

新思科技全面驾驭AI芯片设计复杂性
描述
AI 芯片正推动着万物智能时代的到来:作为高度专用化的处理器和加速器,AI 芯片专为处理复杂算法与海量数据集而设计。但在当今快速变化、竞争激烈的市场中,要打造一款脱颖而出的 AI 芯片,需要具备哪些条件?答案早在芯片制造之前就已揭晓。
硅前规划势在必行
设计 AI 芯片面临着巨大的技术挑战。开发者必须在性能、能效、可扩展性和上市时间之间取得平衡,同时还要管控成本与风险。硅前规划阶段为整个开发流程绘制蓝图,并制定影响后续每一步骤的关键决策。
在硅前规划中,需明确系统需求、选定架构,并预判可能遇到的集成挑战。这不仅是一项技术工作,更是一项战略部署。前期投入的时间和资源能够避免后期出现代价高昂的失误,助力确保芯片符合市场与客户的预期。
了解 AI 工作任务
硅前规划的首要任务之一,是明确 AI 芯片将要处理的工作任务。工作任务各种各样,包括图像识别、大语言模型(LLM)、自动驾驶、数据分析等。每种应用场景对算力、内存带宽和连接性的平衡需求各不相同。
开发者会借助基准测试和代表性数据集,对目标工作任务进行详细的负载分析,从而有助于对性能需求进行精准建模,并及早识别瓶颈。例如,为深度神经网络训练设计的芯片,与为边缘设备推理优化的芯片,两者的需求存在显著差异。
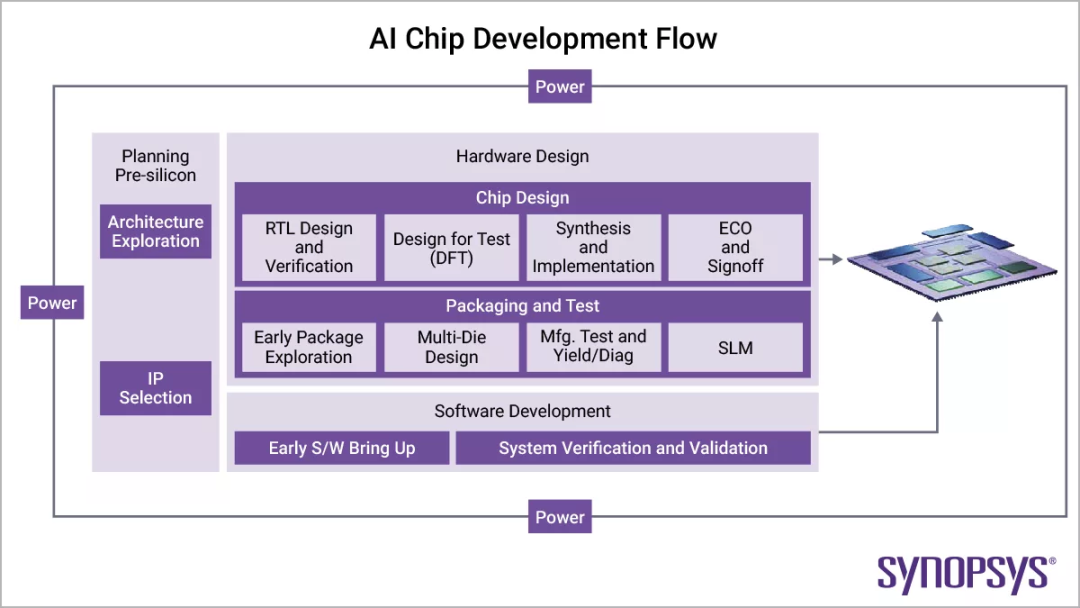
架构探索与设计选择
明确工作任务负载需求后,便进入架构探索阶段。工程团队需考量:是采用同构处理单元阵列,还是CPU、GPU 与定制加速器的异构组合。内存层级结构与互连架构的选择,对支持目标应用也起着关键作用。
借助新思科技 Platform Architect 等先进建模工具,可对不同架构进行仿真,并预测架构在真实场景下的表现。工程团队因而能够在系统架构、性能与能效之间做出基于数据的决策和权衡,最终节省设计周期后期的时间并降低风险。
低功耗:贯穿始终的优先级
在 AI 芯片设计中,优化能效已不再是事后考量,而是成为一项贯穿始终的关键要素。AI 工作任务负载正深刻重塑全球能源格局:据预测,全球数据中心的能耗到 2026 年将高达 1000 太瓦时,相当于一个国家的能源消耗量。这种计算需求的激增,给开发者带来巨大压力,要求设计出既能提供出众性能、又保持高能效的解决方案。
为应对这一挑战,半导体团队正越来越多地采用“左移”方法。通过从设计周期伊始就优先考虑功耗优化,开发者能够主动评估架构选择、建模功耗,并实施最小化能耗的策略。对能效的早期持续关注,使设计全过程中的决策更具影响力,有助于实现可持续发展目标、管控运营成本,打造出能满足下一代 AI 应用需求的芯片。
IP 选择与集成
现代 AI 芯片很少从零开始设计,而是采用将经过验证的知识产权(IP)模块(如处理器核心、内存控制器和连接接口)集成到设计中的方法。IP 的选择与集成是硅前规划中的一个关键步骤。
新思科技广泛多样的硅验证 IP 产品组合专为互操作性设计,并针对所有主流代工厂技术进行了优化,有助于加速集成与验证流程,同时最大限度降低风险。
AI 芯片设计的未来
随着 AI 不断演进,芯片设计的挑战也在持续升级。先进工艺节点、Multi-Die 架构及新型加速器正不断突破技术极限。硅前规划依然是驾驭此种复杂性、并最终交付创新解决方案的最有效途径。
投入资源开展稳健的硅前规划,是打造能推动下一波技术突破的 AI 芯片的关键所在。通过将深度工作任务负载分析、全面的架构探索、功耗优化及经过硅验证的 IP 相结合,在首片晶圆生产之前,就已为成功筑牢根基。
-
抑制嵌入式系统设计的复杂性解析2020-12-30 1485
-
嵌入式调试的复杂性分析2021-02-19 1166
-
如何用可重构射频前端简化LTE设计复杂性?2021-05-24 1904
-
新思科技发布业界首款全栈式AI驱动型EDA解决方案Synopsys.ai2023-04-03 1672
-
有效解决实时IoT环境监测的复杂性2016-07-14 827
-
应对芯片设计复杂性 EDA工具需要新典范2017-02-09 3303
-
基于构件回归测试的复杂性度量框架2018-01-19 978
-
PCB复杂性怎样来解决2019-08-16 2907
-
大数据分析学习的挑战:复杂性、不确定性及涌现性2022-11-17 3996
-
模型复杂性日益增加,AI优化的硬件随之出现2021-06-16 3331
-
插入排序算法的复杂性、性能、分析2022-04-08 4766
-
驾驭软件定义车辆的复杂性2022-07-14 1706
-
了解 AV 复杂性2022-07-15 2589
-
新思科技收购Ansys,引领芯片系统设计解决方案2024-01-17 1287
-
新思科技携手微软借助AI技术加速芯片设计2025-06-27 1332
全部0条评论

快来发表一下你的评论吧 !
