

ARM架构和总线协议如何支持Linux原子操作?
描述
这篇文章探讨ARM架构和总线协议如何来支持的。对于某款ARM处理器和总线CCI,CCN和CMN产品的具体实现,属于实现层面的微架构,一般需要NDA,这里不予讨论。
顺便提一下,在ARMv8 架构下对应的是LDXR (load exclusive register 和STXR (store exclusiveregister)及其变种指令,另外,在ARMv8.1架构中引入atomic instruction, 例如LDADD (Atomic add),CAS(Compare and Swap)等。
Exclusive monitor
首先,作为一个爱问为什么的工程师,一定会想到LDXR/ STXR和一般的LDR/STR有什么区别。这个区别就在于LDXR除了向memory发起load请求外,还会记录该memory所在地址的状态(一般ARM处理器在同一个cache line大小,也就是64 byte的地址范围内共用一个状态),那就是Open和Exclusive。
我们可以认为一个叫做exclusive monitor的模块来记录。根据CPU访问内存地址的属性(在页表里面定义),这个组件可能在处理器 L1 memory system, 处理器cluster level, 或者总线,DDR controller上。
下面是Arm ARM架构 [1] 文档定义的状态转换图
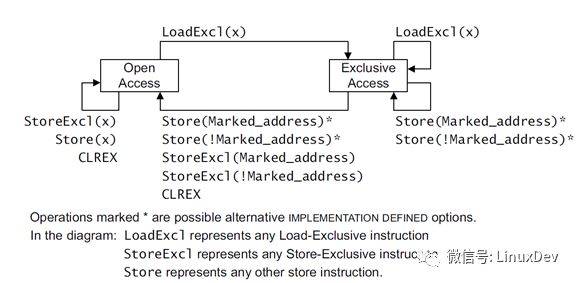
实例说明:
1)CPU1发起了一个LDXR的读操作,记录当前的状态为Exclusive
2)CPU2发起了一个LDXR的读操作,当前的状态为Exclusive,保持不变
3)CPU2发起了一个STXR的写操作,状态从Exclusive变成Open,同时数据回写到DDR
4)CPU1发起了一个STXR的写操作,因为当前的exclusive monitor状态为Open,写失败(假如程序这时用STR操作来写,写会成功,但是这个不是原子操作函数的本意,属于编程错误)
假如有多个CPU,同时对一个处于Exclusive的memory region来进行写,CPU有内部逻辑来保证串行化。
Monitor的状态除了STXR会清掉,从Exclusive变成Open之外,还有其他因素也可以导致monitor的状态被清掉,所以软件在实现spinlock的时候,一般会用一个loop循环来实现,所谓“spin”。
Exclusive monitor实现所处的位置
根据LDXR/STXR 访问的memory的属性,需要的monitor可以在CPU内部,总线,也可以DDR controller(例如ARM DMC-400 [2]在每个memory interface 支持8个 exclusive access monitors)。
一般Memory属性配置为 normal cacheable, shareable,这种情形下,CPU发起的exclusive access会终结在CPU cluster内部,对外的表现,比如cacheline fill和line eviction和正常的读写操作产生的外部行为是一样的。具体实现上,需要结合local monitor的状态管理和cache coherency 的处理逻辑,比如MESI/MOESI的cacheline的状态管理来。
为方便大家理解,下面划出一个monitor在一个假象SOC里面的逻辑图(在一个真实芯片里面,不是所有monitor都会实现,需要和SOC vendor确认)
External exclusive monitor
对于normal non-cacheable,或者Device类型的memory属性的memory地址,cpu会发出exclusive access的AXI 访问(AxLOCK signals )到总线上去,总线需要有对应的External exclusive monitor支持,否则会返回错误。例如, 假如某个SOC不支持外部global exclusivemonitor,软件把MMU disabled的情况下,启动SMP Linux,系统是没法启动起来的,在spinlock处会挂掉。
AMBA AXI/ACE 规范
The exclusive access mechanism can provide semaphore-type operations without requiring the bus to remain dedicated to a particular master for the duration of the operation. This means the semaphore-type operations do not impact either the bus access latency or the maximum achievable bandwidth.
The AxLOCK signals select exclusive access, and the RRESP and BRESP signals indicate the success or failure of the exclusive access read or write respectively.
The slave requires additional logic to support exclusive access. The AXI protocol provides a mechanism to indicate when a master attempts an exclusive access to a slave that does not support it.
Atomic指令的支持
处理器,支持cache coherency协议的总线,或者DDR controller可以增加了一些简单的运算,比如,在读写指令产生的memory访问的过程中一并把简单的运算给做了。
AMBA 5 [3] 里面增加了对Atomic transactions的支持:
AMBA 5 introduces Atomic transactions, which perform more than just a single access, and have some form of operation that is associated with the transaction.
Atomic transactions are suited to situations where the data is located a significant distance from the agent that must perform the operation. Previously, performing an operation that is atomically required pulling the data towards the agent, performing the operation, and then pushing the result back.
Atomic transactions enable sending the operation to the data, permitting the operation to be performed closer to where the data is located.
The key advantage of this approach is that it reduces the amount of time during which the data must be made inaccessible to other agents in the system.
支持4种Atomic transaction:AtomicStore ,AtomicLoad,AtomicSwap 和AtomicCompare
QA
1) Local monitor和Global monitor的使用场景
* Local monitor适用于访问的memory属为normal cacheable, shareable或者non-shareable的情况.
* Global monitor ,准确来说,external global exclusive monitor (处理器之外,在外部总线上)用于normal noncacheable或者device memory类型。比如可以用于一个Cortex-A处理器和一个Cortex-M 处理器(没有内部cache)之间的同步。
2)多CPU下,多个LDREX,和STREX的排他性实现
* 各个处理器和总线的实现不同,可以从软件上理解为和data coherency实现相结合,比如M(O)ESI协议[5],这是一种Invalidate-based cache coherence protocol, 其中的key point就是当多个CPU在读同一个cacheline的时候,在每个CPU的内部cache里面都有cacheline allocation, cacheline的状态会变成Shared;但是当某个CPU做写的时候,会把其它CPU里面的cacheline数据给invalidate掉,然后写自己的cacheline数据,同时设置为Modified状态,从而保证了数据的一致性。
* LDREX,本质上是一个LDR,CPU1做cache linefill,然后设置该line为E状态(Exclusive),额外的一个作用是设置exclusive monitor的状态为Exclusive;其他cpu做LDREX,该line也会分配到它的内部cache里面,状态都设置为Shared ,也会设置本CPU的monitor的状态。当一个CPU 做STREX时候,这个Write操作会把其它CPU里面的cacheline数据给invalidate掉。同时也把monitor的状态清掉,从Exclusive变成Open的状态,这个MESI协议导致cachline的状态在多CPU的变化,是执行Write操作一次性改变的。这样在保证数据一致性的同时,也保证了montitor的状态更新同步改变。
3)比如举一个多核的场景,一个核ldrex了,如果本核的local monitor会发生什么,外部的global monitor发生什么,开不开mmu,cache不cache,区别和影响是什么。
Ldrex/strex本来就是针对多核的场景来设计的,local monitor的状态发生改变,不会影响外部的global monitor状态。但是external global monitor的状态发生改变,可以告诉处理器,把local monitor的状态清掉。
Data coherency是通过硬件来支持的。对于normal cacheable类型的memory, MMU和DCache必须使能,否则CPU会把exclusive类型的数据请求发出处理器,这时需要外部monitor的支持。
-
X86和ARM中的指令集支持原子操作2023-07-06 2548
-
工程师深谈ARM+FPGA的设计架构2017-01-12 14342
-
ARM架构是什么2021-07-01 1625
-
ARM架构简单介绍2021-12-06 2272
-
SOC芯片之互联总线协议相关资料分享2022-07-18 4760
-
设备仿真模拟软件 QEMU 8.0 发布:改进对 ARM / RISC-V 架构支持2023-05-05 2378
-
基于嵌入式系统异构总线的原子协议锥匹配2009-04-20 650
-
Linux环境下实现ARM9的CAN总线通信2009-11-02 1166
-
手机支持的Linux操作系统2010-01-28 2064
-
ARM+Linux设计的CAN总线和MiniGUI的虚拟仪表2010-05-06 2057
-
ARM架构应用实例_操作系统2016-07-08 725
-
浅谈鸿蒙内核源码的原子操作2021-04-25 1784
-
使用Linux原子操作实现互斥点灯2023-04-13 1384
-
Emulex HBA CLI ARM架构上的Linux发行说明2023-08-10 445
-
arm架构和x86架构区别 linux是x86还是arm2024-01-30 24129
全部0条评论

快来发表一下你的评论吧 !
