

深度神经决策树:深度神经网络和树模型结合的新模型
电子说
描述
近日,来自爱丁堡大学的研究人员提出了一种结合深度神经网络和树模型的新型模型——深度神经决策树(Deep Neural Decision Trees, DNDT)。
这种模型不仅具有了基于树模型的可解释性的优点,同时还可以利用神经网络中的梯度下降法来进行训练,并可方便地利用现有的神经网络框架实现,将使得神经网络的过程得以用树的方式得到有效的解释。论文的作者均来自于爱丁堡大学信息学院感知、运动和行为研究所ipab。
对于感知模型来说可解释性是十分重要的,特别是在一些涉及伦理、法律、医学和金融等场景下尤其如此,同样在关键领域的控制中,我们希望能够回溯所有的步骤来保证模型因果逻辑和结果的正确性。深度神经网络在计算机视觉、语音识别和语言模型等很多领域取得了成功,但作为缺乏可解释性的黑箱模型,限制了它在模型必须求证因果领域的应用,在这些领域中我们需要明确决策是如何产生的以便评测验证整个决策过程。除此之外,在类似于商业智能等领域,知晓每一个因素是如何影响最终决策比决策本身有时候更为重要。与此不同的是,基于决策树模型(包括C4.5和CART等)拥有清晰的可解释性,可以追随树的结构回溯出决策产生的因由。
爱丁堡大学的研究人员们基于树和神经网络的结构提出了一种新型的模型——深度神经决策树(DNDT),并探索了树和网络之间的相互作用。DNDT是一种具有特殊结构的神经网络,任意一种配置下的DNDT都对应着决策树,这使其具有了可解释性。同时由于DNDT实现自神经网络,使得它拥有了很多传统决策树不曾具有的特性:
1.DNDT可以通过已有的神经网络工具便捷的实现,可能只需要几行即可;
一个实现的例子
2.所有的参数可以通过随机梯度下降法(SGD)同时优化,代替了复杂的贪婪优化过程;
3.具有大规模处理数据的能力,可以利用mini-batch和GPU加速;
4.可以作为一个模块插入到现有的神经网络模型中,并整体训练。
在这种网络中研究人员们使用了一种称为soft binning function的函数,并将它用于DNDT中的分支操作。一个典型的soft binning函数可以得到输入标量的二进制值,与Hard binning不同的是,这是一种可微的近似。这使得决策树中的的参数是可导的,也就可以利用梯度下降法来进行训练了。下式是MDMT中的一层神经元表示:
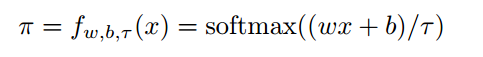
其中w为权重参数[1,2,。。。,n+1],b表示为[0,-β1,-β2...-βn],代表了n个分支点。式中的τ代表了温度因子,其趋向于0时将为生成one-hot编码。下图是不同τ作用下的soft binning函数:
其中x在[0,1]区间内,此时的分割点为0.33和0.66,三个图分别代表了τ为1,0,1和0.01的情况,越小意味着分支越陡峭。其中,
o1 = x
o2 = 2x-0.33
o3 = 3x-0.99
在决策过程中,通过上式给出的二进制函数利用克罗内克内积来实现,下图中显示了DNDT在Iris数据集上的学习过程,上半部分描述了深度神经决策树的运行过程,其中红色表示为可训练的变量,黑色数字为常量。下半部分作为对比显示了先前决策树的分类过程。
通过本文提出的方法,研究人员将决策树的训练过程转换为了训练二进制分支点和叶子分类器。同时由于前传过程是可微的,所以所有的点都可以同时利用SGD的方法来训练。由于可以利用与神经网络类似的mini-batch,DNDT可以便捷的实例规模化。但目前存在的问题是克罗内克积的存在使得特征的规模化不易实现。目前的解决方案是引入多棵树来来训练特征集中的子特征组合,避免了较“宽”的数据。
研究人员通过实验验证了中模型的有效性,在常见的14个数据集上(特别是Tabular类型的数据)取得了较好的结果。其中决策树使用了超参数,“基尼”尺度和“best”分支;神经网络使用了两个隐藏层共50个神经元作为基准。而DNDT则使用了1最为分支点数目的超参数。
研究显示DNDT模型随着分割点的增加,整体激活的比重却在下降,显示了这种模型具有正则化的作用。
同时研究还显示了分割点数量对于每一个特征的影响;
并利用了GPU来对计算过程进行了加速。
在未来还会探索DNDT与CNN的结合与应用,并将SGD应用到整个模型的全局优化中去,并尝试基于决策树的迁移学习过程。
-
深度神经网络模型有哪些2024-07-02 3149
-
cnn卷积神经网络模型 卷积神经网络预测模型 生成卷积神经网络模型2023-08-21 1913
-
卷积神经网络模型发展及应用2022-08-02 13207
-
基于树的方法和神经网络方法2022-07-27 1625
-
介绍支持向量机与决策树集成等模型的应用2021-09-01 1251
-
深度神经网络是什么2021-07-12 1964
-
基于遗传优化决策树的建筑能耗预测模型2021-06-27 858
-
深度神经网络模型的压缩和优化综述2021-04-12 1100
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 13876
-
什么情况下基于树的模型将超过神经网络模型2020-09-16 2246
-
决策树和随机森林模型2019-04-19 8862
-
结合深度神经网络和决策树的完美方案2018-07-25 10769
-
从AlexNet到MobileNet,带你入门深度神经网络2018-05-08 2735
-
斯坦福探索深度神经网络可解释性 决策树是关键2018-01-10 6265
全部0条评论

快来发表一下你的评论吧 !
