

自动驾驶芯片,cpu与asic的未来发展
可编程逻辑
描述
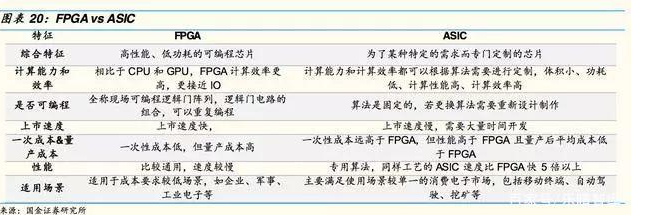
ASICvsGPU+FPGA
GPU适用于单一指令的并行计算,而FPGA与之相反,适用于多指令,单数据流,常用于云端的“训练”阶段。
此外与GPU对比,FPGA没有存取功能,因此速度更快,功耗低,但同时运算量不大。结合两者优势,形成GPU+FPGA的解决方案。
FPGA和ASIC的区别主要在是否可以编程。FPGA客户可根据需求编程,改变用途,但量产成本较高,适用于应用场景较多的企业、军事等用户;而ASIC已经制作完成并且只搭载一种算法和形成一种用途,首次“开模”成本高,但量产成本低,适用于场景单一的消费电子、“挖矿”等客户。
目前自动驾驶算法仍在快速更迭和进化,因此大多自动驾驶芯片使用GPU+FPGA的解决方案。未来算法稳定后,ASIC将成为主流。
计算能耗比,ASIC>FPGA>GPU>CPU,究其原因,ASIC和FPGA更接近底层IO,同时FPGA有冗余晶体管和连线用于编程,而ASIC是固定算法最优化设计,因此ASIC能耗比最高。
相比前两者,GPU和CPU屏蔽底层IO,降低了数据的迁移和运算效率,能耗比较高。同时GPU的逻辑和缓存功能简单,以并行计算为主,因此GPU能耗比又高于CPU。
▌ASIC是未来自动驾驶芯片的核心和趋势
结合ASIC的优势,我们认为长远看自动驾驶的AI芯片会以ASIC为解决方案,主要有以下几个原因:

综上ASIC专用芯片几乎是自动驾驶量产芯片唯一的解决方案。由于这种芯片仅支持单一算法,对芯片设计者在算法、IC设计上都提出很高要求。
以上并非下定论目前ASIC为核心的芯片一定比GPU+FPGA的芯片强,由于目前自动驾驶算法还在快速迭代和升级过程中,过早以固有算法生产ASIC芯片长期来看不一定是最优选择。
▌相关公司
Mobileye
Intel在ADAS处理器上的布局已经完善,包括Mobileye的ADAS视觉处理,利用Altera的FPGA处理,以及英特尔自身的至强等型号的处理器,可以形成自动驾驶整个硬件超级中央控制的解决方案。
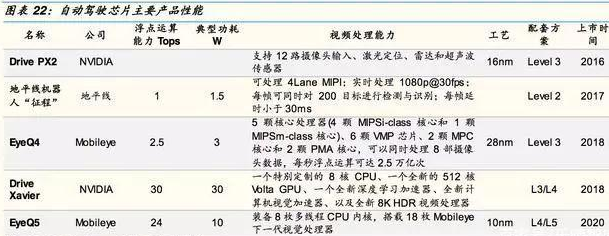
Mobileye具有自主研发设计的芯片EyeQ系列,由意法半导体公司生产供应。现在已经量产的芯片型号有EyeQ1至EyeQ4,EyeQ5正在开发进行中,计划2020年面世,对标英伟达DrivePXXavier,并透露EyeQ5的计算性能达到了24TOPS,功耗为10瓦,芯片节能效率是DriveXavier的2.4倍。
英特尔自动驾驶系统将采用摄像头为先的方法设计,搭载两块EyeQ5系统芯片、一个英特尔凌动C3xx4处理器以及Mobileye软件,大规模应用于可扩展的L4/L5自动驾驶汽车。该系列已被奥迪、宝马、菲亚特、福特、通用等多家汽车制造商使用。
从硬件架构来看,该芯片包括了一组工业级四核MIPS处理器,以支持多线程技术能更好的进行数据的控制和管理(下图左上)。
多个专用的向量微码处理器(VMP),用来应对ADAS相关的图像处理任务(如:缩放和预处理、翘曲、跟踪、车道标记检测、道路几何检测、滤波和直方图等,下图右上)。
一颗军工级MIPSWarriorCPU位于次级传输管理中心,用于处理片内片外的通用数据。
此外通过行业访谈调研等途径了解到,Mobileye在L1-L3智能驾驶领域具有极大的话语权,对Tire1和OEM非常强势,其算法和芯片绑定,不允许更改。
寒武纪
5月3日,寒武纪科技在2018产品发布会上发布了多个IP产品——采用7nm工艺的终端芯片Cambricon1M、云端智能芯片MLU100等。
其中寒武纪1M芯片是公司第三代IP产品,在TSMC7nm工艺下8位运算的效能比达5Tops/w(每瓦5万亿次运算),同时提供2Tops、4Tops、8Tops三种尺寸的处理器内核,以满足不同需求。
1M还将支持CNN、RNN、SVM、k-NN等多种深度学习模型与机器学习算法的加速,能够完成视觉、语音、自然语言处理等任务。通过灵活配置1M处理器,可以实现多线和复杂自动驾驶任务的资源最大化利用。它还支持终端的训练,以此避免敏感数据的传输和实现更快的响应。
寒武纪首款云端智能芯片CambriconMLU100同期发布,同时公布了在R-CNN算法下MLU100与英伟达TeslaV100(2017)和英伟达TeslaP4(2016)的对比,从参数上看,主要对标TeslaP4。最后说明芯片从设计到落地应用面临的潜在风险:
地平线
2017年地平线发布了新一代自动驾驶芯片“征程”和配套软件平台方案“雨果”,同时还发布了应用于智能摄像头的“旭日”处理器。
“征程”是一款专用AI芯片,采用地平线的第一代BPU架构,可实时处理1080p@30视频,每帧中可同时对200个目标进行检测、跟踪、识别,典型功耗1.5W,每帧延时小于30ms。CEO余凯介绍,地平线的芯片更聚焦在针对不同场景下的具体应用,相比于英伟达的方案,在功耗上低一个数量级,价格也会有更大的竞争力。
2018年亚洲CES,地平线宣布推出从L2到L4级别全系列的自动驾驶计算平台。
地平线星云,基于征程1.0芯片,能够以车规级标准满足L1和L2级别的自动驾驶的需求,能同时对行人、机动车、非机动车、车道线、交通标志牌、红绿灯等多类目标进行精准的实时监测与识别;并可满足车载设备严苛的环境要求,以及复杂环境下的视觉感知需求,支持L2级别ADAS功能。
地平线Matrix1.0,内置地平线征程2.0处理器架构,最大化嵌入式AI计算性能,是面向L3/L4的自动驾驶解决方案,可满足自动驾驶场景下高性能和低功耗的需求。
依托地平线公司自主研发的工具链,开发者和研究人员可以基于Matrix平台部署神经网络模型,实现开发、验证、优化和部署。
百度“昆仑”
7月4日百度AI开发者大会上,李彦宏发布了由百度自主研发的中国首款云端全功能AI芯片——“昆仑”。“昆仑”基于百度8年的AI加速器经验的研发,预计将于明年流片。
“昆仑”采用14nm三星工艺,是业内设计算力最高的AI芯片(100+瓦功耗下提供260Tops性能);512GB/s内存带宽,由几万个小核心构成。
“昆仑”可高效地同时满足训练和推断的需求,除了常用深度学习算法等云端需求,还能适配诸如自然语言处理,大规模语音识别,自动驾驶,大规模推荐等具体终端场景的计算需求。
此外可以支持paddle等多个深度学习框架,编程灵活度高。同时也有媒体对该产品提出疑义,主要有以下两点:
GoogleTPU
GoogleTPU于2016年在GoogleI/O上宣布,当时该公司表示TPU已在其数据中心内使用了一年以上。该芯片专为Google的TensorFlow(一个符号数学库,用于神经网络等机器学习应用)框架而设计。
GoogleTPU是专用的,并不面向市场,谷歌仅表示“将允许其他公司通过其云计算服务购买这些芯片。”
今年2月,谷歌在其云平台博客上宣布的TPU服务开放价格大约为每cloudTPU(180TFLOPS和64GB内存)每小时6.50美元。
Google使用TPU开发围棋系统AlphaGo和AlphaZero以及进行Google街景视频文字处理等,能够在不到五天的时间内找到街景数据库中的所有文字,此外TPU也用于提供Google搜索结果的排序。
TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
Xilinx&深鉴科技
Xilinx赛灵思是FPGA的先行者和领导者,1984年,赛灵思发明了现场可编程门阵列FPGA,作为半定制化的ASIC,顺应了计算机需求更专业的趋势。
FPGA的好处是可编程以及带来的灵活配置,同时还可以提高整体系统性能,比单独开发芯片整个开发周期大为缩短,但缺点是价格、尺寸等因素。
在汽车ADAS和自动驾驶解决方案上,赛灵思的FPGA和SOC产品家族衍生出三个模块:
自动驾驶中央控制器ZynqUltraScale+MPSoC
前置摄像头Zynq-7000/ZynqUltraScale+MPSoC
多传感器融合系统ZynqUltraScale+MPSoC
Zynq采用单一芯片即可完成ADAS解决方案的开发,SOC平台大幅提升了性能,便于各种捆绑式应用,能实现不同产品系列间的可扩展性,可帮助系统厂商加快在环绕视觉、3D环绕视觉、后视摄像头、动态校准、行人检测、后视车道偏离警告和盲区检测等ADAS应用的开发时间。并且可以让OEM和Tier1在平台上添加自己的IP以及赛灵思自己的扩展。
深鉴科技成立于2016年,其创始团队有着深厚的清华背景,专注于神经网络剪枝、深度压缩技术及系统级优化。2018年7月17日,赛灵思宣布收购深鉴科技。
自成立以来,深鉴科技就一直基于赛灵思的技术平台开发机器学习解决方案,推出的两个用于深度学习处理器的底层架构—亚里士多德架构和笛卡尔架构的DPU产品,都是基于赛灵思FPGA器件。
对于赛灵思来说,看好深鉴科技基于机器学习的软件、算法,以及面向云侧和端侧硬件架构的优势;对于深鉴科技,后期发展高昂的研发费用、高成本的芯片设计、流片、试制、认证、投片量产,投靠赛灵思能够降低随之而来的风险,进入芯片战争的持久战。
2018年6月,深鉴科技宣布进军自动驾驶领域,自主研发的ADAS辅助驾驶系统——DPhiAuto,目前已获得日本与欧洲一线车企厂商和Tier1的订单,即将实现量产。
DPhiAuto,基于FPGA,是面向高级辅助驾驶和自动驾驶的嵌入式AI计算平台,可提供车辆检测、行人检测、车道线检测、语义分割、交通标志识别、可行驶区域检测等深度学习算法功能,是一套针对计算机视觉环境感知的软硬件协同产品。
功耗方面,可以在10-20W的功耗范围内,实现等效性能,能效比指标高于目前主流的CPU、GPU方案。(国金证券:张帅)百度搜索“乐晴智库”获得更多行业报告。
-
FPGA在自动驾驶领域有哪些应用?2024-07-29 8384
-
自动驾驶的到来2017-06-08 7466
-
浅析自动驾驶发展趋势,激光雷达是未来?2017-09-06 5521
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 7572
-
车联网对自动驾驶的影响2019-03-19 3581
-
如何让自动驾驶更加安全?2019-05-13 3758
-
自动驾驶汽车的处理能力怎么样?2019-08-07 2917
-
自动驾驶系列报告大放送了涉及传感器,芯片,执行控制等2019-08-09 3638
-
联网安全接受度成自动驾驶的关键2020-08-26 3346
-
如何保证自动驾驶的安全?2020-10-22 2210
-
网联化自动驾驶的含义及发展方向2021-01-12 4941
-
自动驾驶OS市场的现状及未来 精选资料推荐2021-07-27 2532
-
车载芯片的发展趋势(CPU-GPU-FPGA-ASIC)2018-08-09 24729
-
浅析应用于自动驾驶中的芯片2018-11-05 6370
-
自动驾驶芯片现状盘点 国产自动驾驶芯片发展面临的机遇和挑战2023-02-21 2274
全部0条评论

快来发表一下你的评论吧 !
