

 瑞芯微RKNPU开发全指南:从环境搭建到性能优化,一文搞定边缘AI部署
瑞芯微RKNPU开发全指南:从环境搭建到性能优化,一文搞定边缘AI部署
电子说
描述
在边缘 AI 领域,瑞芯微(Rockchip)的 RKNPU 凭借高性能、低功耗的特性,成为很多嵌入式开发者的首选。无论是 RK3588 的 3 核 NPU(算力达 6TOPS),还是 RV1106 的轻量化 NPU,都需要通过RKNN SDK实现模型部署。今天这篇文章,我们就从 SDK 核心组件、开发全流程、进阶优化到避坑指南,手把手教你搞定 RKNPU 开发!
一、先搞懂:RKNN SDK 核心组件
RKNN SDK 不是单一工具,而是一套 “PC 端工具链 + 板端运行时” 的完整生态。先理清这 3 个核心组件的分工,后续开发才不会乱:
1. 核心组件交互图
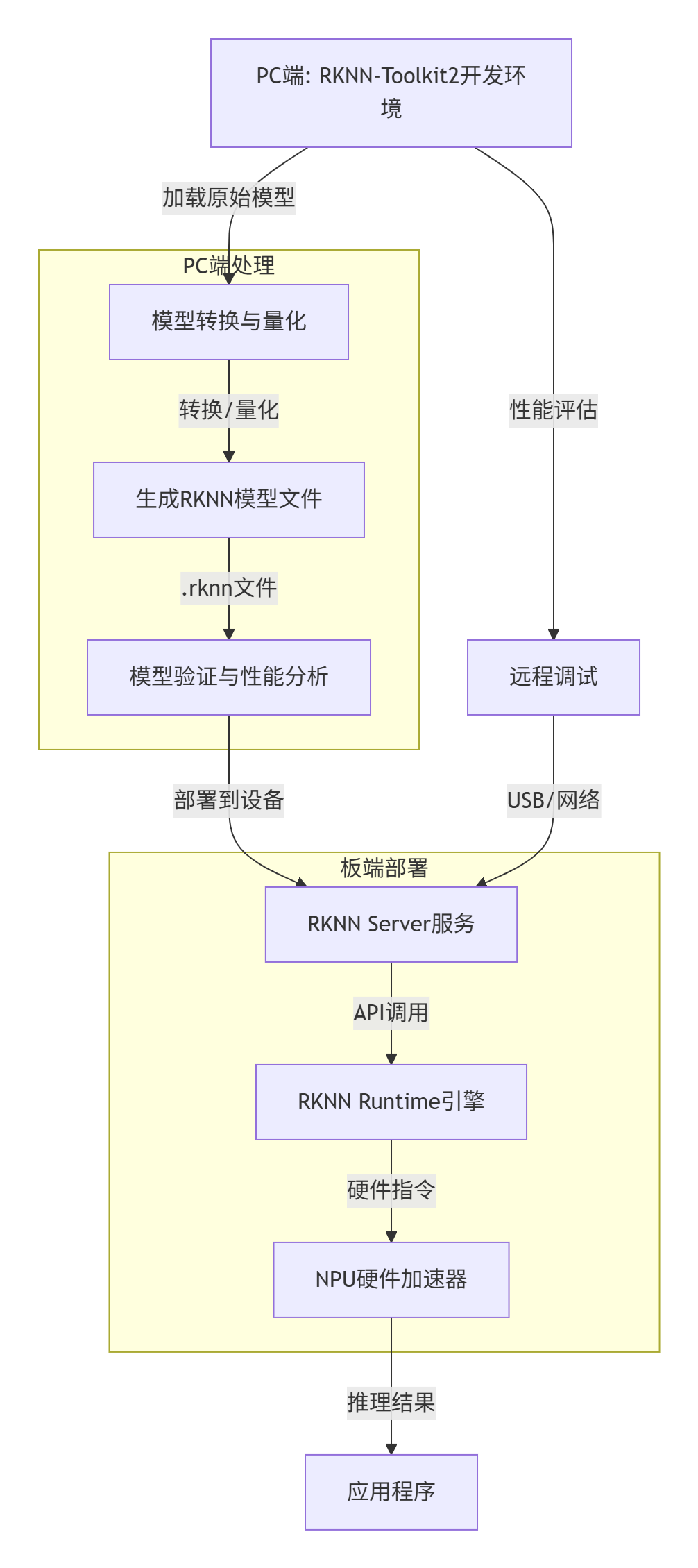
2. 组件详解
•RKNN-Toolkit2(PC 端)
开发者的“模型加工厂”,主要负责:
◦模型转换:支持 ONNX、PyTorch、TensorFlow 等主流框架转 RKNN 格式;
◦量化优化:将 FP32 模型量化为 INT8(支持 Normal/KL-Divergence/MMSE 三种算法),减小模型体积、提升推理速度;
◦评估分析:在模拟器或连板状态下,分析模型精度(余弦距离)、性能(单帧耗时)、内存(权重 / 中间 Tensor 占用)。
•RKNN Runtime(板端)
模型的“推理引擎”,分两种 API:
◦通用 API:易上手,数据预处理(归一化、格式转换)在 CPU 完成,适合快速验证;
◦零拷贝 API:高性能,预处理在 NPU 完成,数据无需 CPU-NPU 拷贝(直接用物理地址 /fd),适合摄像头、视频解码等低延迟场景。
•RKNN Server(板端)
连板调试的“桥梁”,运行在开发板后台,接收 PC 端 Toolkit2 的指令,转发数据 / 推理结果,支持多设备管理。
二、开发全流程:从 0 到 1 部署一个模型
以“MobileNet 图像分类模型” 为例,带大家走一遍完整开发流程,关键步骤附实操代码和注意事项:
1. 开发全流程图表

2. step 1:环境准备
(1)PC 端:安装 RKNN-Toolkit2
推荐用 Docker(避免环境冲突),命令如下:
# 1. 安装Docker并添加用户组sudo groupadd dockersudo usermod -aG docker $USERnewgrp docker# 2. 加载RKNN-Toolkit2镜像(镜像从瑞芯微网盘下载)docker load --input rknn-toolkit2-x.x.x-cpxx-docker.tar.gz# 3. 启动容器(映射USB和示例代码)docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /your/examples:/examples rknn-toolkit2:x.x.x-cpxx /bin/bash
(2)板端:确认 NPU 环境
开发板必须满足 3 个条件:
•NPU 驱动版本≥0.9.2(查询命令:cat /sys/kernel/debug/rknn/driver_version);
•RKNN Server 已启动(查询命令:ps | grep rknn_server,未启动则执行restart_rknn.sh);
•Runtime 库版本与 Toolkit2 匹配(如 Toolkit2 v2.0.0 需 librknnrt.so v2.0.0)。
3. step 2:模型转换(核心步骤)
以 ONNX 模型为例,用 Toolkit2 的 Python 接口实现转换:
from rknn.api import RKNN# 1. 初始化RKNN对象rknn = RKNN(verbose=True)# 2. 配置转换参数(目标平台、均值/归一化、量化)rknn.config(mean_values=[[103.94, 116.78, 123.68]], # 与训练时一致std_values=[[58.82, 58.82, 58.82]],target_platform='rk3588', # 目标硬件(如rk3566、rv1106)quantized_algorithm='normal', # 量化算法do_quantization=True # 开启量化)# 3. 加载ONNX模型ret = rknn.load_onnx(model='./mobilenet_v2.onnx')# 4. 量化构建(需准备校正集dataset.txt,每行1张图片路径)ret = rknn.build(do_quantization=True, dataset='./dataset.txt')# 5. 导出RKNN模型ret = rknn.export_rknn('./mobilenet_v2.rknn')# 6. 释放资源rknn.release()
关键注意点:
•校正集(dataset.txt)需覆盖业务场景(如分类模型需包含所有类别图片),数量建议 20-200 张;
•目标平台(target_platform)必须与开发板一致,否则模型无法运行(RK3566/3568 通用,RK3588/3588S 通用)。
4. step 3:模型评估(避坑关键)
转换后的模型,必须先评估再部署,避免“能跑但精度 / 性能不达标”:
# 1. 初始化运行时(连板评估,target设为开发板型号)ret = rknn.init_runtime(target='rk3588', device_id='515e9b401c060c0b')# 2. 精度分析(对比量化模型与浮点模型的每层误差)ret = rknn.accuracy_analysis(inputs=['./test.jpg'], target='rk3588')# 3. 性能评估(输出单帧耗时、FPS、每层算子耗时)perf_detail = rknn.eval_perf()# 4. 内存评估(输出权重、中间Tensor内存占用)mem_detail = rknn.eval_memory()
评估结果解读:
•精度:余弦距离越接近 1(如 0.999),误差越小;
•性能:RK3588 运行 MobileNetV2,INT8 量化后 FPS 可达 100+;
•内存:权重内存≈3.5MB,总内存≈5.4MB(符合边缘设备需求)。
5. step 4:板端部署(C/Python 任选)
(1)Python 部署(快速验证,用 RKNN-Toolkit Lite2)
from rknn.api import RKNNLite# 1. 初始化RKNNLite对象rknn_lite = RKNNLite(verbose=True)# 2. 加载RKNN模型ret = rknn_lite.load_rknn('./mobilenet_v2.rknn')# 3. 初始化运行时(多核配置:RK3588可设NPU_CORE_0_1_2)ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_ALL)# 4. 预处理输入图片img = cv2.imread('./test.jpg')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = np.expand_dims(img, 0)# 5. 推理outputs = rknn_lite.inference(inputs=[img])# 6. 后处理(输出TOP5类别)show_top5(outputs)# 7. 释放资源rknn_lite.release()
(2)C 部署(高性能,用 RKNN Runtime)
核心流程:初始化模型→设置输入→推理→获取输出→释放资源,关键代码片段:
int main() {rknn_context ctx;// 1. 初始化模型ret = rknn_init(&ctx, model_buf, model_len, 0, NULL);// 2. 查询输入输出属性rknn_input_output_num io_num;rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));// 3. 设置输入数据rknn_input inputs[io_num.n_input];inputs[0].index = 0;inputs[0].type = RKNN_TENSOR_UINT8;inputs[0].fmt = RKNN_TENSOR_NHWC;inputs[0].buf = img_data;inputs[0].size = img_size;rknn_inputs_set(ctx, io_num.n_input, inputs);// 4. 推理rknn_run(ctx, NULL);// 5. 获取输出rknn_output outputs[io_num.n_output];rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);// 6. 后处理post_process(outputs);// 7. 释放资源rknn_outputs_release(ctx, io_num.n_output, outputs);rknn_destroy(ctx);return 0;}
三、进阶优化:让模型跑更快、更省内存
掌握以下技巧,能让 RKNPU 性能翻倍、内存占用减半,尤其适合边缘设备:
1. 性能优化
(1)NPU 多核配置(RK3588/RK3576 专属)
RK3588 有 3 个 NPU 核,RK3576 有 2 个,通过core_mask设置多核运行:
# Python(Toolkit2)rknn.init_runtime(target='rk3588', core_mask=RKNN.NPU_CORE_0_1_2)# C APIrknn_set_core_mask(ctx, RKNN_NPU_CORE_0_1_2);
效果:MobileNetV2 在 RK3588 上,多核运行比单核快 2.5 倍。
(2)零拷贝 API(减少 DDR 带宽消耗)
适合摄像头、视频解码等场景,数据直接用物理地址:
// 1. 创建外部分配内存(用物理地址)rknn_tensor_mem* input_mem = rknn_create_mem_from_phys(ctx, phys_addr, virt_addr, size);// 2. 设置零拷贝输入rknn_set_io_mem(ctx, input_mem, &input_attr);// 3. 推理rknn_run(ctx, NULL);
效果:数据拷贝耗时减少 80%,端到端延迟降低 30%。
2. 内存优化
(1)RK3588 SRAM 使用(减轻 DDR 压力)
RK3588 有 956KB SRAM,可分配给 NPU 存中间 Tensor:
// 初始化时开启SRAMret = rknn_init(&ctx, model, size, RKNN_FLAG_ENABLE_SRAM, NULL);
查询 SRAM 使用:cat /sys/kernel/debug/rknn/mm,可看到已用 / 剩余大小。
(2)动态 Shape(单模型支持多分辨率)
无需生成多个模型,一个模型支持多种输入尺寸(如 224x224、192x192):
# 配置动态输入dynamic_input = [[[1,3,224,224]],[[1,3,192,192]]]rknn.config(dynamic_input=dynamic_input)
场景:NLP 模型(可变序列长度)、图像分割(可变分辨率)。
3. 模型优化
(1)混合量化(精度与性能平衡)
对精度敏感的层(如输出层)用 FP16,其他层用 INT8:
# 混合量化配置文件custom_quantize_layers:Conv__350 float16 # 指定层用FP16quantize_parameters:FeatureExtractor/Convqtype: asymmetric_quantizeddtype: int8
(2)模型剪枝(无损减小体积)
开启model_pruning,自动移除冗余权重:
rknn.config(model_pruning=True)
效果:MobileNetV2 权重减少 6.9%,运算量减少 13.4%,精度无损失。
四、避坑指南:开发者常踩的 5 个坑
1.连板调试失败
◦原因:RKNN Server 未启动或版本不匹配;
◦解决:执行restart_rknn.sh,确保 Server 版本与 Toolkit2 一致。
1.量化后精度下降严重
◦原因:校正集不具代表性,或量化算法选择不当;
◦解决:更换 KL-Divergence/MMSE 算法,增加校正集数量(50-100 张)。
1.模型转换报错“动态 Shape 不支持”
◦原因:Toolkit2 < 1.5.2 不支持动态 Shape;
◦解决:升级 Toolkit2 到 1.5.2+,用dynamic_input配置。
1.板端推理耗时比连板评估长
◦原因:连板评估有数据传输开销,板端推理更真实;
◦解决:以板端 C API 的eval_perf结果为准。
1.NPU Hang 住(推理耗时超 20s)
◦原因:驱动 bug 或模型超出 FP16 范围;
◦解决:升级 NPU 驱动到最新版,训练时添加 BN 层限制数值范围。
五、开发资源汇总
最后给大家整理了必备资源,收藏好少走弯路:
•RKNN Toolkit2:https://github.com/airockchip/rknn-toolkit2(含 API 文档、示例);
•RKNN Model Zoo:https://github.com/airockchip/rknn_model_zoo(MobileNet、YOLOv5 等预转换模型);
•RGA 库:https://github.com/airockchip/librga(图像缩放、旋转加速,配合 NPU 使用);
•官方文档:本文基于《RKNN SDK V2.0.0beta0 用户指南》,完整文档可在瑞芯微官网下载。
总结
瑞芯微 RKNPU 开发的核心是 “工具链熟练 + 优化技巧到位”:先用 Toolkit2 做好模型转换与评估,再根据场景选择通用 / 零拷贝 API,最后通过多核、SRAM、动态 Shape 等技巧压榨性能。边缘 AI 部署不复杂,跟着这篇指南走,你也能快速搞定 RKNPU!
如果有疑问,欢迎在评论区交流,也可以关注瑞芯微官方 GitHub 获取最新动态~
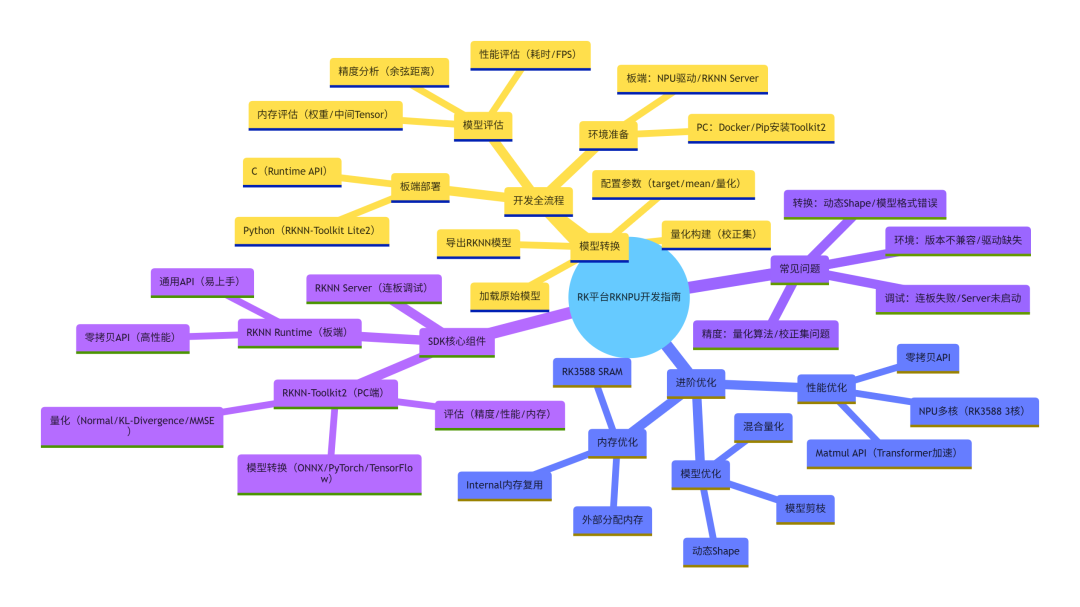
(附:全文核心脑图)
-
【飞凌嵌入式OK3576-C开发板体验】RKNPU图像识别测试2024-10-10 11984
-
国产开发板的端侧AI测评-基于米尔瑞芯微RK35762025-02-14 2045
-
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测2025-08-29 2586
-
如何精准驱动菜品识别模型--基于米尔瑞芯微RK3576边缘计算盒2025-10-31 1782
-
【瑞芯微RK1808计算棒试用体验】(1)------开发环境搭建和mobilenet_v1示例体验2019-10-25 4345
-
瑞芯微Toybrick AI开发平台2020-07-24 3844
-
【中奖公示】8.8瑞芯微RKNN系列直播一:RKNN Runtime部署指南2022-08-05 4428
-
【中奖公示】8.11瑞芯微RKNN系列直播二:RKNN模型精度优化指南2022-08-11 3364
-
瑞芯微和英伟达的边缘计算盒子方案,你会选哪一家的?2022-09-29 2913
-
嵌入式边缘AI应用开发指南2022-11-03 1484
-
迅为视频教程 | RKNPU2 从入门到实践一套搞定!2023-06-20 2230
-
迅为RK3568/RK3588开发板视频教程 | RKNPU2 从入门到实践一套搞定!2023-06-30 3000
全部0条评论

快来发表一下你的评论吧 !
