

立体视觉和激光雷达在3D智驾感知领域的差异分析
描述
引言
随着智能驾驶技术从L2级辅助驾驶向L3级有条件自动驾驶加速演进,感知系统作为自动驾驶的“眼睛”,其技术路线的选择一直成为行业核心议题焦点,在3D智驾感知赛道,究竟谁会更胜一筹呢?目前市场主流的高阶智驾感知传感器为单目摄像头+毫米波雷达+激光雷达,并且拥有大部分市场占有率,但是随着技术的发展双目立体视觉凭借其特色优势在智驾感知逐渐占有一席之地,以立体视觉为技术的双目、三目、一体机、Adas等产品的市场占有率也逐渐提升,“智驾未来Lidar方案”逐步向“视觉+雷达”多元化结合的方案转变,此次我们围绕“3D智驾感知领域”推出两篇文章,做一个客观解读,探讨立体视觉在智驾领域的优势以及未来的发展。
激光雷达必要吗?
特斯拉首席执行官埃隆・马斯克经常在正式场合就激光雷达(我们后文称之“LiDAR”)应用在智驾领域多次发表自己的观点,他认为:不同传感器的信息在融合时会出现偏差,从而引发安全风险,而自动驾驶的胜利一定属于大道至简的人眼仿生学。
他认为Lidar是昂贵、多余且脆弱。视觉可以“复制人类驾驶的方式”。经过充分开发和训练基于视觉算法的AI系统,能应用于智能驾驶,甚至可以做得更好。
感知技术原理
在现代智能感知系统中,LiDAR与双目立体视觉是两种三维环境感知技术,均可以应用于智驾感知领域。它们分别模拟了主动激光探测与人类视觉的物理机制,但是各自在数据获取方式、信息表达形式和系统构建逻辑上存在一定的差异性。LiDAR的优势在于精确的测距能力和可靠性,而双目立体视觉的核心优势在于它提供了与人类视觉相似的、富含纹理和语义的深度信息,而且成本更低,在经济形势发展趋缓当下社会认可度逐渐提升,应用范围逐渐扩大。
LiDAR与双目立体视觉逐渐成为自动驾驶、机器人感知等领域的两大核心感知技术,二者基于不同原理(激光测距 vs 视觉匹配)形成差异化能力。双目立体视觉的性能优势主要集中在成本控制、语义感知维度、环境适应性、系统集成灵活性等方面,我们在接下来做详细介绍。
差异分析
在现代智能感知系统中,LiDAR与双目立体视觉在数据获取方式、信息表达形式和系统构建逻辑上存在根本性差异。理解这些差异是评估其性能优劣的前提。
(一)激光雷达
LiDAR是一种主动式三维测距传感器,其工作原理是通过发射激光脉冲(通常为近红外波段),并精确测量激光束从发射到被物体反射后返回接收器的时间差(Time of Flight, ToF)或相位差,从而直接计算出目标点与传感器之间的距离。
LiDAR通过高速旋转或扫描镜阵列,对周围环境进行多角度、高密度的点云扫描,每秒可生成数十万至上百万个三维点,形成连续的、高精度的三维空间结构图。这种点云数据直接包含了每个点的三维坐标(X, Y, Z)以及反射强度等物理属性,能够精确还原物体的几何轮廓、形状和空间位置,无需依赖复杂的图像推断。其数据获取方式具有直接物理测量的特性,从根本上避免了因算法推断带来的信息损失和误差累积,因此在测距精度和空间结构还原上具有天然优势。
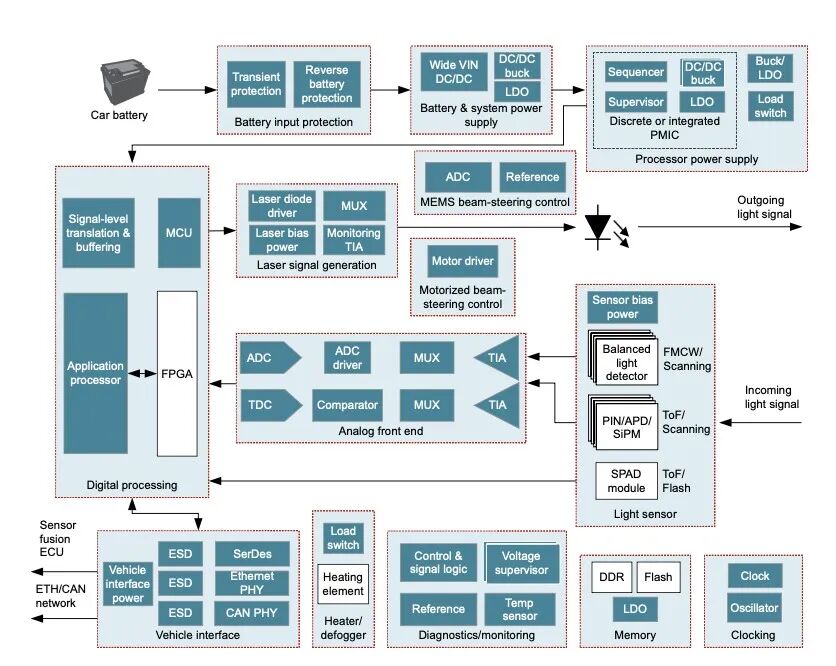
(二)双目立体视觉
相比之下,双目立体视觉拥有其自身的特色,其核心原理基于视差三角测量,模仿人类双眼的立体感知机制如下图所示。
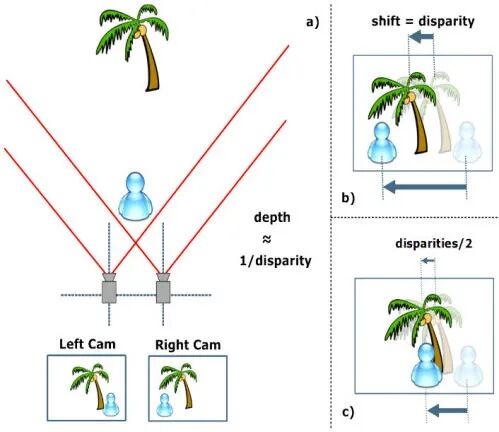
系统由两个摄像头组成,以一定的物理基线(即两摄像机之间的距离)并行安装,同时拍摄同一场景的两幅二维图像。通过算法在两幅图像中寻找同一空间点的对应像素(即特征匹配),计算其在左右图像中的位置差异(视差),再结合已知的基线长度和相机内参,利用三角几何关系推算出该点在三维空间中的深度信息。这一过程本质上是被动式感知,依赖环境中的自然光照,不主动发射能量,因此其性能高度依赖于场景的纹理丰富度、光照均匀性和图像质量。
其技术流程通常包括:图像获取、摄像机标定、特征提取、立体匹配和三维重建五个关键步骤。其中,立体匹配是算法中最复杂且易出错的环节,尤其是在纹理缺失、光照不均或存在重复图案的区域,容易产生误匹配,从而影响深度图的准确性。
(三)数据类型
从数据类型上看,LiDAR直接输出的是三维点云数据,每个点都是一个独立的、精确的物理坐标,信息表达更为直接和可靠,双目立体视觉则是输出的是二维图像序列,其深度信息是通过算法从图像中“推算”出来的,属于一种间接的、基于模型的估计。二者本质差异决定了两者在处理复杂场景时的底层逻辑不同:LiDAR像一个“测绘仪”,直接“打点”获取空间坐标,而双目立体视觉更像一个“解码器”,需要从图像中解析出深度。
在一定程度上立体视觉拥有其独特的优势,下一章我们就立体视觉的优势做具体介绍。
-
基于立体视觉的变形测量2015-09-21 4769
-
常见激光雷达种类2017-09-25 14029
-
激光雷达除了可以激光测距外,还可以怎么应用?2018-05-11 6124
-
5 款激光雷达:iDAR、高清3D LiDARInnovizPro、S3、SLAM on Chip、VLS-1282018-07-26 6090
-
除了机器人行业,激光雷达还能应用于哪些领域?2018-12-10 4925
-
自制低成本3d激光扫描测距仪激光雷达2020-05-27 4627
-
3D视觉的测量原理2020-12-01 2842
-
自制低成本3D激光扫描测距仪(3D激光雷达)2021-03-04 7007
-
3D激光雷达的现在和未来2020-03-23 9883
-
如何通过立体视觉构建小巧轻便的深度感知系统2022-08-23 2109
-
3D Flash 激光雷达测绘和手势识别2023-01-05 2579
-
激光雷达与视觉感知的优劣对比2023-10-30 1641
-
洛微科技携4D FMCW激光雷达与3D感知方案闪耀光博会,引领行业新趋势2025-09-18 1542
-
智驾感知系统中立体视觉相对于LiDAR的性能优势2025-11-11 2350
-
一径科技NZ系列广角全场景3D激光雷达全面赋能商用清洁机器人2026-03-27 1498
全部0条评论

快来发表一下你的评论吧 !
