

一种名为“普适注意力”的新翻译模型,用2D卷积网络做序列预测
电子说
描述
目前的机器翻译模型基于编码器-解码器系统结构,本文提出了一种名为“普适注意力”的新翻译模型,用2D卷积网络做序列预测,无论长句短句翻译结果都更好,使用的参数也更少。实验表明,新模型的总体表现优于目前最出色的解码器-编码器模型系统。
目前,最先进的机器翻译系统基于编码器-解码器架构,首先对输入序列进行编码,然后根据输入编码生成输出序列。两者都与注意机制接口有关,该机制基于解码器状态,对源令牌的固定编码进行重新组合。
本文提出了一种替代方法,该方法于跨两个序列的单个2D卷积神经网络。网络的每一层都根据当前的输出序列重新编码源令牌。因此,类似注意力的属性在整个网络中普遍存在。我们的模型在实验中表现出色,优于目前最先进的编码器-解码器系统,同时在概念上更简单,参数更少。
“普适注意力”模型及原理
我们的模型中的卷积层使用隐性3×3滤波器,特征仅根据先前的输出符号计算。图为经过一层(深蓝色)和两层(浅蓝色)计算之后的感受野,以及正常3×3滤波器(灰色)的视野的隐藏部分。
上图为具有两个隐藏层的解码器网络拓扑的图示,底部和顶部的节点分别表示输入和输出。水平方向连接用于RNN,对角线方向连接用于卷积网络。在两种情况下都会使用垂直方向的连接。参数跨时间步长(水平方向)共享,但不跨层(垂直方向)共享。

块级(顶部)和每个块(底部)内的DenseNet体系结构

令牌嵌入大小、层数(L)和增长率(g)的影响
无论是长句、短句,翻译结果都更好
与现有最佳技术的比较
我们将结果与表3中的现有技术进行了比较,包括德-英翻译(De-En)和英-德翻译(En-De)。我们的模型名为Pervasive Attention。除非另有说明,我们使用最大似然估计(MLE)训练所有模型的参数。对于一些模型,我们会另外报告通过序列水平估计(SLE,如强化学习方法)获得的结果,我们通常直接针对优化BLEU量度,而不是正确翻译的概率。
在不同句子序列长度上的表现
在上图中,我们将翻译质量视为句子长度的函数,并将我们的模型与RNNsearch、ConvS2S和Transformer进行比较。结果表明,我们的模型几乎在所有句子长度上都得到了最好的结果,ConvS2S和Transformer只在最长的句子上表现更好。总的来说,我们的模型兼备RNNsearch在短句中的强大表现,同时也接近ConvS2S和Transformer在较长句子上的良好表现。
隐性的句子对齐

上图所示为最大池化运算符在我们的模型中生成的隐式句子对齐。作为参考,我们还展示了我们的模型使用的“自我注意力”产生的对齐。可以看到,两种模型都成功定性地模拟了隐性的句子对齐。
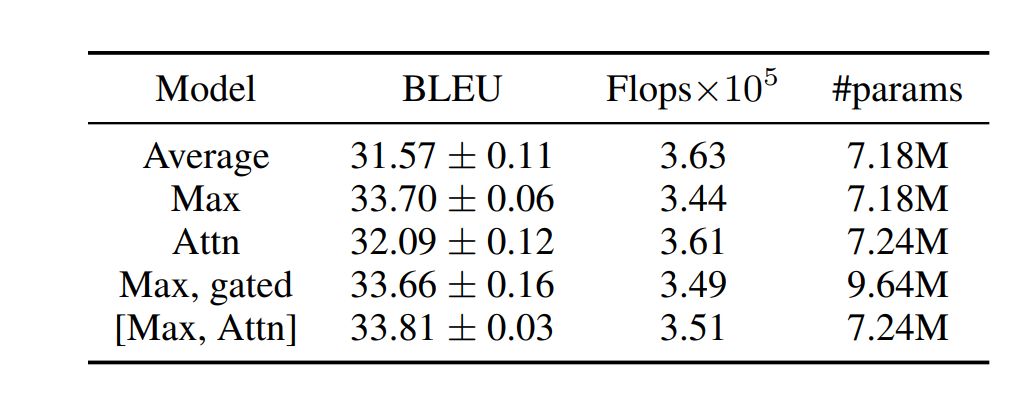
我们的模型(L = 24,g = 32,ds = dt = 128),具有不同的池化操作符,使用门控卷积单元

在不同的滤波器尺寸k和深度L下,我们的模型(g = 32,ds = dt = 128)的表现。
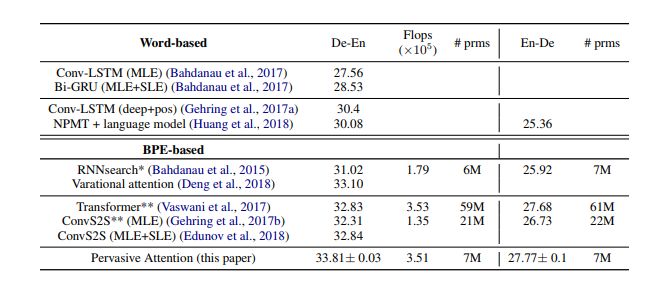
与IWSLT德语-英语翻译模型的最新结果的比较。
(*):使用我们的实现获得的结果 (**):使用FairSeq获得的结果。
脱离编码器-解码器范式,用DenseNet作机器翻译
我们提出了一种新的神经机器翻译架构,该架构脱离了编码器-解码器范例。我们的模型将源序列和目标序列联合编码为深度特征层次结构,其中源令牌嵌入到部分目标序列的上下文中。沿源维度对此联合编码进行最大池化,将相关要素映射到下一个目标令牌的预测。该模型实现基于DenseNet的2D CNN。
由于我们的模型会结合语境,对每一层当前生成的目标序列的输入令牌重新编码,因此该模型网络构造的每层中都具有“类似注意力”(attention-like)的属性。
因此,添加明确的“自注意模块”具有非常有限、但十分积极的效果。然而,我们模型中的最大池化运算符生成的隐式句子对齐,在性质上与注意力机制生成的对齐类似。我们在IWSLT'14数据集上评估了我们的模型,将德-英双语互译。
我们获得的BLEU分数与现有最佳方法相当,我们的模型使用的参数更少,概念上也更简单。我们希望这一成果可以引发对编码器-解码器模型的替代方案的兴趣。在未来,我们计划研究混合方法,其中联合编码模型的输入不是由嵌入向量提供的,而是1D源和目标嵌入网络的输出。
未来我们还将研究如何该模型来跨多语种进行翻译。
-
一种基于因果路径的层次图卷积注意力网络2024-11-12 1727
-
一种新的深度注意力算法2023-05-24 447
-
探索一种降低ViT模型训练成本的方法2022-11-24 1425
-
卷积神经网络模型发展及应用2022-08-02 13209
-
基于注意力机制等的社交网络热度预测模型2021-06-07 810
-
基于视觉注意力的全卷积网络3D内容生成方法2021-05-13 1023
-
基于循环卷积注意力模型的文本情感分类方法2021-04-14 893
-
基于多层CNN和注意力机制的文本摘要模型2021-04-07 982
-
基于深度图注意力卷积CNN的三维模型识别方法2021-04-02 1173
-
一种注意力增强的自然语言推理模型aESIM2021-03-25 1095
-
基于注意力机制的深度学习模型AT-DPCNN2021-03-17 1148
-
循环神经网络卷积神经网络注意力文本生成变换器编码器序列表征2019-07-19 3864
-
一种新的神经机器翻译架构,它脱离了编码器-解码器的范畴2018-08-23 3882
-
北大研究者创建了一种注意力生成对抗网络2018-08-11 5512
全部0条评论

快来发表一下你的评论吧 !
