

后摩智能六篇论文入选四大国际顶会
描述
2025年以来,后摩智能在多项前沿研究领域取得突破性进展,近期在NeurIPS、ICCV、AAAI、ACMMM四大国际顶会上有 6 篇论文入选。致力于大模型的推理优化、微调、部署等关键技术难题,为大模型的性能优化与跨场景应用提供了系统化解决方案。
这四大会议涵盖人工智能从基础理论、核心技术与跨模态应用的全景视图,是全球学术界与产业界进行深度交流与合作的关键平台:
NeurIPS作为人工智能与机器学习领域的顶尖国际会议,尤为强调神经信息处理系统的基础理论、算法创新与前沿应用;
ICCV作为计算机视觉领域三大顶级会议之一,专注于图像、视频的视觉理解与三维视觉等核心技术;
AAAI作为人工智能领域的综合性顶会,覆盖机器学习、自然语言处理、计算机视觉乃至AI伦理等多个核心方向,致力于推动人工智能的整体发展;
ACMMM则作为多媒体技术领域的权威国际会议,聚焦于跨模态分析、内容生成与人机交互等融合技术。
本文将简要概述近期被收录的论文。
01【NuerIPS-2025】RSAVQ: 为LLM而生的黎曼敏感性感知矢量量化

后摩智能芯片算法团队提出了黎曼敏感度感知矢量量化框架 RSAVQ(Riemannian Sensitivity-Aware Vector Quantization),攻克了大语言模型(LLMs)在极低比特(如 2-bit)量化下的精度保持难题。该框架通过信息几何与矢量量化的深度融合,首次在参数空间的黎曼流形视角下约束量化误差,并结合通道敏感性动态分配比特资源,为大模型在移动终端、嵌入式设备等资源受限场景的高效部署提供了突破性解决方案。
研究背景
近年来,大语言模型在自然语言处理等任务中能力卓越,但参数规模指数级增长(如 LLaMA-3 70B 在 FP16 需约 140GB 内存)制约其在边端设备落地。模型压缩尤其是权重量化被视为关键。低比特量化可降开销,但 2-bit 及以下极低比特场景中,传统方法有双重瓶颈:忽视方向敏感性,现有量化假设误差各向同性,实际不同方向误差对模型损失影响差异大;忽视通道敏感性,均匀和传统矢量量化默认通道敏感性一致,实则不同通道相同扰动损失变化相差数倍。RSAVQ 以信息几何为核心创新,将神经网络参数空间建模为带 Fisher 信息度量的黎曼流形,通过两大核心模块实现极低比特下的精度保持与高效部署。
方法简介
核心模块一:EDSG(误差方向敏感性引导)针对传统量化误差易积累于高敏感方向的问题,RSAVQ 提出测地误差对齐策略。利用 Fisher 信息矩阵量化参数空间曲率,将量化误差投影至负自然梯度方向,通过约束项强制误差沿低敏感方向分布,减少对模型性能的影响。
核心模块二:WCSG(通道敏感性引导)基于 Fisher 信息矩阵分析构建通道敏感度量,量化各通道对损失的贡献。结合率失真理论与拉格朗日优化,在总比特预算下实现动态比特分配,高敏感通道获更多比特,低敏感通道精简资源。
研究结果和价值
实验表明,RSAVQ在LLaMA-2、LLaMA-3系列大模型上优势显著:LLaMA-2 70B在2-bit量化下,困惑度仅比FP16高0.4,零样本精度达58.66%,超越VPTQ、QuIP等当前最优方法;LLaMA-3 8B的2-bit量化PPL较VPTQ低0.4,零样本精度提升1.5%;LLaMA-3 70B的2-bit量化零样本精度达71.3%,创大语言模型极低比特量化的新纪录,2-bit量化精度逼近浮点,全面超越SOTA。
论文链接:https://arxiv.org/abs/2510.01240
02【ACMMM-2025】MQuant: 面向多模态大语言模型的静态全量化统一框架

后摩智能芯片算法团队提出了MQuant (Unleashing the Inference Potential of Multimodal Large Language Models via Full Static Quantization) —— 首个面向多模态大语言模型(MLLMs)的全静态量化框架,在多模态推理加速领域取得了重要突破。该工作系统性地分析了 MLLMs 在视觉与语言模态融合过程中存在的量化瓶颈:视觉 token 数量庞大、分布尺度差异显著、Hadamard 旋转引发的极端异常值等问题。针对这些难题,MQuant 提出了模态特异静态量化(Modality-Specific Static Quantization, MSQ)与旋转幅值抑制(Rotation Magnitude Suppression, RMS)等关键技术,从体系层面实现了多模态融合的量化统一。
研究背景
在当前人工智能浪潮中,多模态大语言模型(MLLMs)凭借理解图像、文本、视觉+语言等多种输入形式的能力,正在迅速成为先进智能系统的重要组成部分。然而,这类模型规模庞大、推理资源开销极高,严重限制了其在边缘设备、移动端、嵌入式场景中的落地部署。
方法简介
MQuant 针对上述挑战,提出了三大关键模块:
Modality-Specific Static Quantization (MSQ):为视觉 token 与文本 token 分别设定静态量化尺度,避免“一个尺度套用所有模态”带来的偏倚。
Attention-Invariant Flexible Switching (AIFS):通过重排序 token,保持注意力机制对因果依赖的完整支持,同时避开每个 token 需要动态 scale 计算的高昂代价。
Rotation Magnitude Suppression (RMS):专门用于缓解因在线 Hadamard 旋转所引入的权重 “极端异常值” 问题,从而在低比特量化下保留更高的模型稳定性。
研究结果和价值
在五款主流多模态大语言模型(包括 Qwen‑VL、MiniCPM‑V、CogVLM2 等)上,MQuant 在 W4A8(4 位权重量化 / 8 位激活量化)设置下实现了如下表现:接近浮点(FP)精度:精度下降 < 1%;推理延迟最多降低约 30%‘’显著超越现有 PTQ 基线方法。MQuant 的提出,为“多模态大语言模型 + 资源受限设备” 的组合场景带来了关键突破:既能保精度、又能降延时。未来,我们预计该技术将加速 MLLMs 在移动终端、智能穿戴设备、边缘侧 AI 应用中的大规模部署。进一步方向包括:更低比特率下的量化(如 2 位以下)、适配更多模态(视频、音频、多语言)以及自动化量化调优流程。
论文链接:https://arxiv.org/abs/2502.00425
03【AAAI-2026】OTARo: 一次微调多种bit,打造端侧大模型高效部署方案

后摩智能芯片算法团队提出了OTARo(Once Tuning for All Precisions toward Robust On-Device LLMs)。一种仅需一次微调即可支持多种精度切换的鲁棒微调方法,大幅降低了微调与端侧部署所需的计算资源,助力端侧用户稳健适应动态发展中的真实世界场景。
研究背景
近年来,边缘设备在算力、带宽和存储等方面取得了显著突破,使得LLMs的端侧部署(LLMs On-Device Deployment)成为了当前研究的前沿方向。当资源受限的端侧设备部署特定精度的大语言模型时,针对单一精度的微调技术虽然可以提升模型在特定精度上的效果,但是应注意到,这种方式在其他精度下的性能被削弱,即使在相邻精度之间也可能出现性能骤降的现象。多个精度分别进行固定精度微调,得到多个模型部署到端侧供用户适时选择是解决问题的一种思路,然而,为每种精度分别训练模型会显著增加微调期间计算成本,并且,对于资源有限的边缘设备而言,存储多份权重会显著增加存储空间占用,易超出硬件容量限制,也意味着在模型版本更新时需要分别维护和同步多份权重,增加了管理复杂度。
方法简介
OTARo基于SEFP(Shared Exponent Floating Point),联合多位宽进行感知微调,一次微调生成一个可切换为多种精度且保持性能鲁棒性的模型,助力端侧用户稳健适应动态发展中的真实世界场景。在训练位宽采样上,提出利用-探索位宽路径搜索策略(BPS),保证了位宽路径能够探索到不同位宽的量化的误差,且最终收敛于量化误差较小的高位宽。进一步,为了缓解低位宽区间上误差的影响,在梯度更新上,提出延迟更新策略(LAA),利用梯度振荡的周期性、对称性,通过模型参数的延迟更新,平滑了低位宽下的梯度剧烈振荡,减少了对模型向其他位宽最优解靠拢的消极影响,进而实现微调后模型的鲁棒性。
研究结果和价值
实验在表明,OTARo在所有位宽下始终取得优秀性能。在具有挑战性的低比特设置(E5M4、E5M3)下,OTARo也能获得较好的表现。OTARo的核心突破在于通过一次微调获得一个统一模型,以支持多种精度。该方法大幅度降低多位宽模型微调以及存储复杂度,为大模型移动端部署提供核心技术支撑,推动大模型技术朝着更灵活、更经济的方向高效落地。
论文链接:https://arxiv.org/abs/2511.13147
04【AAAI-2026】FQ-PETR:全量化位置嵌入变换框架,突破自动驾驶实时感知瓶颈
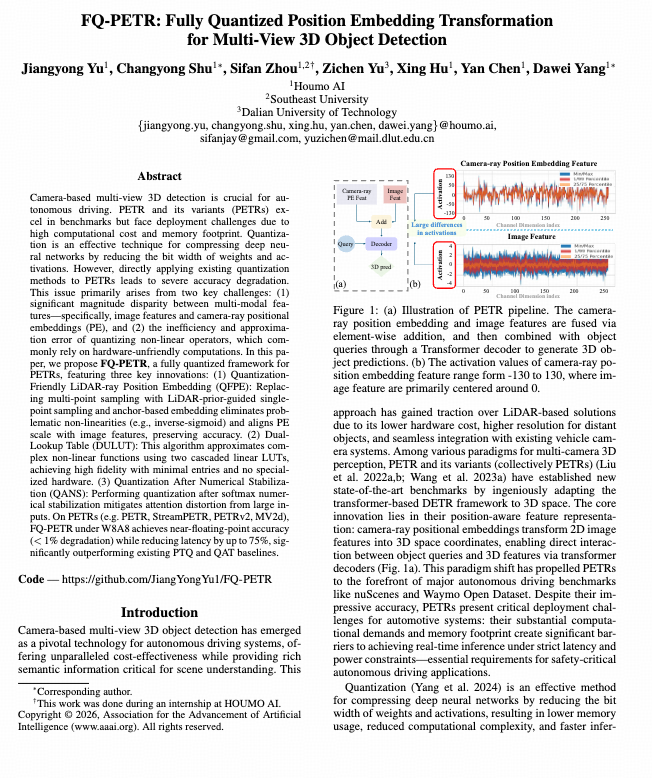
后摩智能芯片算法团队提出了FQ-PETR(Fully Quantized Position Embedding Transformation)—— 面向多视角 3D 检测模型的全量化框架,在自动驾驶感知模型的高效推理与端侧部署方向上取得重要突破。该研究针对 PETR 系列模型在量化部署中精度急剧下降的问题,系统揭示了导致性能崩塌的根源:多模态特征幅值差异过大与非线性算子量化误差累积。为此,团队创新性地提出三项关键技术,实现了3D 检测模型的端侧全整型推理。
研究背景
在自动驾驶感知系统中,基于相机的多视角 3D 检测因其高分辨率与低成本,正逐步取代纯 LiDAR 方案。PETR 及其系列模型凭借将 2D 图像特征映射至 3D 空间的“位置嵌入变换(Position Embedding Transformation)”设计,成为多摄像头感知领域的主流框架。然而,这类 Transformer 结构的计算与显存开销极大,阻碍了其在端侧设备中的实时部署。 现有量化技术虽能显著压缩模型,但直接应用于 PETR 会导致性能崩塌(mAP 下降 20% 以上)。根源在于: 1. 多模态特征量级差异极大——图像特征与相机射线位置嵌入(PE)数值范围相差百倍;2. 非线性算子(如 Softmax、Sigmoid)量化后误差剧增且硬件不友好。
方法简介
FQ-PETR 面向上述瓶颈,提出了三项关键技术:
Quantization-Friendly LiDAR-ray Position Embedding (QFPE):以 LiDAR 物理先验为指导,将原多点采样改为单点射线采样,替代 inverse-sigmoid 非线性,显著减小 PE 幅值(约 4.4 × 降低)并保持几何一致性。
Dual-Lookup Table (DULUT): 创新性地用“两级线性 LUT 级联”近似复杂非线性函数(如 SiLU、Softmax),以 32 + 32 表项实现 < 0.1% 误差,无需专用硬件,兼容各类 NPU / GPU 平台。
Quantization After Numerical Stabilization (QANS): 在 Softmax 数值稳定化(减去最大 logit)后再执行整数量化,有效抑制注意力漂移问题,确保注意力分布与浮点结果一致。
研究结果和价值
实验表明,在 PETR、PETRv2、StreamPETR、MV2D 等主流系列上,FQ-PETR 在 W8A8 全整型量化下实现 < 1% mAP/NDS 下降;延迟最高降低 75%,显存占用减少 75%,整体 FPS 提升 3.9×。FQ-PETR是首个针对 Transformer范式3D检测器的端侧全量化解决方案,为高性能感知模型的车载与移动部署奠定技术基础。
论文链接:https://arxiv.org/pdf/2502.15488
05【AAAI-2026】VAEVQ:基于变分建模的视觉离散表征新范式

后摩智能芯片算法团队提出了 VAEVQ(Variational Autoencoding Vector Quantization):一种以变分建模驱动的离散视觉表征方法,在视觉离散化(Visual Tokenization)领域实现了新的突破。该工作创新性地将变分自编码思想(VAE)与矢量量化(VQ)深度融合,从概率建模角度重塑了视觉离散化过程,显著提升了视觉 token 的表达能力与语义一致性。
研究背景
近年来,VQ-VAE、VQ-GAN 等离散视觉模型在多模态大模型中承担关键角色,负责将连续视觉特征映射为离散 token,以支持图像生成、理解与视觉语言对齐。然而,现有方法普遍面临两大瓶颈:过度离散化损失语义连续性和码本利用率低、训练不稳定。VAEVQ 框架从概率视角出发,引入变分推断机制,以连续的潜在分布指导离散向量量化,形成统一的“变分–离散”表征学习框架。
方法简介
核心模块一:Variational Latent Regularization(变分潜空间约束) 通过引入高斯分布的潜变量先验,VAEVQ 在编码端学习潜空间分布 q(z|x),并通过 KL 散度约束潜变量与标准先验对齐,从而在量化前保持特征的可分性与连续性,为离散化提供概率平滑。
核心模块二:Probabilistic Vector Quantization(概率化矢量量化) 以潜变量的概率分布为权重计算期望量化误差,实现“软量化”与梯度可传递。该设计有效缓解了 codebook collapse,并显著提升码本利用率。
核心模块三:Joint Variational Optimization(联合变分优化) 通过联合优化编码器、解码器与码本参数,VAEVQ 实现了端到端的稳定收敛。模型在重建质量与离散语义之间取得平衡,具备更强的生成能力与跨模态对齐能力。
研究结果和价值
在 ImageNet、MS-COCO、CC3M 等标准数据集上,VAEVQ 相比 VQ-VAE2 与 VQ-GAN 在重建 PSNR 与 FID 指标上分别提升 1.3dB 与 7.2%,视觉 token 语义聚合度(Semantic Clustering Score)提升 18%。充分表明该框架在高保真重建、离散语义建模与跨模态表征对齐方面的综合优势,为构建更高效、更可扩展的视觉离散表示与大规模生成模型奠定了坚实的方法论基础。
论文链接:https://arxiv.org/abs/2511.06863。
06【ICCV-2025】EA-Vit:基于弹性架构的ViT多任务高效部署框架

后摩智能芯片算法团队与新加坡国立大学、西安电子科技大学合作研究提出了EA-Vit(Efficient Adaptation for Elastic Vision Transformer)。该框架攻克了 Vision Transformers(ViTs)在跨平台部署中的核心痛点 —— 无需重复训练即可生成适配不同资源约束的多尺寸模型,为 AI 视觉应用的高效落地提供了全新解决方案。代码已同步开源于 GitHub(https://github.com/zcxcf/EA-ViT)。
研究背景
在计算机视觉领域,ViTs 因出色的泛化能力和下游任务适配性,已成为图像分类、语义分割、医疗影像分析等场景的核心模型。然而,传统部署模式面临显著瓶颈:从资源受限的移动端到高性能 GPU 集群,不同平台需对应不同尺寸的 ViTs 模型,需重复训练、微调,不仅耗时耗能,还增加了模型版本管理复杂度;现有弹性 ViT 方法(如 DynaBERT、HydraViT)或仅支持 1-3 个维度调整,或需在预训练阶段引入弹性,子模型数量有限(最多仅个),难以满足多样化部署需求。
方法简介
第一阶段:构建Multi-Dimensional Elastic Architecture,首次实现 ViT 在 MLP expansion ratio、number of attention heads、embedding dimension、network depth 四个核心维度的全弹性调整,同时采用Curriculum-based Elastic Adaptation策略:从最大预训练模型起步,按预设步骤(如训练 epoch 10、15、20)逐步扩大子模型参数采样范围(最终实现 R∈[0.5,4]、H∈[6,12]、E∈[384,768]),在保留预训练知识的同时,避免小模型训练对大模型性能的干扰。
第二阶段:设计lightweight constraint-aware router,基于定制化 NSGA-II 算法筛选的 Pareto-optimal 配置初始化,再与 ViT 骨干网络联合优化,可根据目标平台的计算预算(如 MACs、参数量、latency)动态输出最优子模型配置。
研究结果和价值
EA-Vit 的核心突破在于将 ViT 的弹性适配从预训练阶段转移至下游任务适配阶段,真正实现“一次适配,多端可用”。该框架不仅大幅降低模型训练与存储成本,还能通过 router 动态匹配不同任务与平台需求,为工业质检、移动端 AI、医疗设备集成等场景提供关键技术支撑,有望推动 AI 视觉技术向更灵活、更经济的方向加速落地。
论文链接:https://arxiv.org/pdf/2507.19360
总结
上述研究成果聚焦大模型与视觉任务中的量化、表征、适配与部署等核心挑战,从算法框架创新到软硬件协同优化,系统性地展现了后摩智能在人工智能领域的前瞻布局与深度突破。相关成果从模型压缩、极低比特量化、推理效率、多平台适配性等关键维度,为大语言模型端侧推理、自动驾驶感知以及多模态大模型的高效部署,提供了具备实践价值的全栈解决方案。
-
摩拜一下他的开挂人生,6篇论文入选NIPS 20182018-09-26 5060
-
阿里平头哥半导体获国际权威会议认可 3篇论文入选ISCA 2020大会2020-03-26 4564
-
阿里全新AI推理方法入选ICML 2020,可减少AI对计算和内存资源的消耗2020-06-19 1846
-
云知声2篇论文参展国际语音顶会INTERSPEECH 20222022-09-21 2297
-
后摩智能连续入选年度智能驾驶行业榜单2023-06-14 1414
-
地平线科研论文入选国际计算机视觉顶会ECCV 20242024-07-27 2307
-
后摩智能5篇论文入选国际顶会2025-02-19 1938
-
云知声四篇论文入选自然语言处理顶会ACL 20252025-05-26 1607
-
后摩智能四篇论文入选三大国际顶会2025-05-29 1621
-
理想汽车八篇论文入选ICCV 20252025-07-03 1432
-
格灵深瞳六篇论文入选ICCV 20252025-07-07 1853
-
理想汽车12篇论文入选全球五大AI顶会2025-11-21 1179
-
后摩智能4篇论文入选人工智能顶会ICLR 20262026-02-09 1163
-
地平线11篇论文强势入选CVPR 20262026-03-18 1088
-
后摩智能三篇论文入选ACL和ICML两大人工智能顶会2026-05-12 848
全部0条评论

快来发表一下你的评论吧 !
