

multi-tap的FlexHtree自动化时钟树综合流程
电子说
描述
对于高性能CPU设计,特别是在16 nm以及更高级的工艺节点上,signoff的corner很多,增加公共时钟路径长度、改善各RC端角下时钟延迟的一致性、降低设计的局部时钟偏斜已经成为数字后端设计师的共识。Cadence innovus工具新增的multi-tap FlexHtree结构时钟树方案不仅提供了H-tree对称的时钟缓冲器单元结构和相等的线长特点,而且其对几何对称性降低了要求,确保了时序单元摆放完毕后就可以进行时钟树综合。建立了一个自动化的FlexHtree实现流程来降低不同corner下的时钟偏斜。详细讨论了FlexHtree tap点的数量以及子树时钟综合引擎对时钟偏斜和设计时序的影响,进而找到了一个较好的FlexHtree实现方案。最后从时序、功耗和单元数量等方面对FlexHtree、CCOPT和鱼骨型Fishbone结构时钟树进行了较为全面的比较,从而得出该设计更适合采用灵活的FlexHtree结构。
0 引言
现代高性能处理器对数据传输和数据处理需求越来越高,时钟树作为处理器时钟信号传递的载体,对整个处理器的计算性能有着直接的影响。要想在低时钟偏差(clock skew)的要求下将时钟信号分配到各个局部区域在高性能系统中变得极富挑战。
时钟结构主要分为两种:树形结构与网状结构。树形结构设计比较成熟,以Cadence innovusCCOPT为典型代表,EDA工具能够根据指定的约束条件自动生成时钟树,并且可以选择平衡树还是借用有用偏差(useful skew)的不平衡树,树形结构广泛应用于手机和物联网等芯片设计中;而网状型时钟结构需要大量的手工工作,并经过大量的尝试调整之后才能体现出优势,其见诸于高性能计算芯片中。
数字同步逻辑电路时钟树实现方案的合理选择才能使得CPU的高性能不是浮云。例如,网状型(Mesh)、鱼骨型(Fishbone)时钟结构作为Intel和IBM CPU处理器惯常采用的结构,其共同特点是时钟传播延时(latency)、时钟偏斜(skew)、片上偏差(OCV)都很低。Mesh结构的缺点是功耗(power)偏大、布线资源开销大,而鱼骨型结构由于子树手工划分比较难,手工操作比较多。目前以Flexible H-tree(缩写为FlexHtree)结构为代表的时钟树近年来广泛应用于ARM架构处理器,其特点是使用灵活、功耗低、各工艺端角(corner)下时钟偏差比较小。
本文将以带多末梢点(multi-tap)的FlexHtree作为研究对象,尝试在降低clock skew的同时不对建立时序(setup)和功耗带来明显的影响。本文的设计结果给高性能CPU的时钟树设计提供了一个较优的解决方案,同时对目前自主高性能芯片的后端物理实现提供了工程参考。
1 Multi-tap FlexHtree和Fishbone时钟结构介绍
以高性能CPU为研究对象,本文主要讨论和对比两种时钟结构,multi-tap FlexHtree和Fishbone,以下将从结构及特点方面对两种结构进行简单描述。
1.1 带multi-tap的H-tree时钟树结构
传统单一的H-tree多用于Mesh、Fishbone时钟结构的前级驱动,或者部分对clock skew有要求的电路结构进行时钟的平衡。图1中所示带multi-tap点的H-tree的结构可以与时钟树综合(CTS)相结合来控制整个时钟树的clock skew[1]。时钟根节点(root pin)可以是时钟输入端口,也可以是时钟缓冲器,借助H-tree将时钟信号传递到各个叶节点(sink)。最上面7个驱动器组成了H-tree的“H”形结构,当tap点比较多时可以采用多级的H-tree网络实现tap点之间的多工艺端角(multi-corner)下时钟延迟的平衡。最后一级驱动器为子树的根节点,该子树可以使用普通的CTS完成。
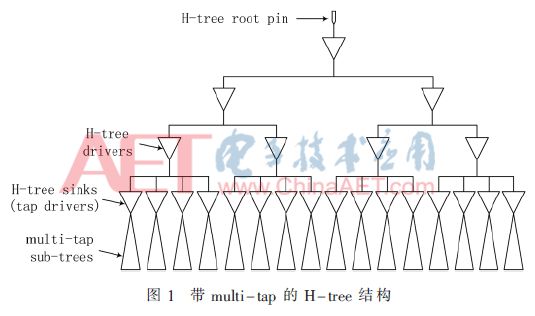
FlexHtree结构具有实现流程简单,易于嵌入到整个P&R(布局和布线)流程中实现的特点。并且对于含有存储器(memory)和宏模块(macro)的布局也可以采用H-tree实现。还有其对时钟门控单元(clock gating)结构的复杂度也没有过多要求。由于其不需要过分关注H-tree上时钟缓冲器和时钟主干的几何对称性,只要能保证在multi-corner下RC参数的电气对称性也可实现clock skew的降低。而对于传统的H-tree,出于几何对称性的考虑,必须对H-tree sink数量以及sink位置进行约束[1]。
1.2 Fishbone时钟结构
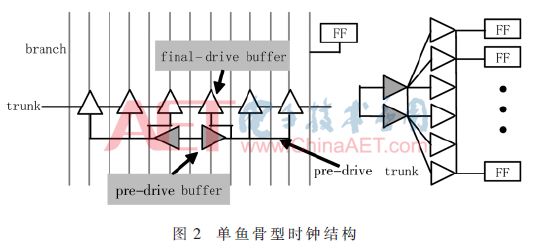
顾名思义,Fishbone时钟结构就是其形状类似于鱼骨头的一种时钟结构。依据主干的条数,通常将Fishbone时钟网络分为单鱼骨结构、双鱼骨结构与多鱼骨结构。图2中是一个单鱼骨结构的示意图,灰色三角形为前级驱动器,白色三角形为主干驱动器。灰色为时钟分支。Fishbone前级驱动一般多采用H-tree结构来驱动多扇入缓冲器阵列,根据负载点的数量来选择金字塔形状的多扇入驱动缓冲器阵列级数。正是由于最后一级主干驱动器并联提供的驱动能力,鱼骨(trunk)才可以“横穿”整个floorplan,保证每根鱼刺(branch)上的局部缓冲器时钟到达延时相同。这里的局部缓冲器作为子树的根节点,使用CTS生成时钟树。
Fishbone结构的优点是skew小,时钟latency短,OCV小,只需要很少的缓冲器,功耗低,布线开销小,可实现useful skew。缺点就是不能自动化,需要大量手工调整[2]。其比较适用于长条形较为对称的floorplan。
2 Multi-tap FlexHtree实现
本节主要介绍FlexHtree的时钟树综合流程,对各步骤进行了说明。然后分别讨论tap点个数对clock skew的影响,并对比了子树使用innovus ICTS和CCOPT引擎生成时钟树对时序的影响。本节也同时对比了CTS、FlexHtree和Fishbone 3种结构实现时钟树的clock skew变化,指导芯片设计者更进一步挖掘3种结构的特点。
2.1 FlexHtree时钟树综合流程
图3所示为使用Cadence innovus工具综合带multi-tap的FlexHtree的流程,先将做完memory、macro和标准单元布局的数据库作为FlexHtree综合的起点,此时数据路径延时优化已经做好。具体步骤:(1)工具依据标准时序约束(SDC)来创建时钟树spec;(2)定义时钟树绕线规则,对时钟主干和分支指定不同的绕线规则;(3)确定时钟树设计约束,以达到预期的skew、transition和时钟缓冲器扇出数量;(4)定义FlexHtree创建规范,如时钟源点、是否对称、tap点个数及位置区域等;(5)对定义的Flex-Htree主干进行综合,综合之后检查tap点位置及trunk绕线是否比较合理;(6)对放好的multi-tap点创建时钟以及定义时钟分组;(7)对定义子树进行综合,子树内部可以采取平衡树,也可以采取借用useful skew的不平衡树,此时子树综合后的时序不理想就要分析子树的划分是否合理,是否依据逻辑关系、物理位置进行了合理的挂载,同时要注意单个子树的clock latency是否过长。
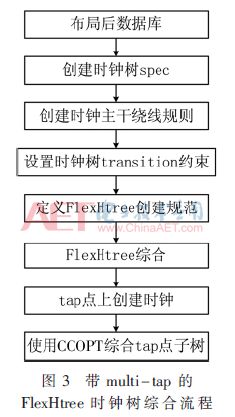
用带multi-tap点FlexHtree实现时钟树的难点在于tap点数量的确定以及不同tap点下合理挂载sink问题。
2.2 不同tap点个数对clock skew影响
本节tap点子树使用了ICTS引擎进行平衡树生成,保证tap点以下子树内的clock latency也能做平。为了探讨不同tap点对clock skew的影响,分别选取了4、6、8、18个tap点生成FlexHtree,图4为tap点个数与clock skew分布关系图。横轴为clock skew范围,每50 ps一个步长,纵轴是各clock skew区间下条数占总条数百分比。
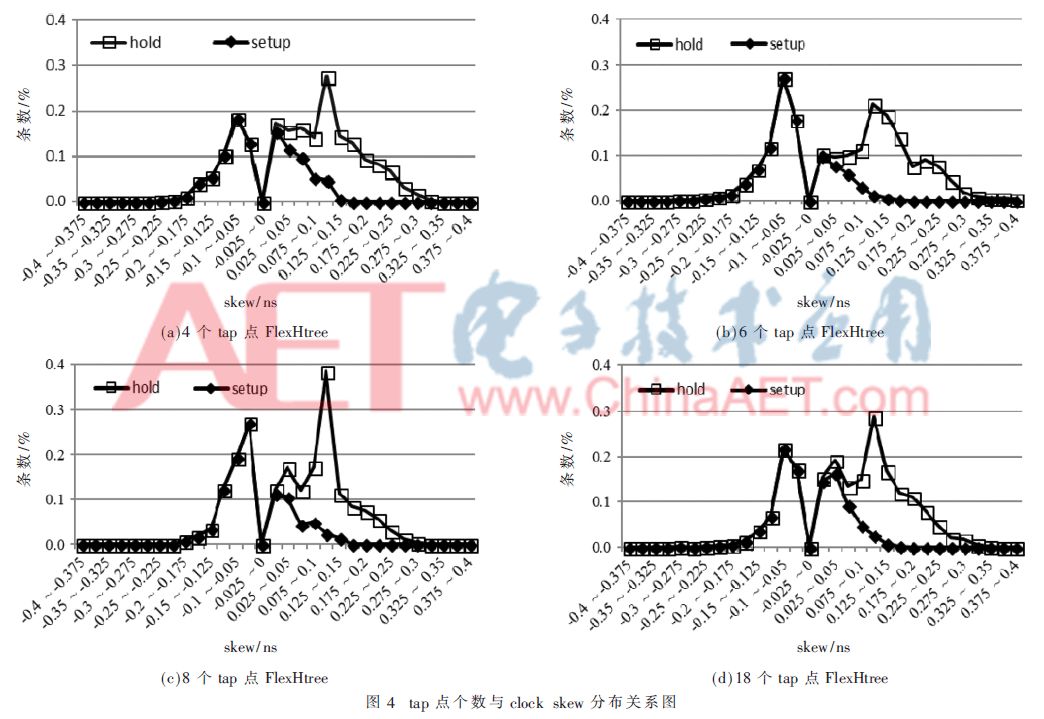
从图4中可以看出,菱形setup折线的峰值点主要出现在-150 ps~125 ps区间内,图4(b)和图4(c)skew分布比较集中于-150 ps~0 ps范围,这与工具使用负的useful skew来修保持时序(hold)违反有关系;图4(b)和图4(c)中正的useful skew集中于25 ps~100 ps,说明工具将时钟树做得比较平衡,而图4(a)和图4(d)比较离散,时钟树做得不是很平。对hold折线来说,图4(b)和图4(c)的skew分布更为集中在-75 ps~0 ps和25 ps~175 ps这两个区间,因此其setup时序好于其他两者。图4(c)中clock skew更为集中在-75 ps~0 ps以及25 ps~125 ps区间,这说明8个tap点在兼顾setup时序的同时也修了hold。从4个图中可以看出8个tap点下clock skew较小,且比较集中, setup和hold好于其他3种情况。
2.3 Multi-tap FlexHtree tap点合理划分分析
为了深一步搞清楚8个tap点下时序好的原因,图5提供了8个tap点FlexHtree在floorplan中的sink分布。从图中可以看出,本设计为典型的长方形结构,memory成对称放置,沿上下出pin区域左右两边分别归属于l3c_pipeline_0和l3c_pipeline_1 module。图中8块位置用不同颜色以及边界折线区分开来,同时在相应区块中标记了sink所属module,高亮的直线为8tap点H-tree结构。这样的tap点划分充分考虑到了sink点的物理位置以及module间交互(talk)关系,避免了tap点与sink距离过远和tap点下所带sink数过大导致的子树clock latency偏大,从而不利于子树间talk path时序的收敛。图5中module的切分考虑到了减少talk path,更多将某些小的module都挂载到一个tap点下,因此这种8个tap的定义才获得了时序容易满足的好处。

表1为8个tap点所带sink数目以及tap点common path clock latency(简称CPCL)在子树平均clock latency中百分比。从表中可以看出Htree_tap0下面挂载sink数量最多,对应图5liu_pre_processor module所在区域;Htree_tap1下挂载sink数量次之,对应图5 L3c_cfg和L3c_pipeline_0 module所在区域;Htree_tap4下挂载sink数量最少,对应图5中间右下位置L3c_pipeline_1 module区域。其他tap点下挂载sink数量基本接近。8个tap点下CPCL都在40%以上,这样OCV对tap点下sink的影响就没那么大。从tap点下sink数量与CPCL的对应关系看,Htree_tap0和Htree_tap1并没有因为sink数量多平均clock latency就越大,出现这种情况说明工具对tap0和tap1 sink切分合理,子树下sink clock latency做得比较平。从另外一个方面来看,8个tap点的CPCL百分之间偏差不大,8个子树之间做得也比较平,这样对子树间hold响主要就是OCV了。所以,分析FlexHtree做得好不好,可以从子树sink module划分、物理位置、子树sink数目和CPCL百分比出发。
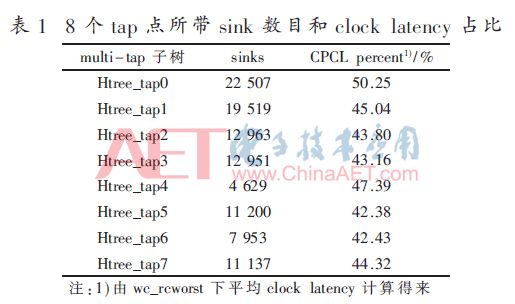
图6为8个tap点在5个不同corner下公共clock latency的比较图。从柱状图中可以看出tap点时钟clock latency在不同corner下的偏差不超过70 ps,tap点之间的clock latency相差不到3 ps,这也证实了前面1.1节所提到的FlexHtree特点:multi-corner下RC参数的电气对称性,以及tap点之间的RC参数电气对称性。这样保证了各corner下时序的一致性。

2.4 使用平衡和非平衡树综合tap点子树
本节中讨论了分别使用innovus的ICTS和CCOPT引擎综合tap点子树的时序结果,如表2、表3所示,表格中wns(worst negative slack)代表时序违反最差路径,tns(total negative slack)代表所有时序违反路径的违反值之和。两表格中的setup和hold结果均为postroute阶段innovus报出的结果。从表2和表3中wns和tns结果来看,8个tap点效果最好,不论setup和hold;tap点多的情况下hold的wns和tns会好于tap点少的情况。
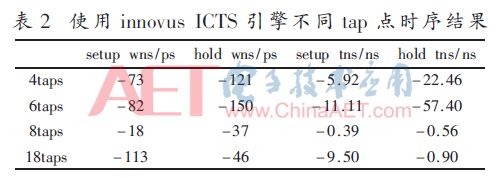
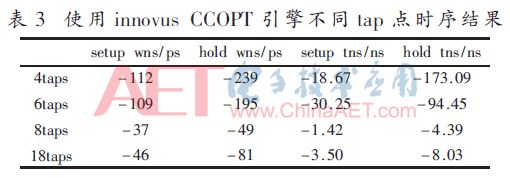
将表2与表3进行比较可知,使用CCOPT引擎综合的子树对于4个、6个和8个tap点时wns和tns均会变差,但tap点为18个时,setup的wns和tns会变好。因此可以得出如下结论:tap点多更适合于降低hold违反条数,在tap点比较多情况下,使用CCOPT引擎综合子树的时序效果好于ICTS引擎。
3 3种不同结构实现时钟树时序、面积和功耗比较
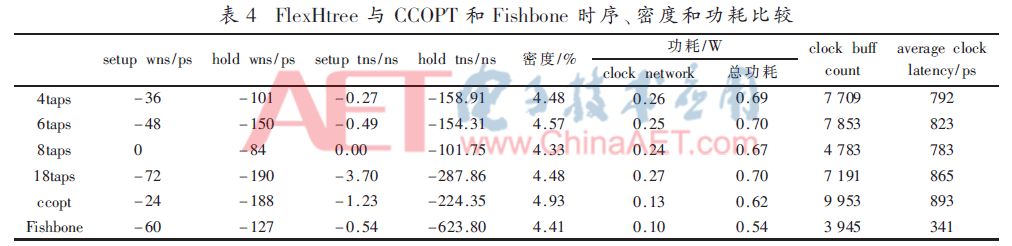
本节将3种不同结构时钟树FlexHtree、CCOPT和Fishbone从时序、面积和功耗方面进行比较,进而选出一种更优的时钟树实现方案。从表4中可以看出8个tap点的FlexHtree setup和hold时序均要好于CCOPT和Fishbone结构,从侧面也反映了8个tap点方案对clock skew控制要好于另外两种结构,并且其density利用率也是最低的,从clock buff count也进一步证明了其使用了较少的useful skew。从average clock latency来看,由于FlexHtree使用了高层绕线,其值要低于CCOPT,但高于Fishbone。从功耗来看,FlexHtree的功耗,尤其是使用ICTS引擎综合子树的FlexHtree,其clock network功耗要高于CCOPT和Fishbone结构。表格中一个显著的特征就是,Fishbone结构时钟树功耗最小,这与其占用的布线资源少、使用的时钟缓冲器少有直接的关系。但是对于Fishbone结构,由于必须手工进行,子树的划分是一个难题,本文也只是做了大量的尝试,但时序结果看起来并未有多少好处。这也是本文选用FlexHtree的原因。
4 结论
本文在innovus工具平台下建立了带multi-tap的FlexHtree自动化时钟树综合流程。使用innovus实现了4、6、8和18个tap点的FlexHtree,同时针对tap点子树要不要做平,分别选用了ICTS和CCOPT进行子树的综合。为了更深入地说明为何选用FlexHtree结构,也尝试了CCOPT综合和Fishbone手工实现时钟树的方案,从clock skew、时序、面积和功耗等方面进行了比较,最终确定了使用FlexHtree方案实现L3 cache设计。同时本文也对FlexHtree tap点合理划分进行了分析,有利于接下来对tap点位置和sink挂载进一步优化,控制clock skew,实现setup和hold均比较容易收敛的结果。本文的结果也对类似memory比较多的设计提供直接的时钟树设计经验,同时本文的分析方法也可以指导设计者探索时钟树物理空间。
-
时钟树优化与有用时钟延迟2011-10-26 4940
-
数字IC设计中的分段时钟树综合2023-12-04 3945
-
TAITherm三维热仿真分析工具的特点和耦合流程2020-12-15 6289
-
求大神分享最全的Synopsys DC综合流程教程2021-06-23 3003
-
STM32时钟树案例详解2021-08-20 1580
-
Vivado综合引擎的增量综合流程2019-07-21 2107
-
机器流程自动化是什么2020-01-01 9786
-
智能流程自动化技术综述2021-06-14 5783
-
评价时钟树质量的方法2022-09-05 2641
-
工业自动化时代的制造进步2022-12-29 1079
-
一个自动化的测试流程2023-05-04 521
-
时钟树综合CTS阶段如何去降低Latency和Skew2023-05-22 6543
-
时钟树:芯片的大动脉2023-07-15 7262
-
时钟树是什么?介绍两种时钟树结构2023-12-06 3235
全部0条评论

快来发表一下你的评论吧 !
