

端到端语音交互革命:百度智能云联合地瓜机器人,重塑AI陪伴体验
可编程逻辑
1397人已加入
描述
电子发烧友网报道(文/莫婷婷)随着大模型技术的迅猛发展,人机交互正经历从“工具式响应”向“拟人化陪伴”的深刻变革。在这一进程中,语音交互作为最自然的人机沟通方式。
百度智能云泛科技行业解决方案总监孙颖欣在地瓜机器人的DDC2025 人机交互分论坛上指出,大模型时代的交互方式经历了三个关键阶段的演进:第一阶段是文本、语音交互第二阶段是多模态融合交互,结合语音、视觉、动作等多通道信息提升交互体验;第三阶段则是复杂任务下的主动自主交互,由此催生了陪伴机器人、AI宠物等新型智能硬件形态。
在情感陪伴场景中,拟真互动需满足四大核心要素:一是低时延,响应控制在400到600毫秒内,超过这个范围,体验就会下降;二是有感情且带记忆;三是有个性,例如音色、内容风格具备独特人格特征;四是主动性。这四大要素共同构建了“真实感”与“亲密感”,成为新一代AI硬件成败的关键。
为支撑这一趋势,百度智能云联合地瓜机器人的计算芯片旭日3和旭日5打造了多款语音交互方案,包括多模态互动框架方案、端到端语音交互方案等,可以面向不同产品定位的AI硬件。
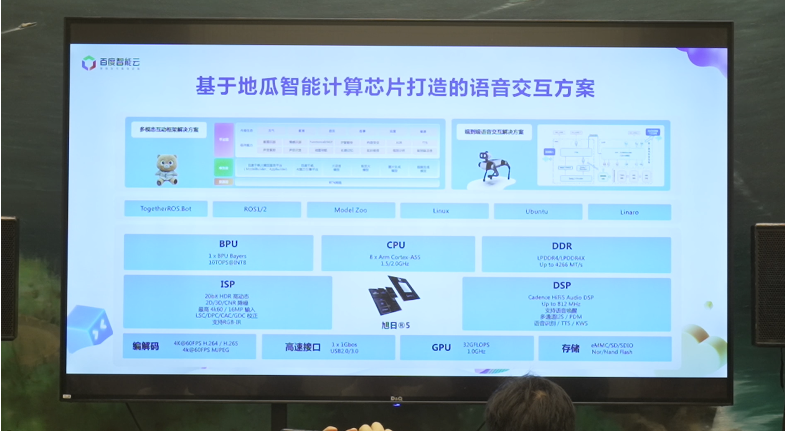
多模态互动框架方案采用的“ASR + 大模型 + TTS”三段式架构,资源层是全球RTN网络,以及GPU/CPU算力,在此基础上深度融合了声纹识别、情绪识别、长期记忆及视觉理解等能力。其既支持百度自研的文心大模型,也允许接入第三方语言或视觉模型;同时无缝对接百度百科、音乐、教育等垂类资源。
百度智能云的端到端语音大模型方案是业界首个基于Cross-Attention的语音语言大模型的方案,不再将语音先转为文本再输入模型,而是直接将原始音频信号(含音色、语调等)作为大模型输入,基于Cross-Attention的语音语言大模型,实现音义联合建模,使模型能精准捕捉“弦外之音”与情绪状态,解决了传统级联式链路“情感丢失、延迟高、打断体验差”等痛点。
端到端语音大模型方案采用高效的全查询注意力EALLQA技术,Encoder与语音识别结合、Decoder与语音合成结合,可以实现对用户question的极速理解,计算量显著降低10倍。
孙颖欣介绍,端到端方案的一大优势是场景泛化能力强。在近场(如智能音箱)可提供细腻情感反馈;在远场则通过前端声学优化与噪声建模,确保在电机轰鸣、多人交谈等复杂环境中依然精准拾音。例如扫地机器人等高噪声场景,通过百度云端到端语音大模型方案的“原生抗噪”能力,可以把扫地机工作时的日常噪声过滤掉,大幅降低了硬件端的麦克风阵列与降噪算法成本。

孙颖欣指出,面对AI陪伴场景,没有最好的方案,只有最合适的路径。例如多模态互动框架方案特别适合需要丰富内容生态与定制化开发的AI玩具、儿童陪伴机器人等产品,还能够构建面向智能家居、AI眼镜穿戴场景。未来,随着大模型持续进化与芯片算力提升,语音交互实现从“功能实现”向“情感连接”的跨越。
打开APP阅读更多精彩内容
百度智能云泛科技行业解决方案总监孙颖欣在地瓜机器人的DDC2025 人机交互分论坛上指出,大模型时代的交互方式经历了三个关键阶段的演进:第一阶段是文本、语音交互第二阶段是多模态融合交互,结合语音、视觉、动作等多通道信息提升交互体验;第三阶段则是复杂任务下的主动自主交互,由此催生了陪伴机器人、AI宠物等新型智能硬件形态。
在情感陪伴场景中,拟真互动需满足四大核心要素:一是低时延,响应控制在400到600毫秒内,超过这个范围,体验就会下降;二是有感情且带记忆;三是有个性,例如音色、内容风格具备独特人格特征;四是主动性。这四大要素共同构建了“真实感”与“亲密感”,成为新一代AI硬件成败的关键。
为支撑这一趋势,百度智能云联合地瓜机器人的计算芯片旭日3和旭日5打造了多款语音交互方案,包括多模态互动框架方案、端到端语音交互方案等,可以面向不同产品定位的AI硬件。
多模态互动框架方案采用的“ASR + 大模型 + TTS”三段式架构,资源层是全球RTN网络,以及GPU/CPU算力,在此基础上深度融合了声纹识别、情绪识别、长期记忆及视觉理解等能力。其既支持百度自研的文心大模型,也允许接入第三方语言或视觉模型;同时无缝对接百度百科、音乐、教育等垂类资源。
百度智能云的端到端语音大模型方案是业界首个基于Cross-Attention的语音语言大模型的方案,不再将语音先转为文本再输入模型,而是直接将原始音频信号(含音色、语调等)作为大模型输入,基于Cross-Attention的语音语言大模型,实现音义联合建模,使模型能精准捕捉“弦外之音”与情绪状态,解决了传统级联式链路“情感丢失、延迟高、打断体验差”等痛点。
端到端语音大模型方案采用高效的全查询注意力EALLQA技术,Encoder与语音识别结合、Decoder与语音合成结合,可以实现对用户question的极速理解,计算量显著降低10倍。
孙颖欣介绍,端到端方案的一大优势是场景泛化能力强。在近场(如智能音箱)可提供细腻情感反馈;在远场则通过前端声学优化与噪声建模,确保在电机轰鸣、多人交谈等复杂环境中依然精准拾音。例如扫地机器人等高噪声场景,通过百度云端到端语音大模型方案的“原生抗噪”能力,可以把扫地机工作时的日常噪声过滤掉,大幅降低了硬件端的麦克风阵列与降噪算法成本。
孙颖欣指出,面对AI陪伴场景,没有最好的方案,只有最合适的路径。例如多模态互动框架方案特别适合需要丰富内容生态与定制化开发的AI玩具、儿童陪伴机器人等产品,还能够构建面向智能家居、AI眼镜穿戴场景。未来,随着大模型持续进化与芯片算力提升,语音交互实现从“功能实现”向“情感连接”的跨越。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
-
具身智能大算力开发平台S600重磅亮相,地瓜机器人引领端云一体机器人进化新范式2025-11-21 1702
-
智能机器人从0到1系统入门课程 带源码课件 百度网盘下载2026-04-11 460
-
AI语音智能机器人开发实战2019-01-04 6579
-
AI智能语音机器人 揭秘让企业电销轻松拓客神器2020-07-21 1324
-
【IoT毕业设计】树莓派开发板+机智云IoT+监测机器人2022-04-27 12089
-
2017CES百度度秘宣布与小鱼在家联合推出DuerOS机器人2017-01-06 1097
-
百度云推出全球智能服务机器人开放平台——ABC Robot2018-06-01 10680
-
百度正式发布远场语音交互技术芯片2019-08-30 914
-
百度智能云与东软集团推出医护助理智能机器人2019-12-22 2933
-
百度端对端语音识别专利揭秘2020-01-08 3888
-
百度大脑UNIT平台提供智能教育机器人的解决方案2020-03-13 1369
-
百度AI开发者大会:汽车机器人是百度对汽车未来发展的判断2021-12-28 2005
-
鲸启智能宣布成为百度文心一言首批生态合作伙伴 AI加持服务机器人2023-05-10 1387
-
机器人市场化的人机语音交互2023-04-03 3027
-
再掀语音交互革命,广和通AI解决方案加速机器人听觉进化2025-08-26 1117
全部0条评论

快来发表一下你的评论吧 !
