

基于Lucene实现全文搜索引擎MYSearch的构建
描述
互联网最初设计是为了能提供一个通讯网络,即使一些地点被核武器摧毁也能正常工作。如果大部分的直接通道不通,路由器就会指引通信信息经由中间路由器在网络中传播。 最大的搜索引擎Google从2002年的10亿网页增加到现在近40亿网页;最近雅虎搜索引擎号称收录了45亿个网页;国内的中文搜索引擎百度的中文页面从两年前的7 000万页增加到了现在的2亿多。据估计,当前整个互联网的网页数达到100多亿,而且还在快速增长。用户要在如此浩瀚的信息海洋里寻找信息,犹如“大海捞针”,往往无功而返。如何从资源的海洋里找到自己需要的内容就成了关键问题,搜索引擎的出现和研究,使网络上的资源变得有序,使用户能更加方便快捷地找到所需资源。目前被大家广泛使用的搜索引擎如Google、百度等,其实现技术非常复杂,后台数据库也非常庞大,更新速度也很快。
1 Lucene基本技术原理
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse[9]的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere[10]中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
目前网络上有许多全文搜索引擎的开源代码,若想构建自己的全文搜索引擎,可以在这些开源代码的基础上进行。Lucene不是一个完整的全文索引应用,可以直接作为查询工具使用,而只是为全文搜索引擎的构建提供了基本的工具和设计方法。Lucene提供了一系列API,能够对文档进行预处理、过滤、分析、索引和检索排序。本文就是在Lucene基础上构建了一个全文搜索引擎MYSearch。
2 MYSearch工作流程
2.1 搜索引擎的基本构成
搜索引擎系统一般由蜘蛛(也叫网页爬行器)、切词器、索引器、查询器几部分组成。蜘蛛负责网页信息的抓取工作;一般情况下切词器和索引器一起使用,它们负责将抓取的网页内容进行切词处理并自动进行标引,建立索引数据库;查询器根据用户查询条件检索索引数据库并对检索结果进行排序和集合运算,再提取网页简单摘要信息反馈给查询用户。
2.2 MYSearch工作流程
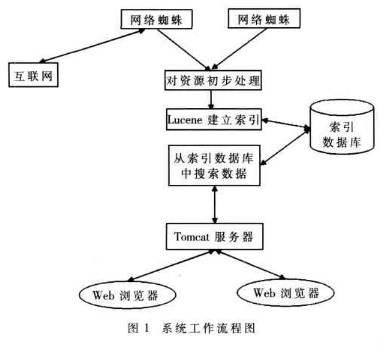
MYSearch首先使用网络蜘蛛抓取网络上的可用网页链接,然后把抓取到的网页资源下载到本地计算机,对下载到本地计算机的网页进行初步的处理,去掉对搜索没有意义的信息和词汇。然后使用Lucene提供的索引功能,对处理后的信息资源建立索引,并且保存到索引数据库中。之后,根据用户提供的搜索信息,在索引中进行查询,并将搜索结果显示到用户搜索的界面上。其流程框图如图1所示。
3 MYSearch实现
3.1 系统功能模块的划分
MYSearch全文搜索系统主要分为网络蜘蛛抓取、资源初步处理、建立索引、搜索以及显示等功能模块。
(1)网络蜘蛛抓取功能模块:首先根据事先设定好的网络入口地址和设置的搜索条件,读取网页的内容,分析网页中其他的链接地址,然后垂直链接到下一个网页,这样一直循环,直到网站的所有网页都抓取完成或者满足了搜索的条件为止。
(2)资源初步处理功能模块:将搜索来的网页中的信息进行相关处理,去掉没有用的格式内容和其他对搜索结果没有实际意义的信息。
(3)建立索引功能模块:将处理后的网页资源写入数据库,并使用倒排索引算法实现网页资源索引的建立。
(4)搜索功能模块:根据用户的搜索关键词,在已建好索引的数据库中,根据语素向量的匹配度和相似度进行相关的匹配,然后按照一定的排列顺序把搜索结果返回给用户。
(5)显示功能模块:将搜索结果按照一定的显示方式显示在页面中,供用户选择和浏览。
3.2 MYSearch全文搜索引擎的实现
3.2.1 网络蜘蛛
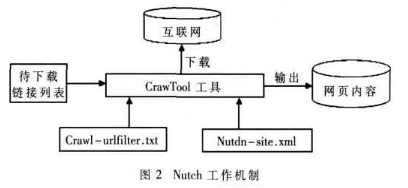
网络蜘蛛是指某个能以人类无法达到的速度不断重复执行某项任务的自动程序[1]。本系统中使用的蜘蛛程序是Nutch,核心是Crawl工具。它可以根据之前设定好的入口URL列表不断地自动下载页面,直到满足系统预设的停止条件。图2所示是Nutch的工作机制。
3.2.2 网页初步处理
网页刚刚被抓取下来的时候,存在很多格式化的信息(如html的网页标记),还有很多多余的信息(比如“is,the,an”)。这些信息都是噪音,如果想要使搜索引擎更高效、更准确地运行,就要去除这些信息,留下有效的信息。
对于html标记的处理,首先就是准备一个空字符串,然后判断网页的文字中是否存在html的“<>”符号,如果是html“<>”的符号,就继续判断网页中的下一个字符,如果不是就把该字符保存到这个空字符串中;如果判断完成,就结束;否则就继续判断。对于多余信息,在Lucene中提供了相关的包进行处理。
通过上面的处理之后,下载的文件在建立索引的时候,就会更加便捷。
3.2.3 索引的建立
在日常的生活中,往往需要快速地从海量页面信息中定位页面资源。这样的需求就需要用索引技术来实现。索引建立的好坏直接影响搜索效果和用户的体验感觉,所以索引的建立方法十分重要。Lucene采用倒排索引算法建立索引[2],主要包括索引类(IndexWriter)、文档对象类(Document)和信息字段对象类(Field)。索引建立的过程为:
(1)建立索引器IndexWriter;
(2)建立文档对象Document;
(3)建立信息字段对象Field;
(4)将Field添加到Document;
(5)将Document添加到IndexWriter里面;
(6)关闭索引器IndexWriter。
Lucene将建好的索引信息存储在“_0.cfs”、“segments.gen”以及“segments_s”文件中。
3.2.4 信息搜索
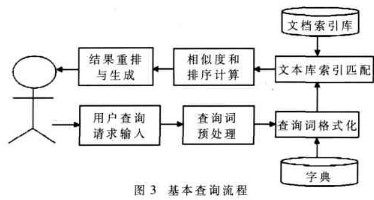
用户提交的查询请求通常是一个词语或者短语,MYSearch搜索引擎在接受用户访问后会进行一系列处理并最终向用户提交。当用户输入关键词搜索后,由搜索程序从索引数据库中找到符合该关键词的所有相关文档。因为所有文档针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序。排序规则是相关度越高,排名就越靠前。然后,就会把查询到的信息返回给用户,并进行显示。基本查询流程如图3所示。
3.2.5 搜索结果显示
良好的交互设计可以使用户的操作更加简便,可以使用户能够更快更准确地找到自己想要的信息,同时能够增加用户的满意度。MYSearch全文搜索引擎设计了一个简捷的搜索界面,用户在该界面中输入搜索条件,提交后就可以看到查询结果。
4 改进
搜索引擎(search engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。分词就是为生成索引提供原材料,如果分词分得不明确,则生成的索引必然复杂,那些没有实际意义的分词被称为噪音,噪音多了搜索速度必然下降。Lucene其实自身是带有中文分词功能的,主要采用“单字切分”和“二分法”,但是由于它没有做到确定最小索引项,因此无法去除噪音,搜索效率大大降低。IK_Canalyzer中文分析器是第三方实现的分析器,继承自Lucene的Analyzer类。图4(a)和图4(b)分别为采用Lucene与IK_Canalyer分词的显示结果,可明显看出后者优于前者。

全文索引引擎是名副其实的搜索引擎,国外代表有Google,国内知名的百度搜索。它们从互联网提取各个网站的信息(以网页文字为主),建立起数据库,并能检索与用户查询条件相匹配的记录,按一定的排列顺序返回结果。
MYSearch是基于Lucene设计实现的一个全文搜索引擎,本文给出了设计过程以及实验结果,并针对Lucene在中文分词方面的不足给出了解决办法。此外目前可以获得的Lucene开源代码中并没有对PDF、Word、Excel等常用的文本格式进行搜索。要想克服上述问题,就要对不同格式的文本进行解析,把解析出来的文字提取出纯文本,然后就像建立网页的索引一样,对提出来的文字建立索引,以便查询。这将是进一步需要改进MYSearch全文搜索引擎的工作重点。
根据搜索结果的不同,全文搜索引擎可分为两类:一类拥有自己的网页抓取、索引、检索系统(Indexer),有独立的“蜘蛛”(Spider)程序、或爬虫(Crawler)、或“机器人”(Robot)程序(这三种称法意义相同),能自建网页数据库,搜索结果直接从自身的数据库中调用,上面提到的Google和百度就属于此类;另一类则是租用其他搜索引擎的数据库,并按自定的格式排列搜索结果,如Lycos搜索引擎。
-
参加搜索引擎营销SEM培训的好处?2011-04-11 3404
-
基于网格技术的并行搜索引擎2009-03-30 959
-
维、哈、柯全文搜索引擎检索器的关键技术2009-04-11 719
-
基于压缩后缀数组技术的搜索引擎2009-04-22 922
-
教育网BBS搜索引擎设计与实现2009-06-17 1172
-
化工搜索引擎索引库的研究和实现2009-12-18 879
-
开放源代码的全文检索引擎 Lucene2010-02-10 1033
-
主题搜索引擎的研究2010-07-05 1076
-
网络搜索引擎,网络搜索引擎的工作原理2010-03-26 1759
-
基于JAVA技术的搜索引擎的研究与实现2012-05-07 1905
-
一种校内网资源搜索引擎的设计与实现2012-05-09 1402
-
垂直搜索引擎是什么_垂直搜索引擎有哪些2018-01-04 8904
-
介绍五个具有高级功能的搜索引擎2018-04-04 8325
-
苹果自研的搜索引擎干的过谷歌吗?2020-12-22 2827
-
NAS下搭建linux命令搜索引擎教程2023-02-24 2054
全部0条评论

快来发表一下你的评论吧 !
