

基于Quartus II的综合仿真实现FFT IP核的FFT算法
描述
引 言
数字信号处理领域中FFT算法有着广泛的应用。目前现有的文献大多致力于研究利用FFT算法做有关信号处理、参数估计、F+FT蝶形运算单元与地址单元设计、不同算法的FFT实现以及FFT模型优化等方面。而FPGA厂商Altera公司和Xilinx公司都研制了FFT IP核,性能非常优越。在FFT的硬件实现中,需要考虑的不仅仅是算法运算量,更重要的是算法的复杂性、规整性和模块化,而有关利用FFT IP核实现FFT算法却涉及不多。这里从Altera IP核出发,建立了基4算法的512点FFT工程,对不同参数设置造成的误差问题进行分析,并在EP2C70F896C8器件上进行基于Quartus II的综合仿真,得到利用FFT IP核的FFT算法高效实现,最后利用Matlab进行的计算机仿真分析证明了工程结果的正确性。
1 算法原理
FFT算法是基于离散傅里叶变换(DFT),如式(1)和式(2):
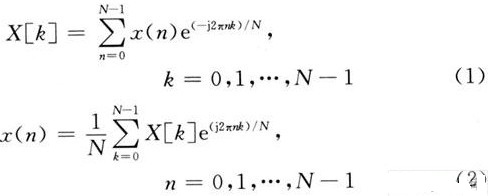
求和运算的嵌套分解以及复数乘法的对称性得以实现。其中一类FFT算法为库利一图基(Cooley-Tukey)基r按频率抽选(DIF)法,将输入序列循环分解为N/r个长度为r的序列,并需要logr N级运算。算法的核心操作是蝶型运算,蝶型运算的速度直接影响着整个设计的速度。
基4频域抽取FFT算法是指把输出序列X(k)按其除4的余数不同来分解为越来越短的序列,实现x(n)的DFT算法。FFT的每一级的运算都是有N/4个蝶形运算构成,第m级的一个蝶形运算的四节点分别为Xm(k),Xm(k+N/4m),Xm(k+2N/4m)以及Xm(k+3N/4m),所以每一个蝶形运算结构完成以下基本迭代运算:
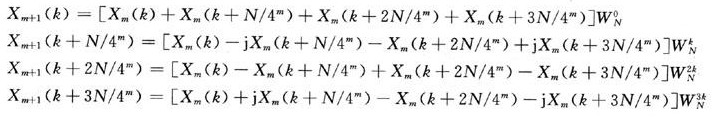
式(3)~式(6)中:m表示第m级蝶形算法;k为数据所在的行数;N为所要计算的数据的点数;WN为旋转因子。
将输入序列循环分解为4点序列的基4分解,使用4点FFT在乘法上更具优势,Altera的:FFT兆核选用的就是基4运算,若N是2的奇数幂的情况下,FFT IP核则自动在完成转换的最后使用基2运算。
2 FFT兆核(IP)函数
FFT Core支持4种I/O数据流结构:流(Stream-ing)、变量流(Variable Streaming)、缓冲突发(BufferedBurt)、突发(Burst)。流结构允许输入数据连续处理,并输出连续的复数据流,这个过程不需要停止FFT函数数据流的进出。变量流结构允许输入数据连续处理,并产生一个与流结构相似连续输出数据流。缓冲突发数据流结构的FFT需要的存储器资源比流动I/O数据流结构少,但平均模块吞吐量减少。突发数据流结构的执行过程和缓冲突发结构相同,不同的是,对于给定参数设置,突发结构在降低平均吞吐量的前提下需要更少的存储资源。
3 FFT处理器引擎结构
FFT兆核函数可以通过定制参数来使用两种不同的引擎结构:四输出(Quad-outlput)或单输出(Signal-output)引擎结构。为了增加FFT兆核函数的总吞吐量,也可以在一个FFT兆核函数变量中使用多个并行引擎。本文建立一个基于QuartusⅡ7.O计算24位512点FFT工程,采用四输出FFT引擎结构,如图1所示。
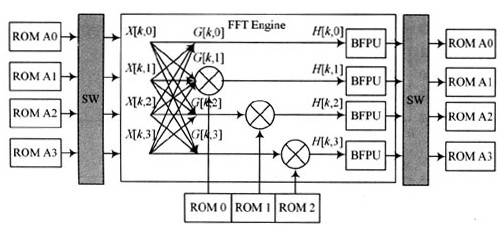
复取样数据X[k,m]从内部存储器并行读出并由变换开关(SW)重新排序,排序后的取样数据由基4处理器处理并得到复数输出G[k,m],由于基4按频率抽选(DIF)分解方法固有的数字特点,在蝶形处理器输出上仅需要3个复数乘法器完成3次乘旋转因子(有一个因子为1,不需要乘)计算。这种实现结构在一个单时钟周期内计算所有四个基4蝶形复数输出。
同时,为了辨别取样数据的最大动态范围,四个输出由块浮点单元(BFPU)并行估计,丢弃适当的最低位(LSB),在写入内部存储器之前对复数值进行四舍五入并行重新排序。对于要求转换时间尽量小的应用,四输出引擎结构是最佳的选择;对于要求资源尽量少的应用,单输出引擎结构比较合适。为了增加整个FFT吞吐量,可以采用多并行的结构。
4 系统验证
4.1 工程仿真
选择CycloneⅡ系列的EP2C70F896C8芯片来实现,先在QuartusⅡ软件下进行综合仿真,初始化参数设置FFT变换长度为512点,数据和旋转因子精度为24 b,选择缓冲突发的数据流结构,四输出引擎并行FFT引擎个数为4个,复数乘法器结构为“4/Mults/2Adders”。EP2C70F896C8芯片包括68 416个逻辑单元,31 112个寄存器单元,最大用户输入/输出引脚622个,总RAM达1 152 000 b,其布线资源由密布的可编程开关来实现相互间的连接,这种结构完全符合实现FFT电路的要求。
经综合和时序分析得知:其工作时钟频率
69.58 MHz(period=14.372 ns),进行一次蝶形运算只需约14 ns,全部512点数据处理完成则需14.372×4×512=29.3μs满足时序要求。具体综合结果如图2所示,为Quartus软件环境下仿真得到。

图3则表明了FFT的综合逻辑结果,为编译成功后的RTL级电路描述。
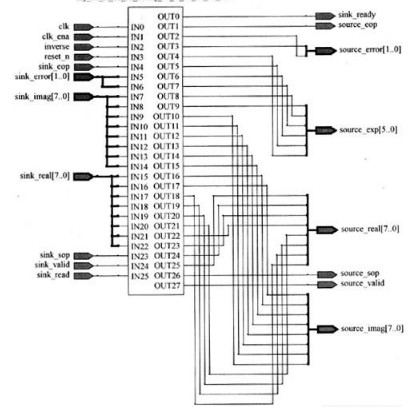
FFT处理器模块采用缓冲突发数据流结构的信号时序图如图4所示,在系统复位信号(reset_n)变为低电平后,数据源将sink_ready信号置高电平,表明有能力接收输入信号。数据源加载第一个复数数据样点到FFT函数中,同时将sink_sop信号置高电平,表示输入模块的开始。在下一个时钟周期,sink_sop信号被复位,并以自然顺序加载后面的N-1个复输人数据样点。
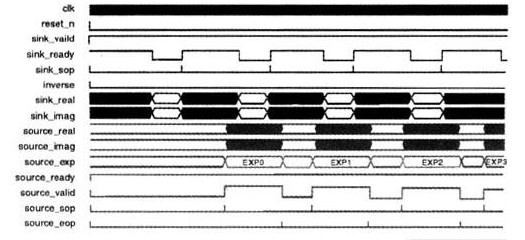
当完全载入输入模块时,FFT函数复位sink_ena信号,表示FFT不再接收其他输入数据并开始计算输入数据模块的变换结果。在FFT处理器内部输入缓冲区读取样点之后,FFT将sink_ena信号重新置高电平,准备读取下一个输入模块。下一个输入模块的起点由sink_sop脉冲确定。当FFT完成了输入模块的变换,并且从设备汇端将source_ready信号(表示数据从设备接收器可以接收输出数据模块)置高电平,并且以自然顺序输出复数变换域数据模块。
4.2 仿真结果分析
在编译综合后,工程当中含有基于FFT IP核生成的Matlab文件,这样就可在Matlab下对工程结果进行进一步测试,构建信号,并与Matlab计算的理论结果进行比较。设输入函数为z(t)=20 000sin(20πt),点数N=512,采样频率为500 Hz,即采样间隔为O.002 s,采样的时间长度为O.002 x 512 s,该正弦信号通过512点FFT处理结果如图5所示,正弦信号基于IP核Matlab文件仿真结果如图6所示。
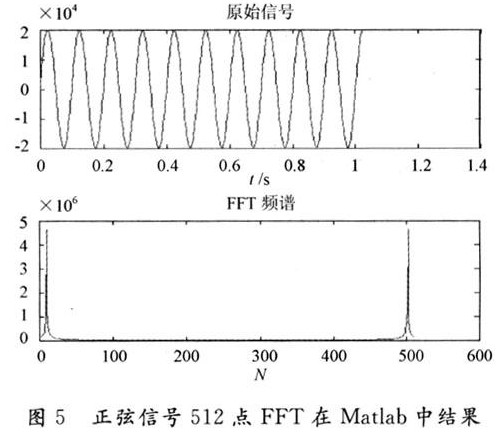
由图5,图6比较可以看出FFT、处理器处理后的结果和Matlab计算的理论结果基本一致。都在第11点和第503点取得最大FFT绝对值,两者的误差只是在FFT频谱绝对值的幅度大小原因:一是Altera FFT兆核函数的块浮点输出与Matlab这种全精度FFT的输出相比,存在最低位(LSB)被丢弃的影响;二是工程初始化IP核采用的数据精度取24位(V7.0 IP最大支持24位数据精度)。
5 结 语
在利用FFT IP核进行FFT算法实现的同时,对仿真结果做了全面分析,由于IP核的可塑性很强,增加了芯片的灵活性。使用Altera FFT的IP Core大大减少了产品的开发时间,Altera还可进一步实现加窗功能,甚至DDC部分(单端信号向I/Q转换)整合到其FFT处理器模块中,能进一层次简化开发的流程,在今后实际工程应用中高效利用。
-
Quartus中FFT模块中文说明2012-08-12 12227
-
fft ip核仿真的验证2012-09-20 4339
-
在做FFT IP核的仿真时遇到问题,居然不能生成FFT的仿真文件,求解答2016-10-07 10745
-
xilinx FPGA的FFT IP核的调用2016-12-25 6491
-
fft ip核 仿真问题2017-11-21 5104
-
有关modelsim仿真fft核出现的错误2019-02-26 6319
-
QUARTUS 13.1在生成FFT IP核时仿真文件生成不了?2019-04-03 4473
-
基于FPGA的FFT和IFFT IP核应用实例2019-08-10 6092
-
利用FFT IP Core实现FFT算法2008-01-16 7859
-
Quartus中fft ip core的使用2011-05-10 2256
-
基于Xilinx_FPGA_IP核的FFT算法的设计与实现2016-05-24 911
-
FFT变换的IP核的源代码2016-06-07 887
-
可配置FFT IP核的实现及基础教程2017-11-18 12407
-
Xilinx FFT IP介绍与仿真测试2022-03-30 4149
-
Vivado中FFT IP核的使用教程2024-11-06 5547
全部0条评论

快来发表一下你的评论吧 !
