的整体质量和性能进行全方位的统计和分析
健康度
统计return_code小于500的请求占所有请求的百分比
* | select sum(s) * 100.0/count(*) as health_ratio from (select case when return_code < 500 then 1 else 0 end as s from log)
缓存命中率
统计return_code小于400的请求中, hit_info 为 HIT的请求百分比
return_code < 400 | select sum(s) * 100.0/count(*) as Hit_ratio from (select case when hit_info = 'HIT' then 1 else 0 end as s from log)
平均下载速度
统计一段时间内,总体下载量除以整体耗时获得平均下载速度
* | select sum(response_size) * 1.0 /sum(request_time)
访问次数Top域名
按照访问域名次数进行Top排序
* | select Domain , count(*) as count group by Domain order by count desc limit 100
下载流量Top域名
按照各个域名下载数据量大小进行Top排序
* | select Domain , sum(response_size) as "下载总量" group by Domain order by "下载总量" desc limit 100
接下来,我们从省份和运营商的角度,来做实时统计:
各省访问次数、下载流量、速度
使用ip_to_province函数,将client_ip转化成对应的省份,统计各个省份的访问次数,下载的总量,以及下载平均速度
* | select ip_to_province(client_ip) as province ,count(*) as "访问次数", sum(response_size)/1024.0/1024.0/1024.0 as "下载流量(GB)" , sum(response_size) * 1.0 /sum(request_time) as "下载速度(KB/s)" group by province having ip_to_province(client_ip) != '' order by "下载流量(GB)" desc limit 200
运营商的下载次数、下载流量、速度
原理同上,使用ip_to_provider函数,将client_ip转化成对应的运营商
* | select ip_to_provider(client_ip) as isp ,count(*) as "访问次数", sum(response_size)/1024.0/1024.0/1024.0 as "下载流量(GB)" , sum(response_size) * 1.0 /sum(request_time) as "下载速度(KB/s)" group by isp having ip_to_provider(client_ip) != '' order by "下载流量(GB)" desc limit 200
请求响应延时
将访问延时按照各窗口进行统计,可根据应用实际的情况来划分合适的延时时间窗口
* | select case when request_time < 50 then '~50ms' when request_time < 100 then '50~100ms' when request_time < 200 then '100~200ms' when request_time < 500 then '200~500ms' when request_time < 5000 then '500~5000ms' else '5000ms~' end as latency , count(*) as count group by latency
访问PV、UV统计
统计每分钟内,访问次数和独立的client ip数
* | select date_format (from_unixtime(__time__ - __time__ % 60), '%H:%i') as date , count(*) as pv, approx_distinct(client_ip) as uv group by __time__ - __time__ % 60 order by __time__ - __time__ % 60
数据流量类型分布
统计各数据类型的访问分布
* | select content_type , sum(response_size) as sum_res group by content_type order by sum_res desc limit 10
CDN错误诊断
访问错误一直是影响服务体验的重要一环,当出现错误的时候,需要快速定位当前错误QPS和比例是多少,哪些域名和URI影响最大,是否和地域、运营商有关,是不是发布的新版本导致。
4xx、5xx错误百分比和分布
根据return_code的值,将错误分为4xx和5xx两类,从下面的错误百分比和分布图来看,主要的错误都是发生了403错误,说明被服务器拒绝请求,这个时候就需要检查是不是资源使用超过限制。
* | select date_format (from_unixtime(m_time), '%H:%i') as date, sum( ct ) * 100.0/max(total) as error_ratio , case when return_code/100 < 5 then '4xx' else '5xx' end as code from (select m_time, return_code, ct, (sum(ct) over(partition by m_time) ) as total from (select __time__ - __time__ % 60 as m_time, return_code , count(*) as ct from log group by m_time, return_code) ) group by m_time, return_code/100 having(return_code/100 >= 4) order by m_time limit 100000
return_code >= 400 | select return_code , count(*) as c group by return_code order by c desc
错误Top域名和Uri
对于return_code > 400的请求,按照域名和uri的维度进行top 排序
return_code > 400| select domain , count(*) as c group by domain order by c desc limit 10
return_code > 400| select uri , count(*) as c group by uri order by c desc limit 10
运营商和各省错误统计
return_code > 400 | select ip_to_provider(client_ip) as isp , count(*) as c group by isp having ip_to_provider(client_ip) != '' order by c desc limit 10
return_code > 400 | select ip_to_province(client_ip) as province , count(*) as c group by province order by c desc limit 50
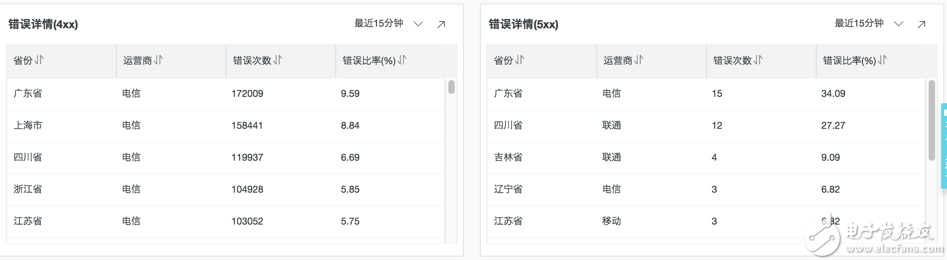
错误详情
对于错误数据,我们还可以从省份、运营商组合的角度来查看错误的次数和百分比。
return_code >= 400 and return_code < 500 | select province as "省份", isp as "运营商", c as "错误次数", round(c * 100.0/ sum(c) over(), 2) as "错误比率(%)" from (select ip_to_province(client_ip) as province , ip_to_provider(client_ip) as isp , count(*) as c from log group by province, isp having(ip_to_provider(client_ip)) != '' order by c desc)
return_code >= 500 | select province as "省份", isp as "运营商", c as "错误次数", round(c * 100.0/ sum(c) over(), 2) as "错误比率(%)" from (select ip_to_province(client_ip) as province , ip_to_provider(client_ip) as isp , count(*) as c from log group by province, isp having(ip_to_provider(client_ip)) != '' order by c desc)
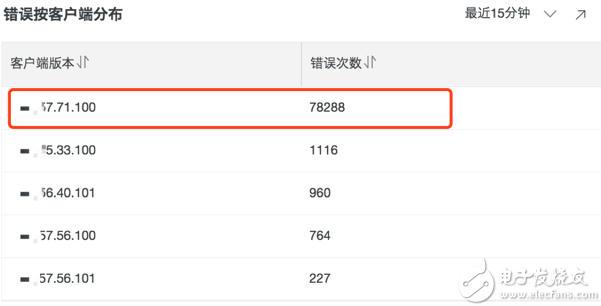
客户端分布
很多时候,错误的发生是由于新的版本发布引入的bug,下图中的例子,可以看到大部分错误都是出现在新发布的版本上,有这个维度的信息后,问题调查的范围可以大大缩小
return_code > 400 | select user_agent as "客户端版本", count(*) as "错误次数" group by user_agent order by "错误次数" desc limit 10
用户行为分析
基于CDN的访问日志,我们也可以对用户的访问行为进行分析, 如:
大部分用户是从哪里过来,是内部还是外部
哪些资源用户是热门资源
是否有用户在疯狂下载资源,行为是否符合预期
针对这些问题,我们举例来说明,用户也可以根据自己的业务场景进行定制化的分析
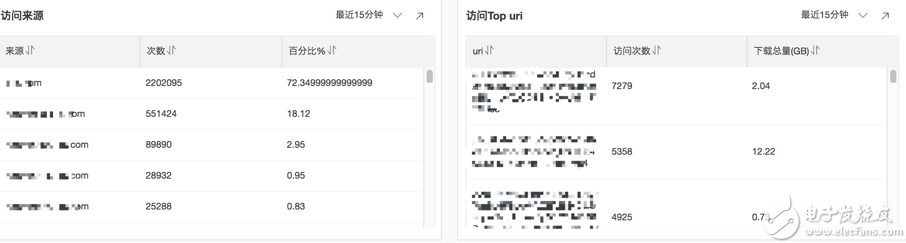
访问来源统计
not refer_domain:"" | select refer_domain as "来源", c as "次数" , round(c * 100.0/(sum(c) over()) , 2) as "百分比%" from ( select refer_domain as refer_domain , count(*) as c from log group by refer_domain order by c desc limit 100 )
访问Top uri
return_code < 400 | select uri ,count(*) as "访问次数", round(sum(response_size)/1024.0/1024.0/1024.0, 2) as "下载总量(GB)" group by uri order by "访问次数" desc limit 100
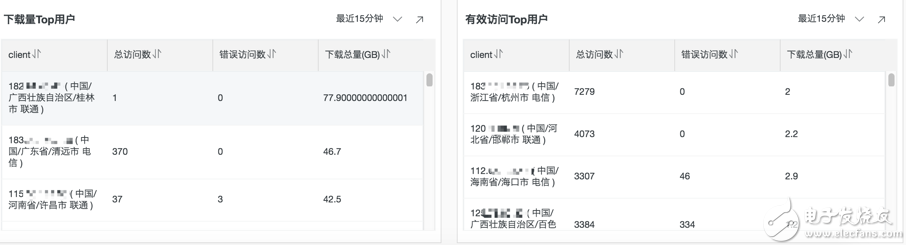
Top用户统计
* | SELECT CASE WHEN ip_to_country(client_ip)='香港' THEN concat(client_ip, ' ( Hong Kong )') WHEN ip_to_province(client_ip)='' THEN concat(client_ip, ' ( Unknown IP )') WHEN ip_to_provider(client_ip)='内网IP' THEN concat(client_ip, ' ( Private IP )') ELSE concat(client_ip, ' ( ', ip_to_country(client_ip), '/', ip_to_province(client_ip), '/', if(ip_to_city(client_ip)='-1', 'Unknown city', ip_to_city(client_ip)), ' ',ip_to_provider(client_ip), ' )') END AS client, pv as "总访问数", error_count as "错误访问数" , throughput as "下载总量(GB)" from (select client_ip , count(*) as pv, round(sum(response_size)/1024.0/1024/1024.0, 1) AS throughput , sum(if(return_code > 400, 1, 0)) AS error_count from log group by client_ip order by throughput desc limit 100)
* | SELECT CASE WHEN ip_to_country(client_ip)='香港' THEN concat(client_ip, ' ( Hong Kong )') WHEN ip_to_province(client_ip)='' THEN concat(client_ip, ' ( Unknown IP )') WHEN ip_to_provider(client_ip)='内网IP' THEN concat(client_ip, ' ( Private IP )') ELSE concat(client_ip, ' ( ', ip_to_country(client_ip), '/', ip_to_province(client_ip), '/', if(ip_to_city(client_ip)='-1', 'Unknown city', ip_to_city(client_ip)), ' ',ip_to_provider(client_ip), ' )') END AS client, pv as "总访问数", (pv - success_count) as "错误访问数" , throughput as "下载总量(GB)" from (select client_ip , count(*) as pv, round(sum(response_size)/1024.0/1024/1024.0, 1) AS throughput , sum(if(return_code < 400, 1, 0)) AS success_count from log group by client_ip order by success_count desc limit 100)
后续
阿里云CDN和日志服务打通之后,依托CDN强大的数据分发能力,和日志服务灵活、快捷的统计分析能力,用户对于CDN的数据分析将变得极其简单和方便。现在CDN底层日志已经能导入日志服务,产品上的打通也在进行中,预计8月份用户可以直接在CDN控制台上开通使用。
本文为云栖社区原创内容,未经允许不得转载。
-
怎么使用Go重构流式日志网关呢?2023-06-18 1144
-
如何用FPGA动态探头与数字VSA对DSP进行实时分析?2021-05-10 1496
-
大数据实时分析领域的ClickHouse2020-03-24 2288
-
作为互联网流量入口,CDN日志大数据你该怎么玩?2018-12-21 373
-
英特尔图形性能分析器(GPA)中的实时分析工具介绍2018-11-07 6135
-
谷歌将摄像头实时分析功能整合至Pixel3中2018-09-30 3380
-
阿里云DDoS高防 - 访问与攻击日志实时分析(三)2018-07-11 1951
-
如何利用边缘运算挖掘IoT实时分析潜力2018-01-31 1699
-
飞流大规模日志数据实时多维统计分析平台2017-11-30 1126
-
设计基于FPGA实现的ARINC659总线的系统实时分析仪2017-11-16 10444
-
【TL6748 DSP申请】噪声实时分析系统2015-10-29 2094
-
用FPGA动态探头与数字VSA对DSP设计实时分析2010-01-07 938
-
实时分析技术和测量给无线通信带来的好处2009-11-02 694
全部0条评论

快来发表一下你的评论吧 !
