

如何在NVIDIA Jetson AGX Thor上通过Docker高效部署vLLM推理服务
描述
继系统安装与环境配置后,本期我们将继续带大家深入 NVIDIA Jetson AGX Thor 的开发教程之旅,了解如何在 Jetson AGX Thor 上,通过 Docker 高效部署 vLLM 推理服务。
具体内容包括:
vLLM 简介与优势
vLLM Docker 容器构建
使用 vLLM 在线下载模型
使用 vLLM 运行本地模型
使用 Chatbox 作为前端调用 vLLM 运行的模型
一、vLLM 简介与优势
1什么是 vLLM?
vLLM 是一个高效的大语言模型推理和服务引擎,专门优化了注意力机制和内存管理,能够提供极高的吞吐量。
2在 Jetson AGX Thor 上运行 vLLM 的优势:
PagedAttention 技术:显著减少内存碎片,提高 GPU 利用率
Continuous Batching 机制:能够连续动态处理不同长度的请求
开源生态:支持主流开源模型(Llama、Qwen、ChatGLM 等)
二、vLLM Docker 容器构建
在上一期 NVIDIA Jetson AGX Thor Developer Kit 开发环境配置教程中,我们已经完成了 Docker 的安装与配置,现在,只需要使用 Docker 拉取 vLLM 镜像即可。

当前 Docker 版本
1. 参照上期教程介绍的方法,注册并登录 NGC 之后,搜索 vLLM 进入容器页面,点击“Get Container”,复制镜像目录。
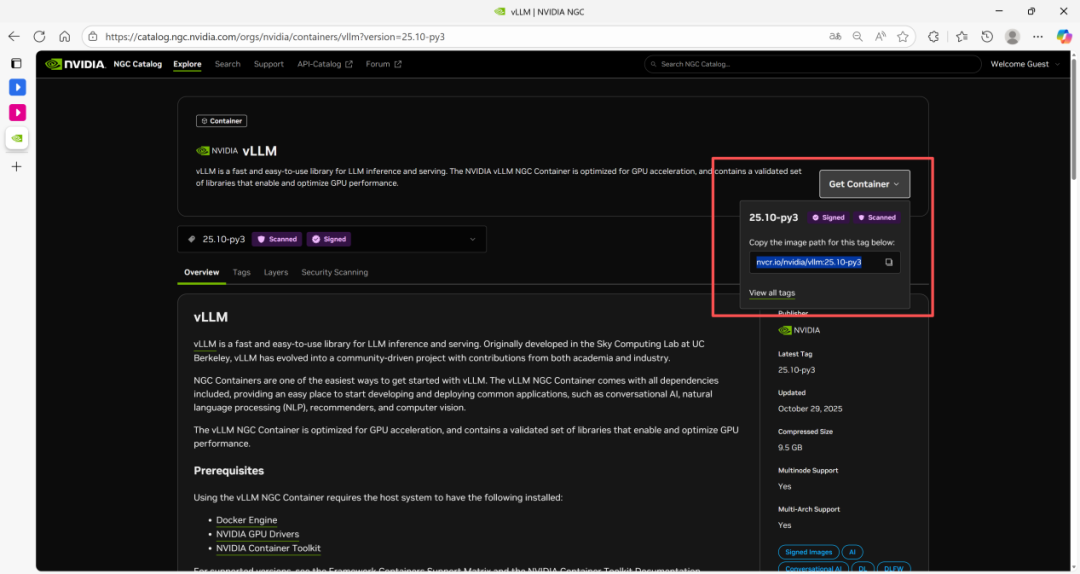
2. 在命令行运行 docker pull nvcr.io/nvidia/vllm:25.10-py3 下载镜像。

3. 下载完成后,运行容器,创建启动命令。
sudo docker run -d -t --net=host --gpus all --ipc=host --name vllm -v /data:/data --restart=unless-stopped nvcr.io/nvidia/vllm:25.10-py3
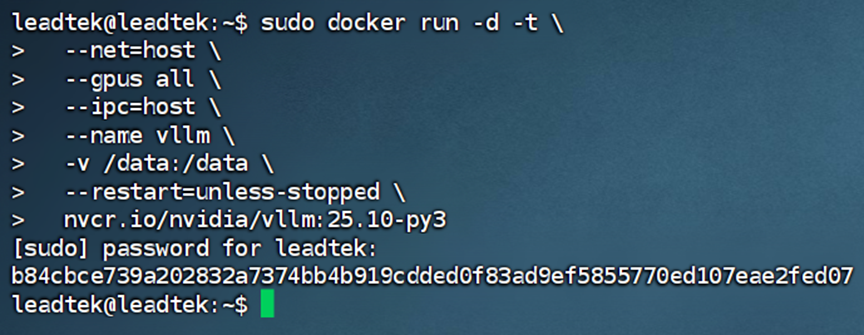
注:关键参数说明
-d (detach):后台运行容器
-t (tty):分配一个伪终端,方便日志输出
--name vllm:为容器指定名称"vllm"
--net=host:使用主机网络模式,容器与主机共享网络命名空间
--gpus all:将所有可用的 GPU 设备暴露给容器
--ipc=host:使用主机的 IPC 命名空间,改善进程间通信性能
-v /data:/data:将主机的 /data 目录挂载到容器的 /data 目录,后面可用于持久化模型文件、配置文件等数据
--restart=unless-stopped:Docker 容器的重启策略参数,表示容器在非人工主动停止时(如崩溃、宿主机重启),会自动重启,但若被手动停止,则不会自动恢复
4. 容器创建成功后,使用 docker exec -it vllm /bin/bash 命令进入此容器。

三、使用 vLLM 在线下载模型
1. 从 Hugging Face 上下载模型权重:
通常默认的模型下载目录为:.cache/huggingface/hub/,通过设置环境变量,我们将指定模型下载到:export HF_HOME=/data/huggingface 目录,然后执行 vllm serve "Qwen/Qwen2.5-Math-1.5B-Instruct",此命令会从 Hugging Face 上在线拉取下载模型并开始运行。
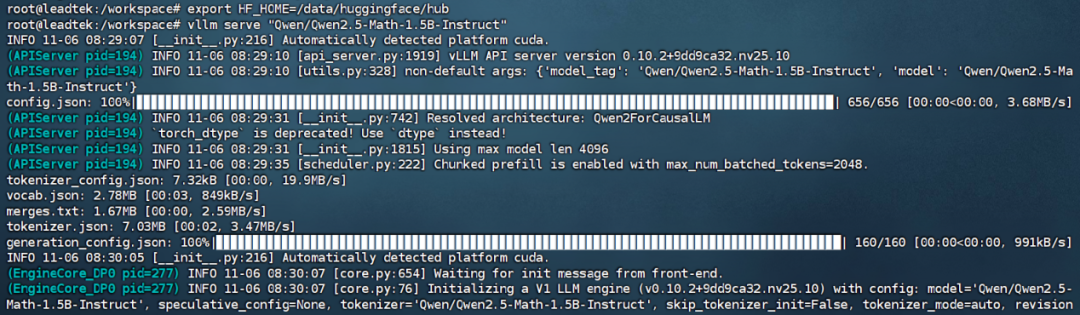
2. 等待模型文件下载完成(需科学上网)。
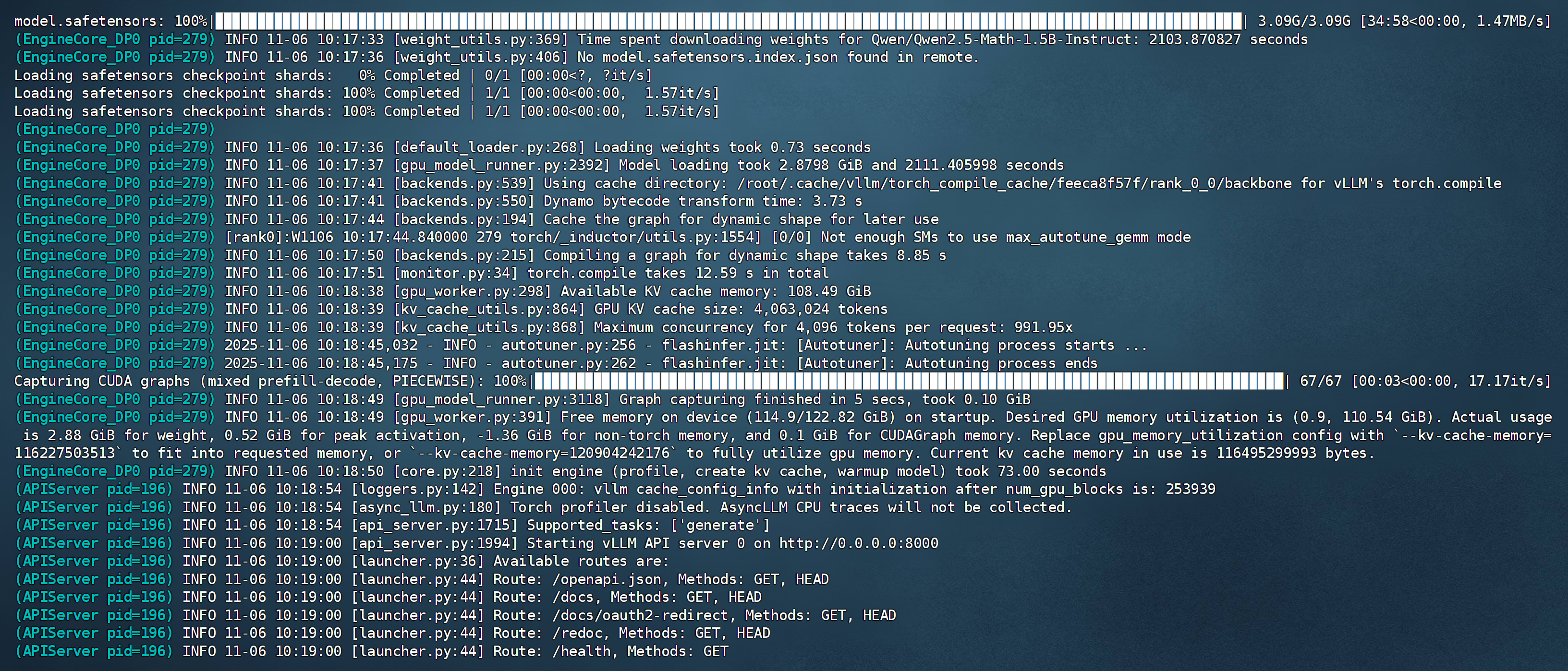
注:为方便后续调用,建议通过本地终端确认模型已下载到预设目录(如下图所示)。
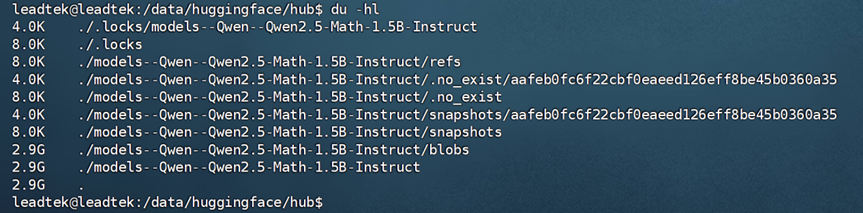
在没有前端的情况下,可以通过 curl 命令向 vLLM 服务发送聊天请求。
curl http://localhost:8000/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "Qwen/Qwen2.5-Math-1.5B-Instruct",
"messages": [{"role": "user", "content": "12*17"}],
"max_tokens": 500
}'

注:关键参数说明
curl:命令行工具,用于传输数据
http://localhost:8000:本地服务器地址和端口
/v1/chat/completions:OpenAI 兼容的聊天补全 API 端点
-H:设置 HTTP 请求头
"Content-Type:application/json":指定请求体为 JSON 格式
-d:设置请求数据
"model":"Qwen/Qwen2.5-Math-1.5B-Instruct":指定要使用的模型,这个名称应该与 vLLM 服务启动时指定的模型名称一致
"messages:[{"role": "user", "content": "12*17"}]:定义对话历史和当前消息
消息对象字段:"role" 指消息角色;"user"指用户消息,"Content"指消息具体内容;"12*17"指用户提出的数学问题
"max_tokens":500:限制模型生成的最大 token 数量
四、使用 vLLM 运行本地模型
如前所述,模型已下载保存至本地指定目录,可以直接通过其路径启动服务。
以上方“Qwen/Qwen2.5-Math-1.5B-Instruct”为例,该模型权重路径为:
“/data/huggingface/hub/models--Qwen--Qwen2.5-Math-1.5B-Instruct/snapshots/aafeb0fc6f22cbf0eaeed126eff8be45b0360a35”。

执行以下命令,即可正常运行本地模型。
vllm serve /data/huggingface/hub/models--Qwen--Qwen2.5-Math-1.5B-Instruct/snapshots/aafeb0fc6f22cbf0eaeed126eff8be45b0360a35
五、使用 Chatbox 作为前端调用 vLLM 运行的模型
1. 局域网内访问 Chatbox 官网(https://chatboxai.app),下载并安装 Windows 版本。
2. 点击“设置提供方” — “添加”,输入名称,再次点击“添加”。
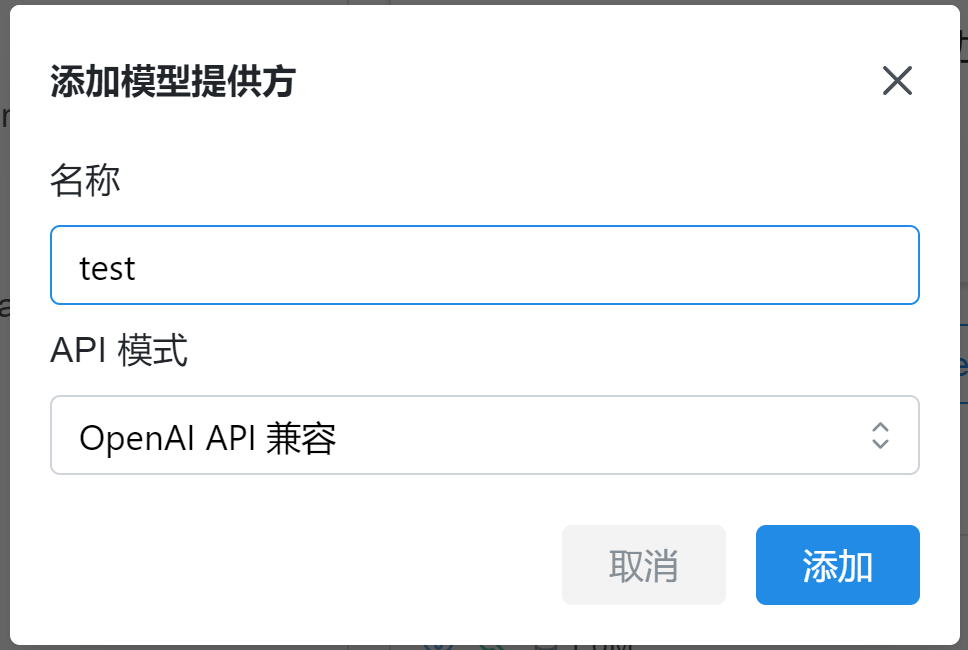
上下滑动 点击查看
3. API 主机可输入 Jetson AGX Thor 主机 IP 以及 vLLM 服务端口号。
(例:http://192.168.23.107:8000)
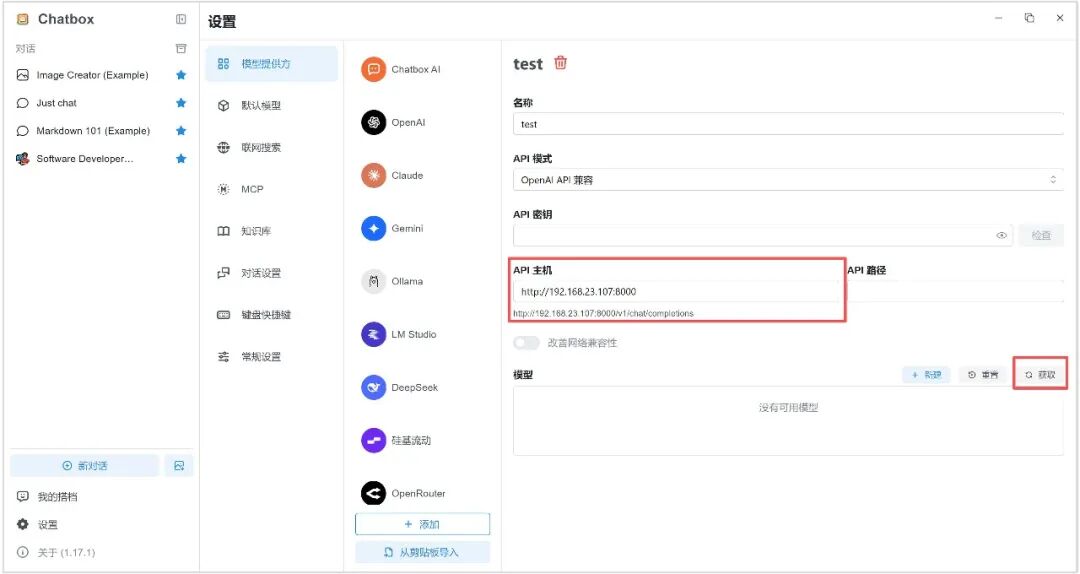
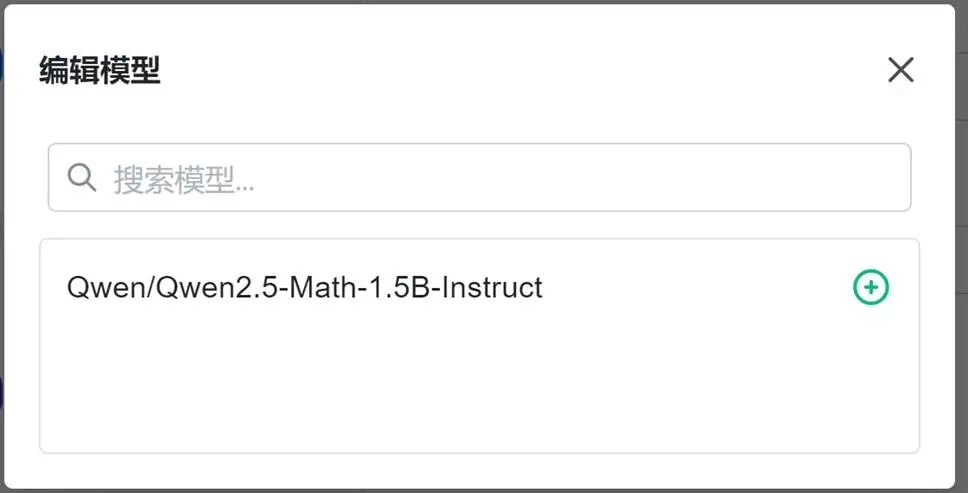
4. 选择 vLLM 运行的模型,点击“+”。
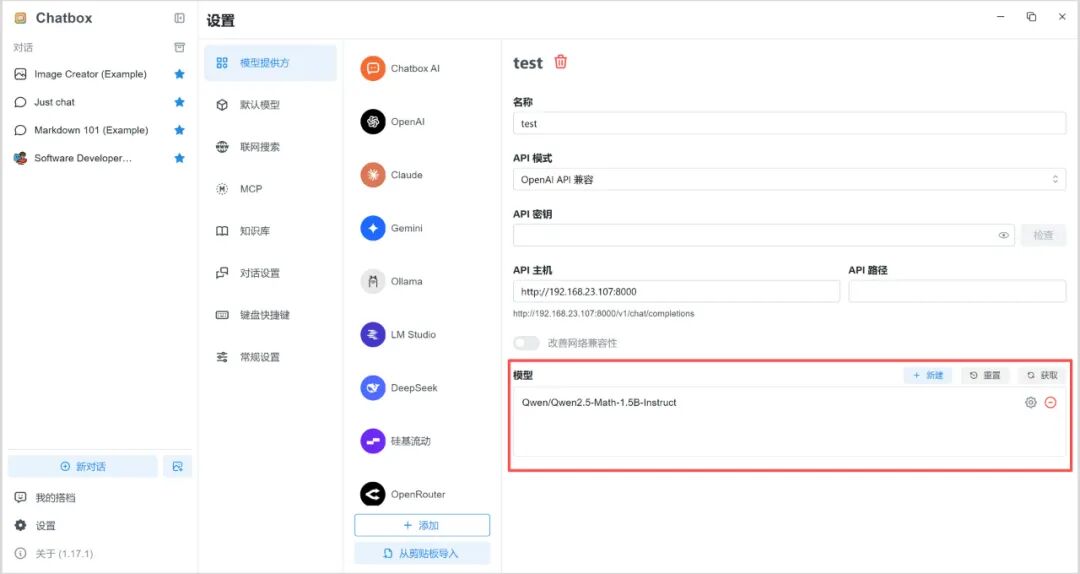
5. 点击“新对话”,右下角选择该模型即可开启对话。
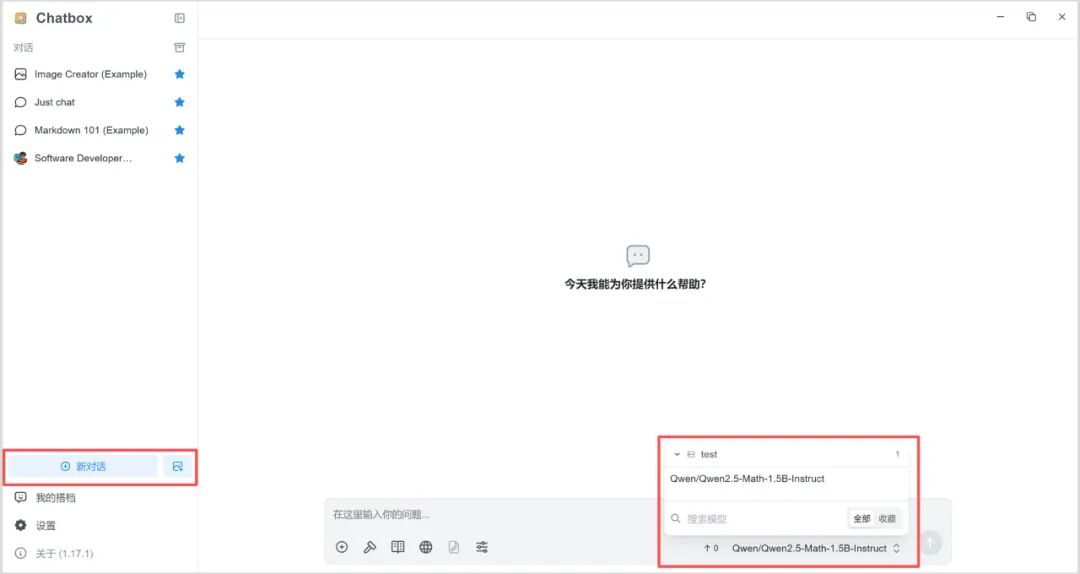
6. 运行示例
由于 Qwen2.5-Math 是一款数学专项大语言模型,我们在此示例提问一个数学问题,运行结果如下:
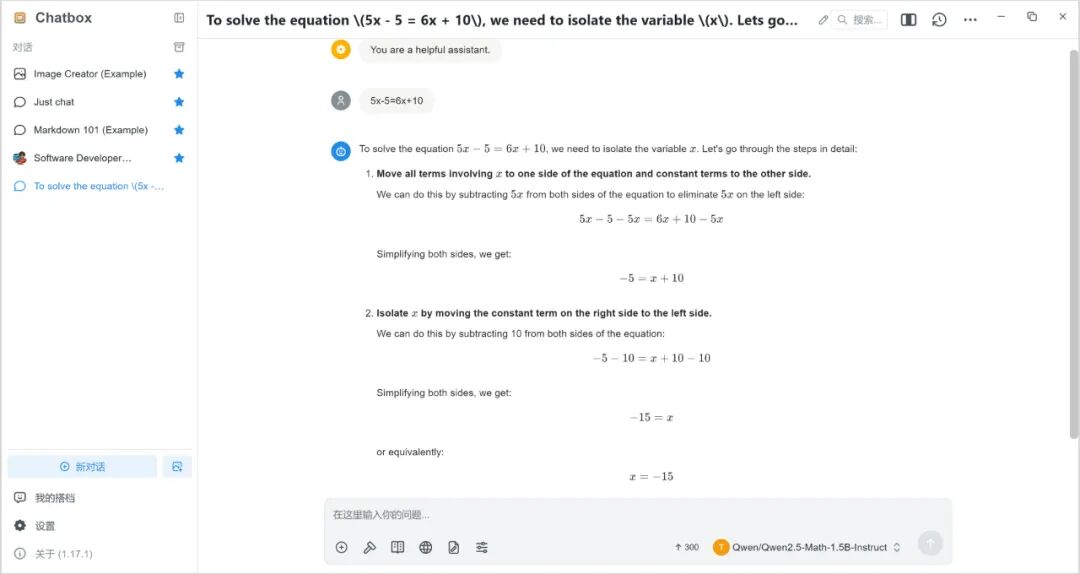
更多精彩教程,敬请期待!
-
NVIDIA Jetson AGX Thor Developer Kit开发环境配置指南2025-11-08 7917
-
如何在NVIDIA Jetson AGX Thor上部署1200亿参数大模型2025-12-26 5480
-
怎么做才能通过Jetson Xavier AGX构建android图像呢?2023-06-07 753
-
NVIDIA Jetson AGX Orin提升边缘AI标杆2022-04-09 2919
-
使用NVIDIA Jetson AGX Xavier部署新的自主机器2022-04-18 8284
-
NVIDIA 推出 Jetson AGX Orin 工业级模块助力边缘 AI2023-06-05 2518
-
利用 NVIDIA Jetson 实现生成式 AI2023-11-07 2650
-
NVIDIA Jetson AGX Thor开发者套件概述2025-08-11 2190
-
基于 NVIDIA Blackwell 的 Jetson Thor 现已发售,加速通用机器人时代的到来2025-08-26 1422
-
NVIDIA三台计算机解决方案如何协同助力机器人技术2025-08-27 2766
-
NVIDIA Jetson AGX Thor开发者套件重磅发布2025-08-28 1899
-
ADI借助NVIDIA Jetson Thor平台加速人形机器人研发进程2025-08-29 3693
-
通过NVIDIA Jetson AGX Thor实现7倍生成式AI性能2025-10-29 1869
-
NVIDIA Jetson系列开发者套件助力打造面向未来的智能机器人2025-12-13 3584
-
K8s部署vLLM推理服务详细步骤2026-03-13 867
全部0条评论

快来发表一下你的评论吧 !
