

深入解析NVIDIA Nemotron 3系列开放模型
描述
这一全新开放模型系列引入了开放的混合 Mamba-Transformer MoE 架构,使多智能体系统能够进行快速长上下文推理。
代理式 AI 系统日益依赖协同运行的智能体集合,包含检索器、规划器、工具执行器、验证器等,它们需在大规模上下文上长时间协同工作。这类系统需要能够提供快速吞吐、高推理精度及大规模输入持续一致性的模型。它们也需要一定的开放性,使开发者能够在任意运行环境定制、扩展和部署模型。
NVIDIA Nemotron 3 系列开放模型 (Nano、Super、Ultra)、数据集和技术专为在新时代构建专业代理式 AI 而设计。
该系列引入了异构 Mamba-Transformer 混合专家 (mixture-of-experts, MoE) 架构、交互式环境强化学习 (reinforcement learning, RL),以及原生 100 万 token 上下文窗口,可为多智能体应用提供高吞吐量、长时推理能力。
Nemotron 3 的新特性
Nemotron 3 引入了多项创新技术,可精准满足代理式系统需求:
混合 Mamba-Transformer MoE 主干提供出色的测试时效率与长程推理能力。
围绕真实世界代理式任务设计的多环境强化学习。
100 万 token 上下文长度支持深度多文档推理与长时间智能体记忆。
开放透明的训练管道,包含数据、权重及方案。
Nemotron 3 Nano 现已推出并附带现成使用指南。Super 与 Ultra 将于稍晚发布。
简单提示示例
Nemotron 3 模型的核心技术
混合 Mamba-Transformer MoE 架构
Nemotron 3 将三种架构整合成一个主干:
Mamba 层:实现高效序列建模
Transformer 层:保障推理精度
MoE 路由:实现可扩展计算效率
Mamba 层擅长以极低显存开销追踪长程依赖,即使处理数十万 token 仍能保持稳定的性能。Transformer 层通过精细注意力机制对此进行了补充,捕捉例如代码操作、数学推理或复杂规划等任务所需的结构与逻辑关联。
MoE 组件在不增加密集计算开销的前提下提升了有效参数数量。每个 token 仅激活一部分专家,从而降低了延迟并提高了吞吐量。该架构特别适合需要同时运行大量轻量级智能体的集群场景,每个智能体都生成计划、检查上下文或执行基于工具的工作流。
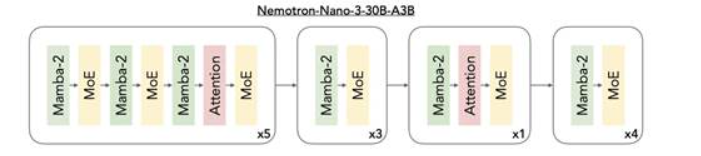
图 1:Nemotron 3 混合架构。该模型通过交错部署 Mamba-2 与 MoE 层,辅以少量自注意力层,在保持领先精度的同时实现推理吞吐量最大化。
多环境强化学习 (RL) 训练
为使 Nemotron 3 契合真实代理式行为,该模型在 NeMo Gym(一个用于构建和扩展 RL 环境的开源库)中通过跨多种环境的强化学习进行后训练。这些环境评估模型执行连续动作序列的能力(不仅是单次响应),例如生成正确的工具调用、编写功能性代码,或生成满足可验证标准的多步骤计划。
这种基于轨迹的强化学习带来了在多步骤工作流中表现稳定的模型,减少推理漂移,并能处理代理式管道中常见的结构化操作。由于 NeMo Gym 是开源的,开发者可在为特定领域任务定制模型时复用、扩展甚至创建自己的环境。
这些环境和 RL 数据集连同 NeMo Gym 一起上线,供有意使用这些环境训练自己模型的用户使用。
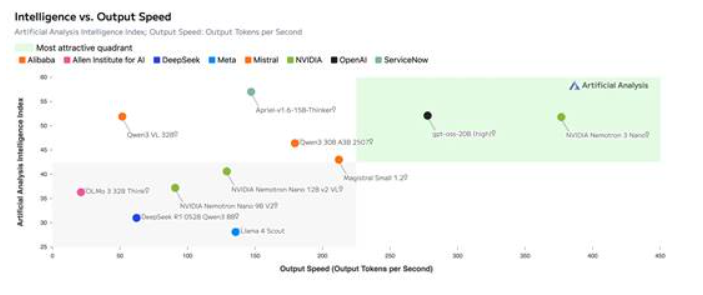
图 2:Nemotron 3 Nano 通过混合 MoE 架构实现极高的吞吐效率,并借助 NeMo Gym 的先进强化学习技术达到领先精度
100 万 token 上下文长度
Nemotron 3 的 100 万 token 上下文使其能够在大型代码库、长文档、扩展对话及聚合检索内容中进行持续推理。智能体无需依赖碎片化的分块启发式方法,就可以在单个上下文窗口中完整保留证据集、历史缓冲及多阶段计划。
这种长上下文窗口得益于 Nemotron 3 的混合 Mamba-Transformer 架构,它能够高效处理超大规模的序列。MoE 路由也能保持较低的单个 token 计算成本,使得在推理时处理这些大型序列成为可能。
对于企业级检索增强生成、合规性分析、多小时智能体会话或整体存储库理解等场景,100 万 token 窗口可显著加固事实基础并减少上下文碎片化。
Nemotron 3 Super 与 Ultra 的核心技术
潜在 MoE
Nemotron 3 Super 与 Ultra 引入了潜在 MoE,其中专家先在共享潜在表示中运行,然后再将输出结果投影回 token 空间。该方法使模型能够在相同推理成本下调用多达 4 倍的专家,从而更好地围绕微妙语义结构、领域抽象或多跳推理模式实现专业化。
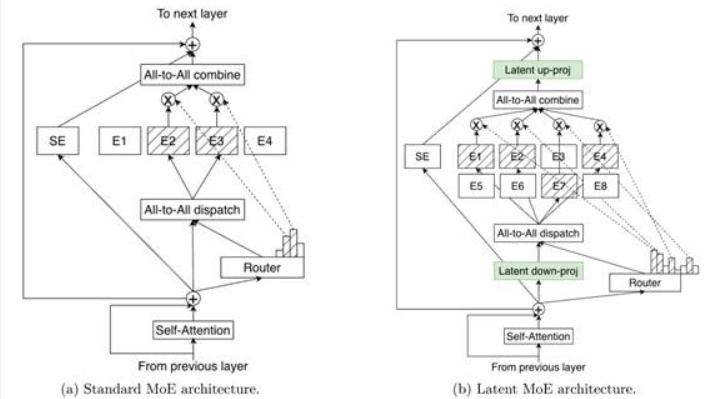
图 3:标准 MoE 与潜在 MoE 架构对比。在潜在 MoE 中,token 被投影至更小的潜在维度进行专家路由与计算,在降低通信成本的同时支持更多专家参与,并提高每字节精度。
多 token 预测 (MTP)
MTP 使模型能够在一次前向传播中预测多个未来 token,从而显著提高长推理序列和结构化输出的吞吐量。对于规划、轨迹生成、扩展思维链或代码生成,MTP 可降低延迟并提高智能体的响应速度。
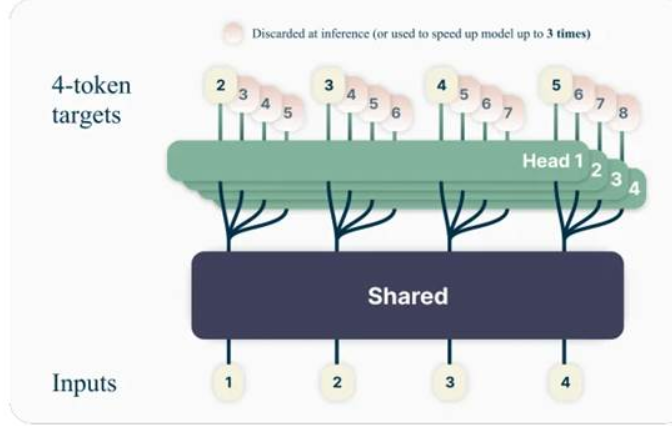
图 4:多 token 预测(源自论文《通过多 token 预测实现更优更快的大语言模型》)可同时预测多个未来 token,在训练阶段将精度提高约 2.4%,在推理阶段实现了推测性解码加速。
NVFP4 训练
Super 与 Ultra 模型采用 NVFP4 精度进行预训练,NVIDIA 的 4 位浮点格式可为训练与推理提供业界领先的成本精度比。我们为 Nemotron 3 设计了更新版 NVFP4 方案,确保在 25 万亿 token 预训练数据集上能够实现精准且稳定的预训练。预训练过程中的大部分浮点乘加运算均采用 NVFP4 格式。
持续致力于开放模型
Nemotron 3 彰显了 NVIDIA 对透明度与开发者赋能的承诺。该模型的权重已根据 NVIDIA 开放模型许可协议 (NVIDIA Open Model License) 公开发布。NVIDIA 的合成预训练语料库(近 10 万亿 token)可以被查阅或重用。开发者还可获取 Nemotron GitHub 库中的详细训练与后训练方案,实现完全的可复现性与定制化。
Nemotron 3 Nano 已发布,为高吞吐量、长上下文代理式系统奠定了基础。Super 与 Ultra 将于 2026 年上半年发布,将在此基础上进一步深化推理能力和提高架构效率。
Nemotron 3 Nano 现已发布
系列首款模型 Nemotron 3 Nano 已于近日发布。这个总参数 300 亿、激活参数 30 亿的模型专为 DGX Spark、Hopper GPU 及 Blackwell GPU 设计,让用户能够使用 Nemotron 3 系列中较高效的模型进行开发。
如果您想要了解更多关于 Nemotron 3 Nano 的技术细节,可访问 Hugging Face 博客,或阅读技术报告。
该模型可达到极高的吞吐量效率,在 Artificial Analysis Intelligence Index 上成绩领先,并且在 Artificial Analysis Openness Index 上保持了与 NVIDIA Nemotron Nano V2 相同的分数。这充分展现了其在多智能体任务中的高效性,同时兼具透明度与可定制性。
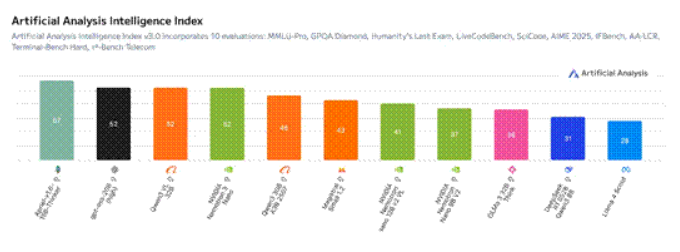
图 5:在 Artificial Analysis Intelligence Index v3.0 上,Nemotron 3 Nano 的精度(52)领先于同等规模模型。
开发者现可在多种部署与开发工作流中使用 Nemotron 3 Nano:
通过 NVIDIA 使用指南启动模型
我们为多个主流推理引擎提供现成使用指南:
vLLM 使用指南:通过高吞吐量连续批处理和流式输出部署 Nemotron 3 Nano。
SGLang 使用指南:运行专为多智能体工具调用工作负载优化的快速、轻量级推理。
TRT LLM 使用指南:部署专为低延迟生产级环境完全优化的 TensorRT LLM 引擎。
每套使用指南均包含配置模板、性能优化建议及参考脚本,助您在数分钟内启动 Nemotron 3 Nano。
此外,从 GeForce RTX 台式电脑 / 笔记本电脑、RTX Pro 工作站到 DGX Spark,您可以立即在任意 NVIDIA GPU 上使用 Nemotron,并借助 Llama.cpp、LM Studio 和 Unsloth 等顶级框架与工具上手。
使用 Nemotron 开放训练数据集进行开发
NVIDIA 同时发布了在整个模型开发期间使用的开放数据集,为高性能、可信模型的构建带来了空前的透明度。
新数据集的特点包括:
Nemotron 预训练:新的 3 万亿 token 数据集,通过合成增强与标注管道进行增强,更加全面地覆盖代码、数学及推理场景。
Nemotron 后训练3.0:1,300 万样本语料库,用于监督式微调与强化学习,为 Nemotron 3 Nano 的对齐与推理能力提供支持。
Nemotron 强化学习数据集:精选的强化学习数据集与环境集合,涵盖工具使用、规划及多步骤推理。
Nemotron 智能体安全数据集:近 1.1 万条 AI 智能体工作流轨迹集合,帮助研究人员评估和减轻代理式系统中的新型安全风险。
配合 NVIDIA NeMo Gym、RL、Data Designer 及 Evaluator 开放库,这些开放数据集使开发者能够训练、增强和评估他们自己的 Nemotron 模型。
探索 Nemotron GitHub:预训练与强化学习方案
NVIDIA 维护着一个开放的 Nemotron GitHub 库,其中包含:
预训练方案(已发布),展示 Nemotron 3 Nano 的训练过程
用于多环境优化的强化学习对齐方案
数据处理管道、分词器配置及长上下文设置
后续更新将加入更多后训练与微调方案
如果您想训练自己的 Nemotron、扩展 Nano 或创建特定领域的变体,GitHub 库提供了文档、配置及工具,可从头至尾重现关键步骤。
这种开放性实现了完整闭环:您可以运行、部署模型,查验模型的构建方式,甚至训练您自己的模型,全程仅需使用 NVIDIA 开放资源。
Nemotron 3 Nano 现已上线。即刻开始使用 NVIDIA 开放模型、开放工具、开放数据及开放训练基础设施,构建长上下文、高吞吐量的代理式系统。
Nemotron 模型推理挑战赛
加速开放研究是 Nemotron 团队的核心使命。为此,我们十分高兴地宣布一项新的社区竞赛,其内容是使用 Nemotron 的开放模型与数据集提高 Nemotron 的推理性能。
关于作者
Chris Alexiuk 是 NVIDIA 的深度学习开发者倡导者,负责创建技术资源,帮助开发者使用 NVIDIA 提供的一整套强大 AI 工具。Chris 拥有机器学习和数据科学背景,对大型语言模型的一切充满热情。
Shashank Verma 是 NVIDIA 的一名深入学习的技术营销工程师。他负责开发和展示各种深度学习框架中以开发人员为中心的内容。他从威斯康星大学麦迪逊分校获得电气工程硕士学位,在那里他专注于计算机视觉、数据科学的安全方面和 HPC 。
Chintan Patel是NVIDIA的高级产品经理,致力于将GPU加速的解决方案引入HPC社区。 他负责NVIDIA GPU Cloud注册表中HPC应用程序容器的管理和提供。 在加入NVIDIA之前,他曾在Micrel,Inc.担任产品管理,市场营销和工程职位。他拥有圣塔克拉拉大学的MBA学位以及UC Berkeley的电气工程和计算机科学学士学位。
-
NVIDIA Nemotron 3 Ultra开放模型正式上线2026-06-09 365
-
NVIDIA发布Nemotron 3 Nano Omni开放式多模态模型2026-05-08 741
-
NVIDIA开放模型助力构建下一代数字健康智能体2026-03-25 652
-
NVIDIA与亚马逊云科技深化合作伙伴关系2026-03-23 618
-
NVIDIA 扩展开放模型系列,推动代理式、物理和医疗 AI 下一阶段发展2026-03-17 1464
-
NVIDIA Jetson模型赋能AI在边缘端落地2026-03-16 898
-
利用NVIDIA Nemotron开放模型构建智能文档处理系统2026-02-25 874
-
NVIDIA 推出 Nemotron 3 系列开放模型2025-12-16 977
-
NVIDIA推动面向数字与物理AI的开源模型发展2025-12-13 1738
-
面向科学仿真的开放模型系列NVIDIA Apollo正式发布2025-11-25 74352
-
NVIDIA Nemotron Nano 2推理模型发布2025-08-27 2223
-
NVIDIA 推出开放推理 AI 模型系列,助力开发者和企业构建代理式 AI 平台2025-03-19 480
-
NVIDIA推出开放式Llama Nemotron系列模型2025-01-09 1855
-
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据2024-09-06 1608
全部0条评论

快来发表一下你的评论吧 !
