

采用FPGA器件与流水线技术实现浮点乘法器设计
描述
1 引言
在数字化飞速发展的今天,人们对微处理器的性能要求也越来越高。作为衡量微处理器 性能的主要标准,主频和乘法器运行一次乘法的周期息息相关。因此,为了进一步提高微处理器性能,开发高速高精度的乘法器势在必行。同时由于基于IEEE754 标准的浮点运算具 有动态范围大,可实现高精度,运算规律较定点运算更为简捷等特点,浮点运算单元的设计 研究已获得广泛的重视。 本文介绍了 32 位浮点乘法器的设计,采用了基4 布思算法,改进的4:2 压缩器及布思 编码算法,并结合FPGA 自身特点,使用流水线设计技术,在实现高速浮点乘法的同时,也 使是系统具有了高稳定性、规则的结构、易于FPGA 实现及ASIC 的HardCopy 等特点。
2 运算规则及系统结构
2.1 浮点数的表示规则
本设计采用单精度IEEE754 格式【2】。设参与运算的两个数A、B 均为单精度浮点数, 即:
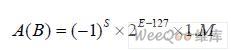
2.2 浮点乘法器的硬件系统结构
本设计用于专用浮点FFT 处理器,因此对运算速度有较高要求。为了保证浮点乘法器 可以稳定运行在80M 以下,本设计采用了流水线技术。流水线技术可提高同步电路的运行 速度,加大数据吞吐量。而FPGA 的内部结构特点很适合在其中采用流水线设计,并且只需 要极少或者根本不需要额外的成本。综上所述,根据系统分割,本设计将采用5 级流水处理, 图1 为浮点乘法器的硬件结构图。
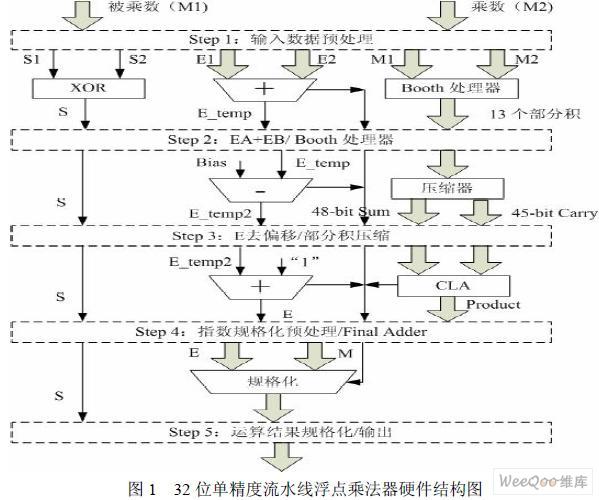
3 主要模块设计与仿真
3.1 指数处理模块(E_Adder)设计
32位浮点数格式如文献【2】中定义。由前述可知,浮点乘法的主要过程是两个尾数相 乘,同时并行处理指数相加及溢出检测。对于32位的浮点乘法器而言,其指数为8位,因而 本设计采用带进位输出的8位超前进位加法器完成指数相加、去偏移等操作,具体过程如下。
E_Adder 模块负责完成浮点乘法器运算中指数域的求和运算,如下式所示:
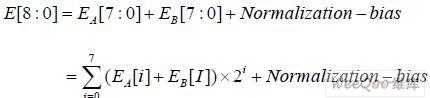
其中,E[8]为MSB 位产生的进位。Bias=127 是IEEE754 标准中定义的指数偏移值。 Normalization 完成规格化操作,因为指数求和结果与尾数相乘结果有关。在本次设计中,通 过选择的方法,几乎可以在Normalization 标志产生后立刻获得积的指数部分,使E_Adder 不处于关键路径。
本设计收集三级进位信号,配合尾数相乘单元的 Normalization 信号,对计算结果进行 规格化处理,并决定是否输出无穷大、无穷小或正常值。
根据 E_Adder 的时序仿真视图,可看出设计完全符合应用需求。
3.2 改进的Booth 编码器设计
由于整个乘法器的延迟主要决定于相加的部分积个数,因此必须减少部分积的数目才能 进而缩短整个乘法器的运算延迟。本设计采用基4 布思编码器,使得部分积减少到13 个, 并对传统的编码方案进行改进。编码算法如表1 所示。
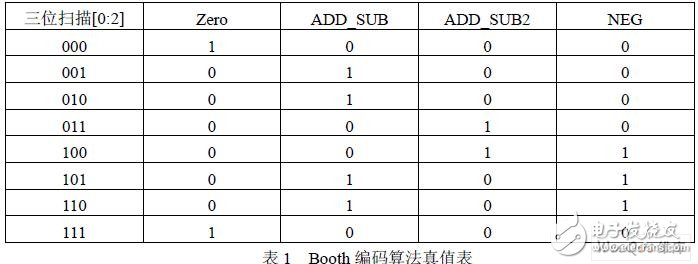
由于 FPGA 具有丰富的与、或门资源,使得该方法在保证速度和准确性的前提下,充分 利用了FPGA 内部资源,节省了面积,同时符合低功耗的要求。
3.3 部分积产生与压缩结构设计
3.3.1 部分积产生结构
根据布思编码器输出结果,部分积产生遵循以下公式【4】:
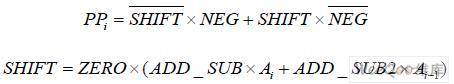
其中,PPi 为部分积;Ai 为被乘数。经过隐藏位和符号位的扩展后,26 位的被乘数尾数将产 生13 个部分积。在浮点乘法器中,尾数运算采用的是二进制补码运算。因此,当NEG=1 时要在部分积的最低位加1,因为PPi 只完成了取反操作。而为了加强设计的并行性,部分 积最低位加1 操作在部分积压缩结构中实现。另外,为了完成有符号数相加,需对部分积的 符号位进行扩展,其结果如图4 所示。13 个部分积中,除第一个部分积是29 位以外,其余 部分积扩展为32 位。其中,第一个部分积包括3 位符号扩展位“SSS”,第2 至13 个部分 积的符号扩展位为“SS”,加一操作位为“NN”,遵循如下公式:
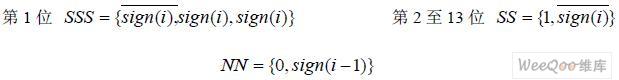
其中,i 为部分积的行数,sign(i)为第i 行部分积的符号。
3.3.2 部分积压缩结构
本设计混合使用 4:2 压缩器、3:2 压缩器、全加器和半加器,实现了13 个部分积的 快速压缩,并保证了精度。本文部分积压缩结构的划分如图2 所示。

图 2 中,虚线给出了传统部分积的压缩划分,而实线描述的是本文采用的部分积压缩结 构划分,这样的划分有利于简化第二级的压缩结构,从而在保证速度的基础上,节省FPGA 内部资源。从图2 中可看出,有些位不必计算,因为这些位是由Booth 编码时引入的乘数尾 数的符号位产生的,48 位足以表达运算结果。
3.3.3 改进的4:2 压缩器
本设计采用广泛使用的 4:2 压缩器,并针对FPGA 内部资源特点,对其进行了改进。 如图3 所示。 传统的 4:2 压缩器即两个全加器级联,共需要四个异或门和8 个与非门。而改进的4: 2 压缩器需要四个异或门和两个选择器(MUX)。8 个与非门需要36 个晶体管,而两个MUX 需要20 个晶体管。同时,FPGA 内部集成了大量的异或门和选择器资源,这种设计方法也是对FPGA 的一个充分利用。
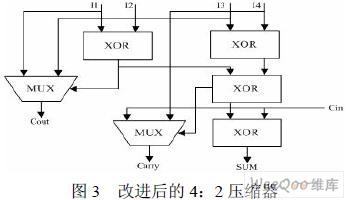
由于压缩部分积需要大量的4:2 压缩器,所以改进的电路能 在一定程度上减小版图的面积,也为该乘法器的ASIC 后端设计带来了优势。另外,改进的 压缩器的4 个输入到输出S 的延时相同,都是3 级XOR 门延时。
4 32 位浮点乘法器的实现与仿真
图 4 显示了本设计的FPGA 时序仿真结果,时序仿真环境为Quartus II 7.0,目标芯片为 Cyclone 系列的EP1C6Q240C8,功能仿真环境为Modelsim 6.0b。整个设计采用VHDL 语言进行结构描述,综合策略为面积优先。由仿真视图可看出,该浮点乘法器可稳定运行在80M 及以下频率,在延时5 个周期后,以后每一个周期可稳定输出一级乘法运算结果,实现了高 吞吐量。如果采用全定制进行后端版图布局布线,乘法器的性能将更加优越。

5 结语
针对FPGA 器件内部资源特性,独创地提出了一种适合FPGA 实现 的5 级流水高速浮点乘法器。该乘法器支持IEEE754 标准32 位单精度浮点数,采用了基4 布思算法、改进的布思编码器、部份积压缩结构等组件,从而在保证高速的前提下,缩小了 硬件规模,使得该乘法器的设计适合工程应用及科学计算,并易于ASIC 的后端版图实现。 该设计已使用在笔者设计的浮点FFT 处理器中,取得了良好效果。
-
蜂鸟E203乘法器改进2025-10-22 109
-
优化boot4乘法器方法2025-10-21 147
-
怎么实现32位浮点阵列乘法器的设计?2021-05-08 2068
-
请问一下高速流水线浮点加法器的FPGA怎么实现?2021-05-07 2036
-
采用Gillbert单元如何实现CMOS模拟乘法器的应用设计2021-03-23 7198
-
乘法器原理_乘法器的作用2021-02-18 28086
-
【梦翼师兄今日分享】 流水线设计讲解2019-12-05 3798
-
怎么设计基于FPGA的WALLACETREE乘法器?2019-09-03 2013
-
使用verilogHDL实现乘法器2018-12-19 11510
-
一种高速流水线乘法器结构2018-03-15 1241
-
基于FPGA的高速流水线浮点乘法器设计与实现2012-02-29 4161
-
基于FPGA 的单精度浮点数乘法器设计2010-09-29 781
-
基于Pezaris 算法的流水线阵列乘法器设计2010-08-02 635
-
高速流水线浮点加法器的FPGA实现2010-02-04 2765
全部0条评论

快来发表一下你的评论吧 !
