

Arm Neoverse CPU上大代码量Java应用的性能测试
描述
作者:安谋科技首席软件工程师 Yanqin Wei
Java 是互联网领域广泛使用的编程语言。Java 应用的一些特性使其性能表现与提前编译的原生应用(例如 C 程序)大相径庭。由于 Java 字节码无法直接在 CPU 上执行,因此通常运行时在 Java 虚拟机 (JVM) 内执行。JVM 必须先通过解释器或即时 (JIT) 编译器将字节码转换为机器码,而运行时生成的机器码对 Java 应用的效率和性能至关重要。
在电子商务等一些互联网领域,程序需要处理多样化的用户输入,同时提供丰富的功能。例如,电子商务应用通常集成产品浏览、搜索和筛选,购物车、营销活动、订单管理和支付系统等功能。
每项功能都需要大量的运行时代码、数据及第三方库。因此,基于 Java 的电子商务应用在运行时可能会被编译为庞大的机器码,这些机器码存储在“代码缓存”中,并被反复执行。
大代码量对性能的影响
在 Hotspot JVM 中,代码缓存是一种分配在连续内存区域中类似于堆的结构。它会按代码类型划分为多个段,用户可根据应用需求配置各段的大小。这种设计能减少不同生命周期代码混合造成的内存碎片。这些段包括:
非方法段:包含编译器缓冲区、字节码解释器等非方法代码。这类代码会永久驻留在代码缓存中。
Profiled nmethod:包含经过轻度优化和性能分析的方法,其生命周期较短。
Non-profiled nmethod:包含经过完全优化、无需性能分析的方法,其生命周期可能较长。
C2 编译器将原生代码存储在 non-profiled nmethod 中。该段既包含频繁执行的热点代码,也包含启动期间多次执行、但后续极少调用的代码。
现代 CPU 采用深度管线设计,并包含多个执行单元。Arm Neoverse CPU 的前端从内存中获取指令,并将其解码为称为“微操作”的底层硬件操作;后端则调度这些操作,并在 Neoverse CPU 上以乱序方式执行。代码量过大会影响 CPU 前端性能,具体表现包括指令获取延迟、ITLB 重新填充、指令管线排空,以及分支目标缓冲区条目重新填充等。

大代码实验
我们开展了一项 10 倍代码扩容实验,以模拟大代码缓存场景。通过将 nmethod 所需内存人为地扩容 10 倍,我们创建了一个已用代码缓存巨大的应用,并使用 DaCapo Java 基准测试来衡量其对性能的影响。在 Neoverse N2 平台上运行该实验时,我们发现吞吐量(约 4-6%)和长尾延迟(约 1-3%)均有所下降。下图展示了使用 DaCapo 基准测试中 Spring 测试用例收集的 PMU 统计数据,其中 non-profiled nmethod 大小被放大了 10 倍。
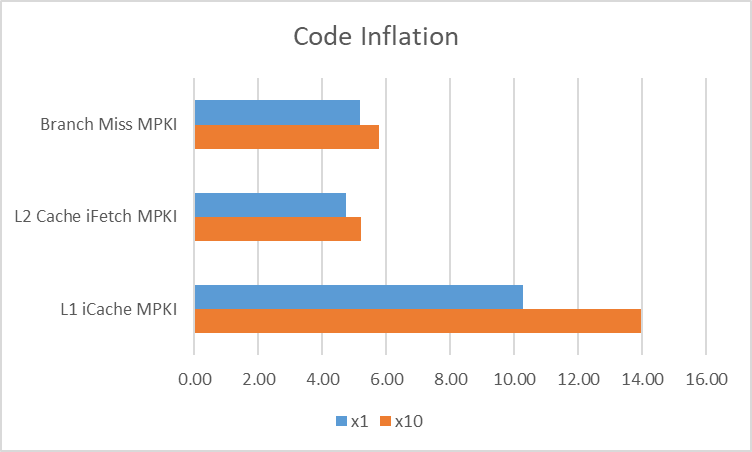
该实验无法完全模拟大代码 Java 应用,因为它仅导致编译器生成的代码在内存地址上分散分布。因此,其性能数据不能完全反映真实场景,但 PMU 统计数据仍能揭示其对前端性能的影响。
此实验不会改变执行的指令或使用的数据,仅会扩大代码的空间分布,最终导致 CPU 前端资源成为瓶颈。
性能优化
这一性能瓶颈与前端资源大小密切相关,包括缓存大小、BTB 大小和 iTLB 大小。不同的 Neoverse CPU 拥有不同的资源规模。无论资源规模如何,我们都可以通过软件或配置优化来减轻这一瓶颈的影响。
将数据移出代码缓存
在代码缓存中,每个编译后的方法都包含代码和数据。这些数据包括方法头、重定位数据、普通对象指针、JMCI 数据、反优化数据、作用域元数据等。通过尽可能从代码缓存中移除数据,可有效减小其占用空间。这种优化能提高代码密度,使得调用这些函数时能更好地利用 CPU 的 L1/L2 缓存、iTLB 和 BTB 资源。
我们尝试将多个补丁反向移植到 OpenJDK 21 中,以在代码扩容实验中衡量它们对性能和 PMU 的影响。这些补丁旨在减小 nmethod 头的大小,并将大部分不可变数据和可变数据从代码缓存中移出。
8329433:减小 nmethod 头大小
https://github.com/openjdk/jdk/commit/b704e91241b0f84d866f50a8f2c6af240087cb29
8331087:将不可变 nmethod 数据从代码缓存中移出
https://github.com/openjdk/jdk/commit/bdcc2400db63e604d76f9b5bd3c876271743f69f
8343789:将可变 nmethod 数据从代码缓存中移出
https://github.com/openjdk/jdk/commit/83de34041eacdf987988364487712c79bbb4c235
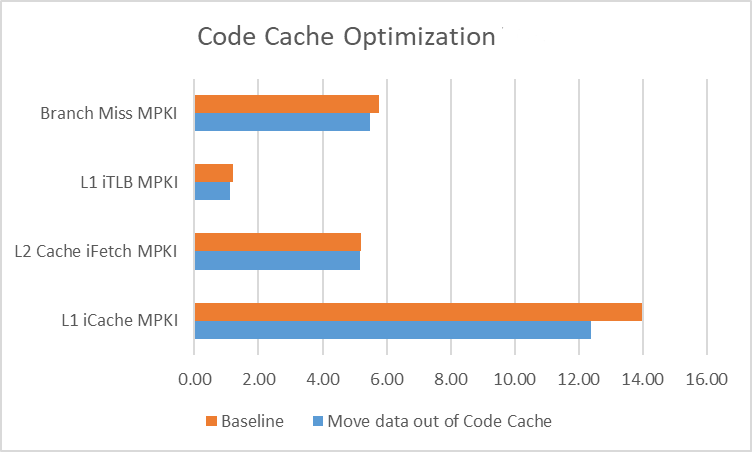
在我们的实验中,non-profiled nmethod 大小减小了 39%,从 229MB 降至 149MB。在 DaCapo 基准测试结果中,随着前端性能指标的优化,吞吐量和长尾延迟均有所改善。从收集的 PMU 数据可以看出,缓存填充、iTLB 重新填充和分支未命中的 MPKI 均有所下降。
其原因在于,代码空间局部性的提升提高了前端资源的使用效率,从而加快了指令的获取和解码操作。
为代码缓存启用透明大页
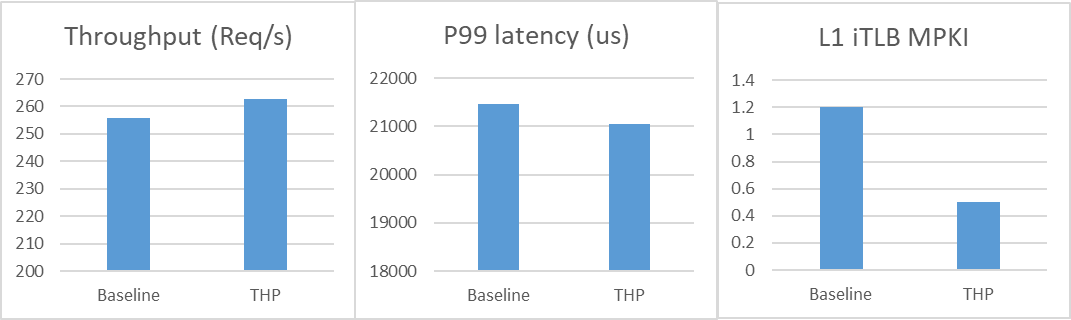
在大代码量的 Java 应用中,执行代码的地址范围较广,这意味着 CPU 需要更多的 MMU 和 TLB 资源来存储虚拟地址到物理地址的映射,进而影响此类应用中的 iTLB 填充性能。对代码缓存区域应用透明大页 (THP) 可以增大页表项大小,减少所需页表的总数,从而减少 iTLB 资源占用。
在 OpenJDK 中,若 Linux 操作系统支持,启用 -XX:+UseTransparentHugePages 选项会为代码缓存堆应用 2MB 的大页。使用这种配置时,可以观察到性能和 iTLB 填充 PMU 指标均有改善。
代码缓存中的热点方法段
在稳定工作负载中,热点代码的总大小通常较小。由于分层编译的机制,热点代码通常存在于 non-profiled nmethod 中。第 4 层 (T4) 方法是在被多次使用后,由 C2 编译器按照其活跃使用检测的顺序进行 JIT 编译,因此热点代码和冷代码往往是交织的。
为了提升 CPU 前端性能,在代码缓存中设置热点方法段可以增强频繁执行代码的空间局部性。将热点方法集中存放能够提高指令获取和解码的效率。
要确定哪些方法应放置在该热点区域,需要使用分析工具收集性能剖析数据。一种方案是利用 Java Flight Recorder (JFR) 在运行时动态调整代码布局,但这种方案较为复杂,且方法重定位会带来额外的性能开销。
或者,可以提前预定义热点方法,其步骤如下:
1.在首次运行时,使用 async-profiler 等工具找出第 4 层热点方法。
2.通过自定义脚本解析 JVM 编译日志,获取这些方法的大小。
3.生成热点方法列表,使其大小符合代码缓存中预定义的热点段大小。
4.创建指令文件,指导 JIT 编译器在下次运行时对热点方法进行优化放置,避免运行时重定位的开销。
如前所述,将 nmethod 拆分为频繁访问部分和非频繁访问部分,并分别分配内存。新增的热点代码段可放置在非 nmethod 段与 non-profiled nmethod 段之间,以保持热点代码空间局部性。

热点段存在一个副作用:它会将原本相邻的一些 non-profiled nmethod 移至不同的段中。在某些情况下,内存地址相邻的方法也会被连续调用,而这种重定位会导致这些连续调用的方法被放置在不同的内存页表中,而非共享同一页表。这会增加指令 TLB 的负担。如前文所述,为代码缓存启用透明大页 (THP) 可通过减少所需页表项的数量来缓解此问题。因此,在使用热点 nmethod 段时,应启用该功能。
CPU 系统寄存器配置
Arm Neoverse 核心提供了若干硬件寄存器,用于调控 CPU 缓存行为。在 Neoverse N2 中,IMP_CPUECTLR_EL1 寄存器包含多个字段,这些字段会影响指令获取过程中 L2 缓存的使用方式。
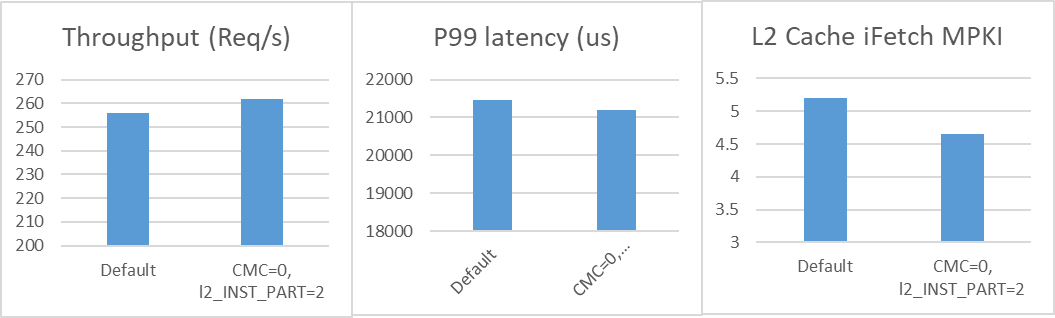
CMC_MIN_WAYS 能够限制 CMC 预取可使用的 L2 缓存路数。其默认值为 2,即 CMC 必须为 L2 缓存中的数据保留至少 2 路。在前端瓶颈场景中,将该值设为 0 可预留更多 L2 缓存用于指令获取。
L2_INST_PART 可将部分 L2 缓存专门预留用于存储指令,默认处于禁用状态。启用这一专用空间能够提高指令获取时的缓存命中率。
在代码膨胀实验中,将 CMC_MIN_WAYS 设为 0 且 L2_INST_PART 设为 2 后,吞吐量和延迟均得到显著改善。
总 结
针对 Arm Neoverse CPU 上大代码量 Java 应用的性能测试与调优表明,过大的代码缓存会显著影响 CPU 前端效率。代码缓存膨胀实验显示,由于 CPU 缓存、TLB 和分支预测单元等前端资源的压力陡增,性能出现了明显下降。
为解决这些瓶颈,我们建议多项软件优化方案,包括:
将数据移出代码缓存,减小已编译方法的内存占用。
为 JVM 代码缓存堆启用 THP。
引入专用热点方法段,提升空间局部性。
配置 CPU 寄存器,为指令获取预留更多缓存空间。
这些方法能够改善大代码量 Java 应用的性能。在 DaCapo 基准测试中,部分方法在代码膨胀 10 倍的情况下,仍实现了吞吐量和延迟的改善。这些优化与配置可显著缓解由大代码缓存导致的前端瓶颈,进而提升 Neoverse CPU 上 Java 工作负载的执行效率。
-
如何在Arm Neoverse N2平台上提升llama.cpp扩展性能2026-02-11 455
-
如何在基于Arm Neoverse平台的CPU上构建分布式Kubernetes集群2025-03-25 981
-
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N32024-04-24 3379
-
Arm Neoverse CSS V3 助力云计算实现 TCO 优化的机密计算2024-03-26 1058
-
Arm发布Neoverse V3和N3 CPU内核2024-02-27 3132
-
Arm 更新 Neoverse 产品路线图,实现基于 Arm 平台的人工智能基础设施2024-02-22 1032
-
智原与Arm合作提供基于Arm Neoverse CSS的设计服务2024-01-10 1823
-
Arm Neoverse™ N1 PMU指南2023-08-12 918
-
Arm Neoverse N1软件优化指南2023-08-11 734
-
ARM Neoverse N1 Core性能分析方法2023-08-09 659
-
ARM Neoverse系列服务器CPU研究分析2023-06-12 5864
-
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用2022-08-31 3944
-
ARM Neoverse IP的AWS实例上etcd分布式键对值存储性能提升2022-07-06 7222
-
Arm Neoverse NVIDIA Grace CPU 超级芯片:为人工智能的未来设定步伐2022-03-29 5167
全部0条评论

快来发表一下你的评论吧 !
