

基于LF2407的模糊数字PI控制器的设计
描述
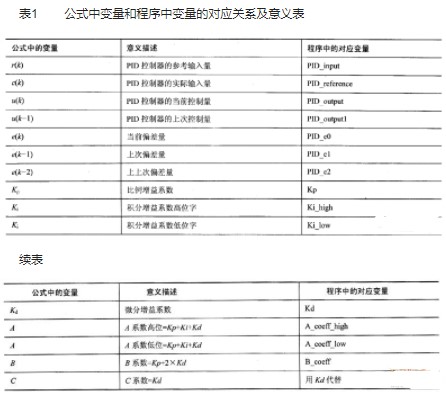
在数字PID控制器和模糊PI控制器的程序设计中需要用到大量的变量,为了便于以后的讲解,首先定义一些程序中所要使用的变量名和公式中使用的变量名,如表1所示。
本案例首先设计一个数字PID控制器,现在假设它是一个对电动机速度进行PID控制的系统。图1是PID控制器的原理框图。
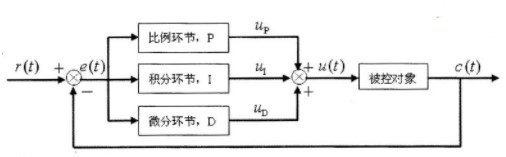
图1 PID控制器的原理框图
图1中,r(t)是电机速度设定值,c(t)是电机转速的实际测量值,e(t)是输入控制器的偏差信号,勿⑺是控制器输出的控制量,则PID控制算式如式4-1所示。
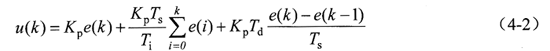
在式4-1中,Kp是比例系数,起比例调整作用。Ti是积分时间常数,它决定了积分作用的强弱。Td是微分时间常数,它决定了微分作用的强弱。在PID控制的3种作用中,比例作用可对系统的偏差做出及时响应;积分作用主要用来消除系统静差,改善系统的静态特性,体现了系统的静态性能指标;微分作用主要用来减少动态超调,克服系统振荡,加快系统的动态响应,改善系统的动态特性。,PID控制的3种作用(比例、积分、微分)是各自独立的,可以分别使用,也可以结合徒用,但是积分控制和微分控制不能单独使用,必须和比例控制结合起来,形成Pl控制器或者PD控制器。式4-1是模拟形式的PID控制算式,现在采用LF2407实现数字PID控制,则对式4-1离散化,得到PID控制的离散形式,如式4-2所示。
其中Ts为采样周期。这是位置式PID控制算式,为了增加控制系统的可靠性,采用增量式PID控制算式,即让LF2407只输出控制量u(k)的增量ΔU(k)。式4-2是第k次PID控制器的输出量,那么第k-1次PID控制器的输出量如式4-3所示。

方程式4-5就是本控制程序中用到的增量式PID控制算式。增量式PID控制与位置式ΠD控制相比仅是算法上有所改变,但是它只输出增量,减少了DSP误操作时对控制系统的影响,而且不会产生积分失控。本案例基于LF2407的PID控制器的实现框图如图2所示。
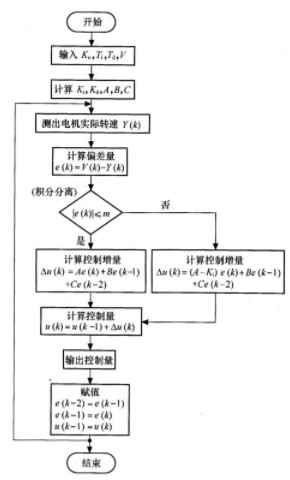
图2 基于LF24O7的PID控制器的实现框图
从图2可以看出被控电机的速度设定量由DSP给出,经过DSP计算出控制量u(k),对它进行DA转换,产生模拟控制量u(t),从而实现对被控电机速度的控制,而电机实际转速c(t)通过AD转换器送入DSP,使整个系统构成一个闭环系统。如图3所示是本案例设计的数字PID控制器在DSP上实现的控制程序流程图。
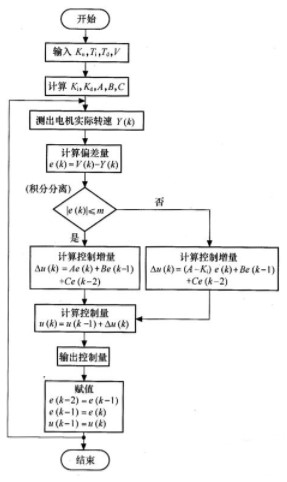
图3 基于LF24O7的数字PID控制器的程序流程图
其次,本案例还要设计一个模糊PI控制器,它的硬件电路如图2所示,和数字PID控制器的硬件电路是一样的。模糊控制技术是建立在模糊数学的基础上的,它是针对被控对象的数学模型不明确,或非线性模型的一种工程实用、实现简单的控制方法。与传统的PID控制器相比,模糊控制器有更快的响应和更小的超调,对过程参数的变化不敏感,即具有很强的鲁棒性,能够克服非线性因素的影响。
数字PID控制器是一种工业控制中通用的控制器,但是工业生产现场环境复杂,往往出现在某种情况下设计好的控制参数,在另一种情况下又不满足工业生产的需求了,而常规的数字PID控制器不具有在线整定参数Kp、Ki、Kd的功能,使得其不能满足系统在不同偏差绝对值H及偏差变化率绝对值|△e|下,对PID参数的不同要求,从而影响了控制器控制品质的进一步提高。在本案例中,在数字PID控制器的基础上,去掉数字PID控制器中的微分环节D,只采用PI控制器,并且采用模糊推理思想,根据不同的|e|和|△e|,对PI控制器的参数Kp和Ki进行在线自整定。其原理结构由两部分组成:常规PI控制器部分和模糊控制的参数校正部分,如图4所示。
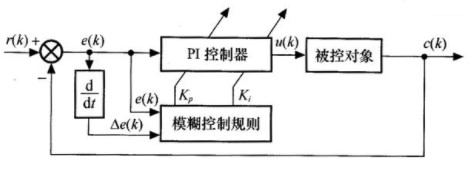
图4 模糊PI控制器的原理框图
从图4中可以看出,r(k)是输入设定值,c(k)是实际测量值,r(k)是输人偏差信号,其H控制器的离散表示形式如式4-6所示。
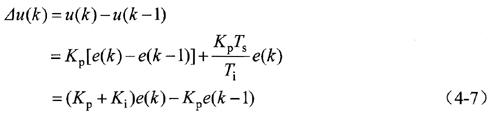
在式4-6中,Ts为采样周期。这是位置式PI控制算式,为了增加可靠性,采用增量式PI控制算式,如式4-7所示。增量式PI控制与位置式PI控制相比,仅仅是算法上有所改变,但是它只输出增量,减少了DSP误操作时对系统的影响。
在式4-7中,令A系数=Kp+Ki, B系数=Kp,则最终增量式PI控制器的控制算式如方程式4-8所示。程序中只需计算出A系数和B系数就可以计算出当前的控制增量△u(k)。

如图4所示,采用模糊控制规则,根据不同的|e|和|△e|,对Pi控制器的参数Kp和Ki进行在线自整定。本模糊控制器的输入语言变量是偏差绝对值IF、偏差变化率绝对值|△E|,输出语言变量是Pi控制器的比例增益系数Kp和积分增益系数Ki。
在模糊控制中,语言变量是用语言值(模糊量)来表示一个物理量的,而不是用符号或确定的数字来表示的。当用语言值表示一个语言变量时,应注意用多少个语言值去描述语言变量,这是语言变量的分档问题。本实例中,各语言变量用语言值描述如下:
系统偏差的绝对值|e(k)={零、小、中、大}
偏差变化率的绝对值|△e(k)|={零、小、中、大}
只控制器的比例系数Kp={零、小、中、大}
只控制器的积分系数Ki={零、小、中、大}
各语言变量用相同的语言值来描述,简化了模糊控制规则的设计。在设计模糊控制规则时,采用不同的模糊推理,语言变量的分档是有区别的。本设计采用CRI(Compositional Ruleof Inference)推理法,为了在实时控制中避免进行关系矩阵的合成运算,先在脱机状态下把所有可能的输入和输出情况计算出来,形成一张控制表去执行控制。控制表是以整数形式表示的,为了能产生控制表,在CRI推理法中把语言变量的论域转换成有限整数的论域,本质上是把连续论域离散化后产生离散论域。采用式4-9把它离散化到整数论域N。
其中a为连续论域X=[XL,XH中的某个数,b是与a对应的整数论域N中的某个数,q为模糊控制中对精确量进行模糊化时所用的量化因子。本设计中,各语言变量的档数均为4档(零、小、中、大),因此取整数论域N为{0,1,2,3,4,5,6}。此时,如图5和图6所示,可以取语言变量值4档如下:
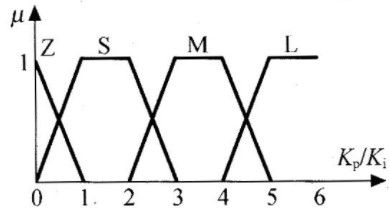
图5 语言变量|E|和|△E|
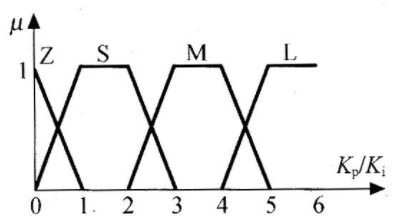
图6 语言变量Kp、Ki
大(L)取在5、6附近;
中(M)取在3、4附近;
小(S)取在1、2附近;
零(Z)取在0附近。
由模糊推理得到的控制表中的控制量也是一个模糊量,反模糊化是模糊化的逆向运算,当整数论域为N=[-n,+n],连续论域X=[XL,XH],可采用式4-10进行反模糊化处理。
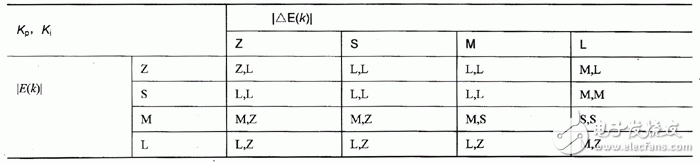
其中b为整数论域为N=[-n,+n]中的某个数,a是与b对应的连续论域X=[XL,XH]中的某个数,k为模糊控制中对模糊量进行反模糊化时所用的比例因子。
当|e(k)|较大时,为了加快系统的响应速度,并为避免因开始时偏差的瞬间变大可能引起微分过饱和而使控制作用超出许可范围,应取较大的Kp,同时为了防止积分饱和,避免系统响应出现较大的超调,此时应该去掉积分作用,取Ki=0。
当|e(k)|和|△e(k)|为中等大小时,为使系统响应的超调减小又不影响系统的响应速度,kp和Ki都不能取大,而应取较小的Ki,Kp的取值要大小适中。
当|e(k)|较小时,为使系统具有良好的稳态性能,应该增大Kp和Ki的值,同时为了避免系统在设定值附近出现振荡,并考虑到系统的抗干扰性能,应适当地选取Kp。
根据以上这些原则,并参考工作中总结的实际经验,得到了如表2所示的模糊PI控制器参数乌和凡的调节规则,但是这些规则都是用模糊量来表示咐。
表2 参数自整定模糊PI控制规则表
在本设计中,利用CRI法推理时控制过程是用查控制表来产生控制量的。在控制表中,模糊偏差量|e|、模糊偏差变化率|△E|、Pi控制器的模糊比例系数Kp、模糊积分系数Ki都是用其对应整数论域的元素来表示的。对于单个实时精确量,把它和量化因子相乘,得到的结果再四舍五入,就求出了对应整数论域的相应元素,即可用于查询控制表,从而实现r输人量的模糊化。根据以上分析,如图7所示是本案例设计的模糊PI控制器在DSP上实现的控制程序流程图。
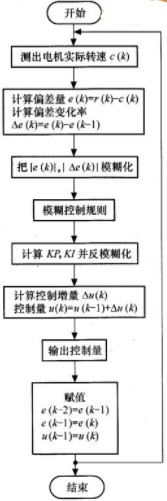
图7 基于LF2407的模糊PI控制器的程序流程图
实用的DSP程序包括主程序和系统初始化程序以及存储器配置文件、中断向量表程序,如果系统没有正确初始化或者存储器配置不正确,或者没有中断向量表,则系统将不能正确运行,得到的结果和预想的将大相径庭。本节将先介绍DSP的系统初始化、存储器配置和中断向量表,然后再介绍包含实际算法的DSP应用程序。
-
SM320LF2407A-EP DSP控制器:高性能与多功能的完美结合2026-03-09 996
-
控制器TMS320LF2407A系列数据手册2021-07-20 1380
-
TMS320LF2407A为数字控制系统的设计提供了参考2021-04-14 1592
-
请问LF2407如何通过串口在线升级2018-08-19 1539
-
DSP+TMS320LF2407与CAN控制器的接口应用2016-05-06 693
-
关于LF2407实现SVPWM的研究2016-04-15 605
-
基于TMS320LF2407的模糊控制直流调速系统2009-08-15 633
-
内嵌CAN控制器的TMS320LF2407 的CAN通信实例2009-04-16 807
-
TMS320LF2407 CAN控制器实验2008-10-17 1400
-
lf2407最小原理图2008-06-16 973
全部0条评论

快来发表一下你的评论吧 !
