

基于多级矢量量化实现优化LSF参数码本的设计
描述
矢量量化(Vector Quantization)是一种极其重要的信号压缩方法,广泛应用于语音、图像信号压缩等领域。信息论的一个分支——“率-畸变理论”指出,无论对于何种信息源,即使是无记忆的信息源(即各个采样信号之间互相统计独立),矢量量化总是优于标量量化,且矢量维数越大优度越高。因此,目前国内外对于矢量量化技术的研究非常广泛而深入。平衡考虑量化效果和运算复杂度,多级矢量量化(MSVQ)提供了一个很好的折衷办法。
线性预测编码(LPC)参数能很好地表征语音信号的短时谱包络信息,在各种LPC参数中,线谱频率(LSF)较其它参数能更有效地表达LPC信息。K.K.Paliwal和B.S.Atal仔细研究了用24~26个比特量化一个10阶LSF参数的方法,提出了分裂矢量量化(Split Vector Quantization)和多级矢量量化MSVQ(Multistage Vector Quantization)两种方案,并且试验得到了用25比特的2级MSVQ能取得较好的量化效果(平均失真1dB,2~4dB概率小于2%,大于4dB为0)。
MSVQ算法有效减小了码本容量,但如果在量化比特有限的情况下,想取得透明的量化效果,必须解决两个问题:(1)怎样搜索码本得到最佳匹配索引;(2)怎样设计码本。在算法设计中这两个问题必须统一考虑。对前一个问题,为了方便一般采用序列搜索算法,依次搜索得到各级的最佳匹配矢量。在码本设计中,更多的也是分级依次进行码本训练,割裂了各级码本之间的相关性。本文将着重研究多级矢量量化的联合优化码本设计问题。
1、 问题分析
传统的MSVQ算法在LSF参数码本设计时采用一种连续(stage-by-stage)的设计方法,第k级码本只与前面的第1至第(k-1)级码本有关,而不考虑后续各级码本,即将后续各级码本内容视为0。在量化时,同样只在本级寻找1个最佳匹配矢量,然后得到余量矢量送入下一级量化。量化过程可以用式(1)表示,假设有2级码本,需要找出各级码本索引:

在序列搜索算法中,搜索yi时,假设zj为0,搜索zj时yi已经固定。这样的搜索算法显然是一种次优的搜索算法,解决这个问题的方法是全搜索。全搜索是最优的搜索算法,但是其计算复杂度却是难以承受的。例如,一个25比特2级码本(13-12结构),其全搜索复杂度是上述连续搜索的2000倍以上。M进制搜索折衷解决了这个问题。在运算量大大减小的情况下,取得了逼近全搜索的量化效果。
在码本设计中,无论是经典的GLA算法还是改进的模拟退火(SA)算法,码本设计都是逐级连续进行的。利用各级码本之间的相关性优化码本设计,可以较明显地改善MSVQ的量化效果。在应用联合码本设计方法量化音频DCT系数时,已经取得了大约0.4 dB的SNR改善。本文在量化LSF参数时,对比300步的SR算法,得到了大约0.05dB、约1bit的加权对数谱失真(WLSD)的改进效果。
2、 算法说明
2.1 失真距离量度
对一个MSVQ码本,为方便考虑假设共有2级码本。LSF参数为10维矢量。对LSF参数而言,其敏感矩阵(sensitivity matrix)是对角阵,因此可以用加权最小均方误差(WMSE)代替加权对数谱失真(WLSD)作为失真量度。量化失真

r的经验值一般为0.15。
2.2 理论推导
对一个训练矢量集X和两级码本Y、Z,可以对X中每个矢量进行2级全搜索,得到最佳索引值对(i,j)。根据i和j的不同可以对X中每个矢量进行聚类。假设S为对第一级码字形成的聚类,Si为所有X中第一级量化索引为i的训练矢量集合。同样假设R为第二级码字聚类,可知,{S1,S2,…,SK1}和{R1,R2,…,RK2}均是同一X集合的不同划分。对于X∈Si,平均量化失真为:

2.3 算法描述
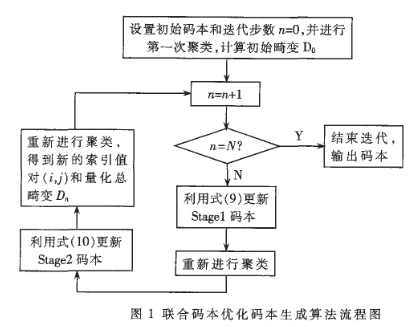
(1)设置初始码本,读入训练矢量文件,并对其进行两级码本全搜索,得到针对两级码本的聚类{S1,S2,…,SK1}和{R1,R2,…,RK2}。假设训练矢量个数为num,对所有训练矢量计算此时的量化失真之和,失真测度采用WLSD距离。设置迭代最大步数N,设置初始步数n=0;
(2)n=n+1,利用式(9)更新第一级码本;
(3)重新对训练矢量集进行全搜索,得到新的索引值对(i, j),然后利用式(10)更新第二级码本;
(4)再次对训练矢量集进行量化搜索,得到新的索引值对(i, j),并重新计算量化总畸变Dn;
(5)判断n=N?若n<N,跳转至(2)继续进行迭代;若n=N,结束迭代,保存更新后的码字至码本文件。
2.4 算法的进一步优化
上述联合优化MSVQ算法中,很重要的一步就是对训练矢量进行聚类,使每个训练矢量得到一个最匹配的索引值对(i, j)。(i, j)应当是通过全搜索得到的全局最佳匹配矢量。在不需要在线更新码本的情况下,全搜索是可以采用的。然而如果在矢量维数较高时,想减小码本训练的运算量,也可以采用M进制序列搜索的方法。取M=8在实验中得到了很好的效果。这样即可得到一个性能近似的简化版JCO-MSVQ码本设计方法。
另外,在码本设计中,可能出现聚类中无训练矢量,即出现空聚类的情况。这时可以删除该空聚类,并将包含训练矢量最多的那个聚类抖动成两个聚类。这样可以获得更小的联合量化误差,如图1所示。
3、 实验结果和分析
实际应用中,码本训练采用107 MB的语音文件,得到342302帧LSF参数(10维)和加权系数,训练矢量集足够大。在实际的2kbps语音编码算法中,对LSF参数进行3级矢量量化,比特分配为9/8/6,共23bits。利用联合优化码本生成算法进行300步迭代,与SR算法的第三级300步迭代结果进行比较,得到训练码本总畸变数据,如图2所示。
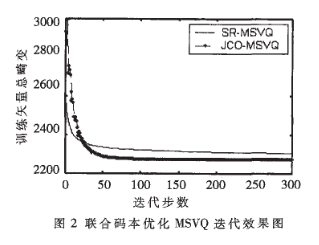
可以看到,同样步数的JCO-MSVQ算法较SR算法能取得更小的量化畸变。SR算法经过一定步数的迭代,基本没有下探的空间。而JCO-MSVQ算法则能继续优化码本,获得更好的量化效果。并且,与SR算法不同,JCO-MSVQ算法中量化畸变是单调递减的,因在训练过程中每一步都是最优的(简化算法中是多进制搜索,因而是次优的)。
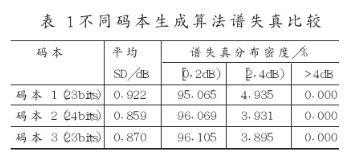
统计量化谱失真,联合码本优化MSVQ比其他的MSVQ有明显的改善。在同一个LSF量化器中分别采用23bits SR码本(码本1)、24bits SR码本(码本2)和23bits联合优化码本(码本3),测试语音为一个3.5MB的语音文件,既有男声也有女声,共11348帧LSF参数。统计量化谱失真得到表1所示数据。
从表1数据可以看到,同是23bits的量化,联合码本设计MSVQ与应用SR算法生成码本的MSVQ相比较,有大约1个比特的改善,接近于应用SR算法24bits量化的效果。甚至优于文献[2]中MSVQ算法的26bits量化(平均谱失真0.93dB)。平均谱失真为0.87dB,大于4dB的谱失真统计为0,达到了透明量化的要求。
本文研究结果已经成功应用于1/2kbps可变速率声码器项目中。
责任编辑:gt
-
什么是CAD矢量化?2020-03-06 2489
-
使用SVE对HACCmk进行矢量化的案例研究2022-11-08 3839
-
基于Hopfield神经网络的图像矢量量化2009-07-11 537
-
基于多级SMVQ的图象编码算法2009-08-07 713
-
一种优化的鞋样图像矢量化方法2009-08-13 612
-
基于小波变换与矢量量化的图像压缩研究2009-12-07 734
-
一种基于暂时分解的高效线谱频率参数量化方法2010-01-12 497
-
一种增强的LPC参数多级矢量量化技术2010-07-05 962
-
MAPGIS矢量化技巧步骤详解2010-10-21 1436
-
基于矢量量化编码的数据压缩算法的研究与实现2009-06-16 2112
-
基于TMS320DM642的最大熵矢量量化实现2018-02-28 1046
-
第2部分:高级代码矢量化和优化2020-05-31 3450
-
矢量化的优点和数据大小的影响2018-11-15 7445
-
矢量化或性能模具:调整最新的AVX SIMD指令2018-11-05 5205
-
压缩感知中的联合信源信道矢量量化2020-11-05 1167
全部0条评论

快来发表一下你的评论吧 !
