

一种图像语义分层处理框架,可以实现像素级别的图像语义理解和操纵
电子说
描述
密歇根大学和谷歌大脑的研究人员合作,提出了一种图像语义分层处理框架,可以实现像素级别的图像语义理解和操纵,在图像中任意添加、改变、移动对象,并与原图浑然一体,实现真正的“毫无PS痕迹”。
曾经,你以为下面普京×容嬷嬷那张图就称得上“毫无PS痕迹”了。
的确,用肉眼看,效果是很不错。但是,在专业的图像分析软件下,修改的痕迹一目了然。
你再看看这两张图:
不不不,这不是“找不同”,是为了让你感受一下“像素级语义分割和理解”带来的修图效果:
可能,你需要看得更清晰一点。
看好了哦,这是原图:
发现有什么不同/不自然的地方了吗?(提示:一共有7处不同)。
先别急着往下拉……
答案揭晓:
实际上,找出不同是很简单的(毕竟多了好几个东西),关键是这样像素级的改动,比原先意义上“毫无PS痕迹”增强了一大步!
无论是色调、光线还是纹理,都与原图配合得更加自然,操作起来也十分简单方便。
这多亏了密歇根大学和谷歌大脑的研究人员,他们提出了一种新的图像语义处理分层框架,首先根据图像中给定对象的边界框,学习生成像素级语义标签地图(pixel-wise semantic label maps),然后根据这个地图再生成新的图像。
因此,用户可以实现对象级的操纵,无论是改变颜色、移动位置、去除某个物体,增加新的东西,或者把原来在最前面的人物往后移一层或两层,而且与原图像自然融为一体。
操作只需要一步即可:
图像语义分层处理框架工作流程图示意:输入车道照片,输出上面有一辆车的照片
定量和定性结果分析,该方法比当前流行的Context Encoder、Pix2PixHD等效果都要高出许多。这有望掀起计算机视觉和图像处理界的巨变,难怪有人看完后在Twitter留言:
“在我两年前开始学计算机视觉时,这种技术简直是无法想象的。”“简直是科幻变成了现实!”
还有人疾呼:PS里有个功能我想在就想要!
像素级分层语义处理框架,实现图片对象自然修改
想必大家看到这个神级PS技术,对其原理应该是十分好奇了吧!接下来,小编就带着读者领略这款神技的技术奥秘!
正如上述所言,这个PS技术框架的核心就是分层图像处理。
当给出新的边界框B时,算法首先通过以B为中心、尺寸为S×S的裁剪平方窗口,提取标签映射(semantic label map)M∈RS×S×C和图像I∈RS×S×3的局部观测值。 在M,I和B上,模型通过以下过程生成操纵图像:
给定边界框B和语义标签映射M,结构生成器通过
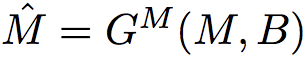
给定操纵的标签映射M和图像I,图像生成器通过
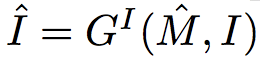
而在分层图像处理过程中,有两个核心的关键步骤:
结构生成器(Structure Generator)
结构生成器的目标是以像素级类标签M∈RS×S×C的形式推断由B = {b,c}指定的区域的潜在结构。
结构生成器的体系结构
给定一个masked layout M和一个binary mask B,分别用于对目标的类和位置进行编码。该模型通过来自双流解码器( two-stream decoder)的输出产生M(该双流解码器对应于box整个区域中对象的二进制掩码和语义标签映射)。
图像生成器(Image Generator)
给定一张图像I和从结构生成器中获得的可操纵layout M,图像生成器输出区域内由B定义的、内容的像素级预测。
图像生成器的体系结构
给定一张masked图像I和语义layout M,该模型使用单独的编码路径对对象的视觉样式和语义结构进行编码,并产生被操纵的图像。
超越当前最好标准,从此修图随心所欲
定量评估
Ablation Study。 为了分析所提方法的有效性,对该方法的几种变体进行了Ablation Study。 首先考虑图像生成器的三个基线:
仅限于图像上下文(SingleStream-Image);
仅限于语义布局(SingleStream-Layout);
对上述两个基线的结合。
结果如下表所示:

下图显示了基线的定性比较:
定性分析
语义对象处理
通过将汽车的同一个边界框移动到图像中的不同位置来展示操作结果
从图中可以看到,当把车的边框从一边移动到另一边的时候,模型所产生的车辆外观发生了变化。有趣的是,汽车的形状、方向和外观也会根据周围区域的场景布局和阴影而改变。
在更多样化的上下文中生成的结果
该结果表明,模型在考虑上下文的情况下生成了合适的对象结构和外观。除了生成与周围环境相匹配的对象外,还可以对框架轻松地进行扩展,允许用户直接控制对象样式。
扩展式操作
用样式向量控制对象颜色
结果表明,模型成功地合成了具有指定颜色的各种对象,同时保持图像的其他部分不变。
交互式和数据驱动的图像编辑
图像编辑是该模型的关键点之一。通过添加、删除和移动对象边界框来执行交互式图像处理。 结果如下图所示:
在图像中对多对象进行处理的例子
表明该方法生成合理的语义布局和图像,可以平滑地增加原始图像的内容。除了交互式操作之外,还可以通过以数据驱动的方式对图像中的边界框进行采样来自动化操作过程。 结果如下图所示:
数据驱动的图像操作示例
室内场景数据集的实验结果
使用ADE20K数据集对卧室图像进行定性实验。 下图展示了了交互式图像处理结果。
室内图像处理的示例
由于室内图像中的对象涉及更多样化的类别和外观,因此生成与场景中的其他组件对齐的适当对象形状和纹理比街道图像更具挑战性。
可以看出,该方法生成的对象与周围环境可以保持高度一致性。
-
一种基于超像素的户外建筑图像布局标定方法2010-04-24 2219
-
语义机器人2016-03-10 5693
-
NLPIR语义分析是对自然语言处理的完美理解2018-10-19 2975
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 2580
-
面向智能服务系统的时间语义理解2018-04-19 1174
-
如何对互联网图像实现像素级别的语义识别2018-06-27 5175
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1012
-
如何使用语义感知来进行图像美学质量评估的方法2018-11-16 1326
-
如何使用知识图谱对图像语义进行分析技术及应用研究2018-11-21 1938
-
一种基于框架特征的共指消解方法2021-03-19 1444
-
一种具有语义区域风格约束的图像生成框架2021-04-13 992
-
基于SEGNET模型的图像语义分割方法2021-05-27 928
-
语义分割模型 SegNeXt方法概述2022-09-27 4787
-
图像分割与语义分割中的CNN模型综述2024-07-09 3389
-
图像语义分割的实用性是什么2024-07-17 1675
全部0条评论

快来发表一下你的评论吧 !
