

使用ARM926EJ-S与Linux操作系统实现MPEG-4解码软件的设计
描述
1 引 言
MPEG-4视频压缩标准自问世以来受到人们的广泛关注。近几年,嵌入式应用中对MPEG-4播放器的实现已经成为众多厂家的研究热点。视频压缩的重要性以及其标准的发展历程。随着数字化、网络化全球一体化信息时代的来临,包括声音、图形、数据以及图像、影像在内的多媒体信息的维送和处理;其关键在于后编技术。由于MPEG-4系统庞大且需要大量的数据处理,因此在ARM中实现MPEG-4软解码需要对其原算法进行充分的优化才能达到理想的性能。为此研究了一种基于ARM926EJ-S微处理器的MPEG-4解码算法的纯软件实现和优化的方法,通过对解码算法的软件优化,将QVGA格式MPEG-4码流在ARM9平台上的播放速度由原来的10 f/s提高到了37 f/s,完全达到了流畅播放的要求,具有很高的实用价值。目前,视频技术的应用范围很广,如网上可视会议、网上可视电子商务、网上政务、网上购物、网上学校、远程医疗、网上研讨会、网上展示厅、个人网上聊天、可视咨询等业务。
2开发平台及耗时分析
论文研究使用的是基于ARM926EJ-S微处理器的综合开发平台,采用Linux操作系统,Linux是一类Unix计算机操作系统的统称。Linux操作系统的内核的名字也是“Linux”.Linux操作系统也是自由软件和开放源代码发展中最着名的例子。严格来讲,Linux这个词本身只表示Linux内核,但在实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU 工程各种工具和数据库的操作系统。Linux得名于计算机业余爱好者Linus Torvalds.外接320*240(QVGA格式)的LCD显示屏。ARM926EJ-S微处理器的时钟频率为190 MHz;采用5级整数流水线操作,支持32位ARM指令集和16位Thumb指令集以及扩充的DSP指令集;支持数据Cache和指令Cache,具有更高的指令和数据处理能力。
MPEG-4 SP级算法流程图如图1所示。优化的前期工作首先要将MPEG-4解码代码移植到开发平台上,然后对解码各个模块进行运算量和耗时分析,找出优化的重点内容。本文采用长度为376 934 B的AVI码流为测试序列,该码流共95帧,其中包括8个I帧,87个P帧。在未优化前测得的耗时分析结果如表1所示,整个测试序列解码播放完毕耗时10.05 s,解码播放速度只有9.5 f/s.
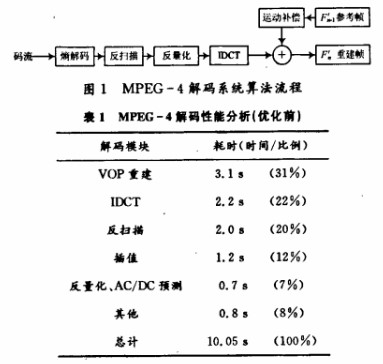
ARM(Advanced RISC Machines)是微处理器行业的一家知名企业,设计了大量高性能、廉价、耗能低的RISC处理器、相关技术及软件。技术具有性能高、成本低和能耗省的特点。适用于多种领域,比如嵌入控制、消费/教育类多媒体、DSP和移动式应用等。在ARM上用软件实现MPEG-4解码器的主要任务是提高解码速度,同时达到理想的画面播放效果。
3 MPEG-4解码算法在ARM926EJ-S上的优化
MPEG-4软解码以开源的XVID源代码做为参考,将XVID的C源代码移植到ARM平台上,在此基础上进行优化并测试优化后的解码播放性能。优化主要从3个方面进行:
(1)对XVID源代码的软件结构,程序流程进行适合ARM特点的调整。
(2)对运算量较大、耗时较多的模块编写汇编函数代替C程序模块,提高程序执行效率。
(3)寻找快速或并行算法。
3.1软件结构的优化
ARM的资源非常有限,在软件的结构安排上应尽量减少存储器访问,增加Cache的命中率,提高程序执行效率。
3.1.1 适当的模块合并处理以减少存储器的访问次数
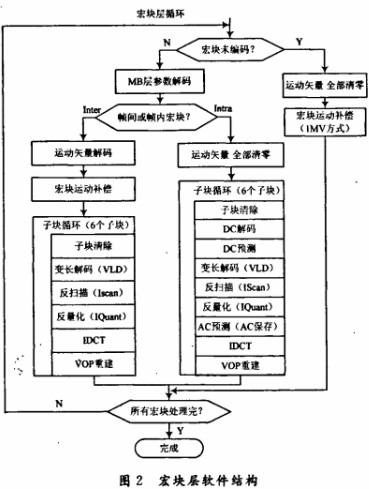
优化前的源代码中,I帧与P帧的宏块解码软件结构如图2所示。在这个流程中,对于inter宏块,可变长解码(VLD),反扫描(Iscan),反量化(Iquant)三个过程中有3次的Block存储区读,2次Block存储区写和1次Data存储区写。源代码是指未编译的按照一定的程序设计语言规范书写的文本文件。 源代码(也称源程序),是指一系列人类可读的计算机语言指令。 在现代程序语言中,源代码可以是以书籍或者磁带的形式出现,但最为常用的格式是文本文件,这种典型格式的目的是为了编译出计算机程序。计算机源代码的最终目的是将人类可读的文本翻译成为计算机可以执行的二进制指令,这种过程叫做编译,通过编译器完成。

合并后VLD从Block缓冲区读数据处理后马上进行反扫描和反量化,并将反量化后的数据存入Block中。整个过程只进行了一次Block缓冲区的读和写,不仅减少了两个读写操作,还减少了一个Data缓冲区的开辟。同时,对于P帧在VLD之后立即进行反量化还省去了大量零值的处理,这也是考虑合并的主要因素之一。
同样,I帧中的AC/DC预测和反量化也可以进行合并。做法是:将add_acdc(pMB,i,&block[i*64],iDcScaler,predictors);dequant_intra(&data[i*64],&block[i*64],iQuant,iDcScaler)两个函数合并为:add_acde(pMB,i,&block[i*64],iDcSealer,predictors,cbpcontrol,iQuant)。这个过程在减少存储器的读写操作的同时也减少了没有预测的AC值的反量化过程。
通过以上两个步骤的合并处理,由测试序列测试之后发现解码播放完毕耗时5.23 s,速度提高了将近9 f/s,效果非常明显。
3.1.2 调整子块处理以增加Cache命中率
MPEG-4每个宏块由6个子块组成。在XVID源代码中,宏块解码中的6个子块的所有处理一起进行,被放在一个大的for循环中。ARM9采用哈佛结构,分别拥有I-cache和D-cache,所有处理同时进行,某一子块的值会一直在D-cache中不被替换,对于D-cache是非常有利的,但是对于I-cache来说却会造成代码的不断替换而影响Cache效率。高速缓冲存储器(Cache)其原始意义是指存取速度比一般随机存取记忆体(RAM)来得快的一种RAM,一般而言它不像系统主记忆体那样使用DRAM技术,而使用昂贵但较快速的SRAM技术,也有快取记忆体的名称。对于I帧,由于其数据量比较大,数据替换的开销会远远大于代码替换。具体的做法是:
这个过程使解码速度提高了将近4 f/s.
另外对于I帧,IDCT与VOP重建也是可以合并的,这个过程可以减少存储器的访问次数。但是这个合并过程不符合ARM的Cache工作特性,因此优化的效果并不明显,这也是优化过程中矛盾折衷的明显体现。
3.2 编写ARM汇编函数
ADS编译器对C程序有很强的编译能力,但对于一些运算量较大,涉及存储器访问较多的模块,仍然需要使用ARM汇编优化。这部分主要是针对耗时较多的IDCT,插值,VOP重建等模块。在书写汇编函数时,要充分把握ARM处理器的特性,ARM处理器特点1、体积小、低功耗、低成本、高性能;2、支持Thumb(16位)/ARM(32位)双指令集,能很好的兼容8位/16位器件;3、大量使用寄存器,指令执行速度更快;4、大多数数据操作都在寄存器中完成;5、寻址方式灵活简单,执行效率高;6、指令长度固定。尽量避开多周期指令,避免流水线阻塞,合理分配寄存器以尽量减少存储器操作。汇编函数的优化包括以下几点:
3.2.1避免多周期指令
在ARM汇编中,相对耗时的指令主要有存储器操作指令load/stor,程序跳转指令B,乘法指令MUL等。在编写汇编函数时,要尽量的考虑这些指令的替换方案。
对于存储器操作指令,可以采用多寄存器传送指令LDM/STM来替换。一次LDR指令需要5个指令周期,而N个寄存器传送的LDM指令只需要N+4个指令周期。IDCT、插值、VOP重建中的数据读取都是连续地址操作,可以一次读人4个甚至更多的数据到寄存器以减少程序的执行指令周期数。
其次,一条程序跳转指令B需要3个指令周期,利用手写汇编可以避免ADS编译C时经常出现的函数跳转指令,同样减少了执行周期数。
3.2.2避免流水线阻塞
ARM9采用五级流水线,执行效率很高,但是如果指令设置不当,很容易造成流水线阻塞而影响执行效率。解决流水线互锁的办法主要是预装载和循环展开。
预装载,即将接下来要用到的数据在不影响寄存器使用的情况下提前两个以上指令周期装载到寄存器中。这。
循环展开,即将循环体内的主体多次循环将循环跳转次数减少。这样不仅可以减少B跳转指令带来的流水线刷新,同时可以在前一个循环中通过预装载下一个循环需要用的数据来避免流水线的互锁。
3.2.3尽量减少存储器操作
将经常使用的数据保持在寄存器中,避免每次用数据时都从存储器读取。尤其在IDCT中,尽量将一行或一列的数据一直保持在寄存器中,寄存器的执行效率是最高的,合理的分配寄存器和利用堆栈可以使程序更优。
一个高效的汇编程序可以使整个性能有较多的改善,通过ARM汇编函数的替换,测试序列解码播放完毕耗时3.1 s,解码速度提高了8 f/s.
3.3寻找快速算法和并行算法
ARM汇编的好处不仅在于执行效率高,还在于可以充分利用ARM处理32位数据的特性,寻找快速算法和并行算法。
对于插值函数,可以采用并行算法来一次处理多个象素。每个象素是一个8位数据,而ARM处理器是32位,因此可以改进算法一次处理4个象素。插值中的关键算法是:
rounding是码流中一个取0或1的参数。我们可以改进这个算法4个象素一起处理。通过分析知道,可以将式(1)改为A/2+B/2+C,C也应该是一个取0或者取1的值。分析的结果发现,当rounding为0时,C=(A∣B)&0X01;当rounding为1时,C=(A&B)&0X01.此时我们可以用4个象素组成两个32位的字W1,W2,利用公式:
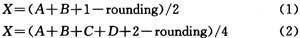
或
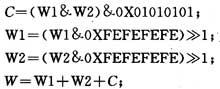
W的结果等同于四个象素单独处理的结果。但是由于ARM处理器字读取时是字地址对齐的,因此要注意改进算法引起的字地址不对齐问题,利用这个算法时可以通过拼字的方法来解决字地址对齐的问题。
通过这一步骤的优化,测试序列解码播放完毕耗时2.56 s,解码速度提高了6 f/s,整体解码速度达到了37 f/s.
4结语
本文对MPEG-4软解码器在ARM平台上的实现及优化的整体思路和步骤进行了阐述,优化结果理想,软解码播放速度由最初移植完毕时的10 f/s提高到了37 f/s.本文给出的优化方案可以进一步推广到H.264或者其他视频软解码系统基于ARM的应用中。全球的视讯业务需求猛增。现有的视讯业务应用主要以政府部门会议为主,在远程教育、远程医疗以及商用方面的应用很少,而国外90%的企业都在使用视讯业务,已是“信息高速公路”的主体通信业务,因此市场潜力巨大。在视讯业务中使用的视频压缩标准作为关键技术,其发展和应用也将是巨大的。
-
Windows作系统可以在 ARM926EJ-S 上运行吗?2025-08-29 245
-
用于ARM926EJ的RealView平台底板-S用户指南2023-08-16 635
-
ARM926EJ-S处理器技术参考手册2023-08-02 1155
-
通过Linux和ARM926EJ-S微控制器实现以太网网络广播的设计2020-03-07 1386
-
ARM926EJ-S应用资料2017-09-13 1181
-
ARM926EJ-S技术参考手册2016-01-11 1535
-
基于ARM926EJ-S的温湿度无线监控系统的设计2011-08-10 7086
-
嵌入式MPEG-4视频流解码系统设计2011-03-24 1199
-
基于RISC的MPEG-4音频解码软件优化2010-07-02 800
-
基于ARM926EJ-S内核的低功耗ARM2010-03-04 1052
-
Linux动态扩展MPEG-4智能视频监控系统2009-12-23 746
-
基于Blackfin533的MPEG-4解码系统实现2009-05-30 889
全部0条评论

快来发表一下你的评论吧 !
