

北大研究者创建了一种注意力生成对抗网络
电子说
描述
编者按:下雨时拍照总有种朦胧的美感,但是附着在相机、窗户上的水滴会降低背景的能见度,让照片模糊不清。为了去除照片上的水滴,北京大学计算机科学与技术研究院的研究人员创建了一种注意力生成对抗网络,效果不错。以下是论智对论文的编译。
下雨时拍出的照片模糊是由于雨滴覆盖的区域和没有雨滴的区域图像内容不同,同时,雨滴的形状是球形,光线经过折射会变成“鱼眼”效果,让宽广的景色浓缩到一点。另外,在大多数情况中,相机的焦点都在背景上,所以会让前景中的雨滴变得模糊。
在这篇文章中,我们解决了这一问题。给定一张有雨水的照片,我们的目标是让其变得清晰。大致效果如图1所示。
图1
我们的方法是完全自动的,相信这能为图像处理和计算机视觉的应用提供帮助,尤其是处理相似的问题,例如去除照片上的污渍等。
遇到的困难
通常来说,去除水滴的问题比较棘手。因为首先我们不知道被雨水遮盖的区域原本的图像(本文是根据单张图片进行还原,没有对照图片)。另外,遮挡区域背景的信息我们也无从得知。如果雨滴较大、分布得更密集,问题就更加麻烦。为了解决这个问题,我们选择了生成对抗网络。
雨水是透明的,但是由于它们特殊的形状和光的折射,雨滴中一个像素区域就会受到整个环境的影响,所以使得这个雨滴和它的背景有很大的差别。在雨滴的某些区域,尤其是边缘和透明的地方,通常会传达有关背景的信息。我们发现这些信息可以通过分析用在网络中。
我们将含有雨滴的模糊图像用以下等式表示:
其中I表示输入图片,M表示二进制掩码。在该掩码中,M(x)=1意味着像素x是雨滴的一部分,否则该像素就是背景的一部分。B是背景图像,R是雨滴带来的影响,表示复杂的背景信息和光折射产生的现象。⊙表示各种元素相乘。
网络结构
图2展示了我们所提出的网络结构:
图2
其中,生成对抗损失可以表示成:
G表示生成网络,D表示判别网络,I是含有雨滴的样本图片,之后会输入到生成网络中,R是未经污染的自然图像。
为了处理这个复杂的问题,我们的生成网络首先会生成一个注意力地图,这是整个网络最重要的部分,因为它将指导网络下一步该关注哪些区域。该地图由一个包含深度ResNet的循环网络生成,同时结合了卷积LSTM和几个标准卷积层,我们将其称为注意力循环网络。
图3展示了在训练过程中,我们的网络是如何生成注意力地图的。可以看到,我们的网络不仅在确定雨滴的区域而且还要找出周围环境的结构。
图3
生成网络的第二部分是一个自动编码器,语境自动编码器的目的是生成一张没有雨滴的图片,输入的照片和注意力地图会同时输入到该编码器中。我们的深度自动编码器有16个conv-relu模块,同时还添加了跳跃式连接以防止输出模糊的图像。语境自动编码器的结构如图4所示。
图4
为了获得更多语境信息,我们在自动编码器的解码器一端添加了多尺度的损失。每个损失都比较了卷积层的输出和对应的标准之间的差异。卷积层的输入是解码层的特征。除了这些损失,我们还在自动编码器的最终输出上应用了一个感知损失,让其更接近真实场景。这个最终的输出也是生成网络的输出。
之后,判别网络就会检查上述输出是否真实。和其他去水印、去障碍物的方法类似,我们的判别网络会从局部和全局来进行检查。唯一不同的是,在我们的问题中,尤其在测试阶段,有雨滴的目标区域并不会给出。因此,判别网络无法关注局部区域,因为没有可用信息。为了解决这一问题,我们用注意力地图来引导判别网络识别需要处理的局部区域。
实验结果
表1展示了我们的方法和目前的Eigen13和Pix2Pix之间的对比:
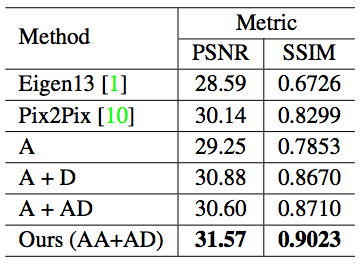
表1
与其他两种方法相比,我们的方法PSNR和SSIM分数都比较高,这说明我们的方法生成的结果更接近于真实场景。
同时我们还将完整的GAN结构和我们网络的部分相对比:A表示只有自动编码器,没有注意力地图;A+D表示没有注意力自动编码器,也没有注意力判别器;A+AD表示没有注意力自动编码器,但是有注意力判别器;AA+AD表示既有注意力自动编码器也有注意力判别器。可以看出,AA+AD表现得比其他方法要好。
反映在图像上,如图6和图7所示:
图6
图7
近距离观察:
用Google Vision API对我们的方法进行测试,结果如下:
可以看到谷歌的这款工具在经过处理后的图像上能更好地识别出场景中的物体。
-
图像生成对抗生成网络2021-09-15 0
-
生成对抗网络在计算机视觉领域有什么应用2018-12-06 1478
-
如何使用生成对抗网络进行信息隐藏方案资料说明2018-12-12 1135
-
生成对抗网络与其他生成模型之间的权衡取舍是什么?2019-04-29 3980
-
循环神经网络卷积神经网络注意力文本生成变换器编码器序列表征2019-07-19 3365
-
基于谱归一化条件生成对抗网络的图像修复算法2021-03-12 854
-
基于自注意力机制的条件生成对抗网络模型2021-04-20 1180
-
基于密集卷积生成对抗网络的图像修复方法2021-05-13 799
-
基于结构保持生成对抗网络的图像去噪2021-06-07 691
-
基于像素级生成对抗网络的图像彩色化模型2021-06-27 622
-
一种基于生成对抗网络的无人机图像去雾算法2022-03-10 1752
-
一种新的深度注意力算法2023-05-24 269
-
PyTorch教程20.2之深度卷积生成对抗网络2023-06-05 467
-
生成对抗网络(GANs)的原理与应用案例2024-07-09 1643
全部0条评论

快来发表一下你的评论吧 !
