

语音识别技术的发展历程,语音识别是如何工作的?语音识别资料概述
电子说
描述
你一定不会怀疑自己电脑的麦克风正背着你偷偷摸摸做些什么,因为你已经很久没有用过它了。
但事实真的是这样吗?
难道谷歌真的在“监听”用户吗?
挨君想告诉你,这基本没 可 能。
谷歌浏览器的用户已经超过20亿了,要是监听每个用户每天说的话,这个数据量太过惊人。投入高昂的成本就为了实现广告精准投放,还冒着巨大的法律风险,这种事正常人是不会去做的。
对于视频中展现的“事实”,可能的操作是谷歌使用了一个语音关键词识别系统。
有商业价值的关键词总共就几百万个,为了简单,可以只做头部那些最赚钱的几十万个。这几十万个关键词也不需要先跑语音识别再跑文本匹配,拿原始的语音文件来搞一个中等深度的神经网络甚至线性特征模型就可以,速度也非常快。
所以大家不用担心语音识别正在侵犯你的隐私。相反,作为人类与机器最自然的交互形式(绝对不是打字),在未来,当你不想用手或者像残障人士难以用手的时候,语音识别将会是操作一切最方便的钥匙。
语音识别发展史
说到语音识别,大家熟悉的可能是最近十年里才出现的微信语音转文字,或者语音实时记录和翻译。但其实语音识别的历史比互联网还早,现代计算机诞生的那一刻,就已经埋下了语音识别的种子。
1946年,现代计算机诞生。它的诞生让人们意识到,原来计算机能完成这么多工作,而且做得比人还好;
(冯诺依曼和第一台现代计算机)
1950年,图灵在《思想》杂志发表了一篇题为《计算机器和智能》的论文,来探讨计算机是否可以具备智能;
在图灵思想的启发下,人们想着既然计算机这么能干,干嘛不把它设计得和人类一样能看能说能听呢,这不就能帮人类做更多事了嘛!(果然,懒才是科学发展的源动力啊)
于是,第一代语音识别系统诞生,被称为机器的听觉系统。
1952年,贝尔研究所研制了世界上第一个能识别10个英文数字发音的实验系统。也就是你说“yi”,计算机就知道这是“1”,能力跟婴儿差不多。
1960年,英国的Denes等人研制了第一个计算机语音识别系统。
但是因为识别量小,这些系统根本达不到实际应用的要求,包括后续的20年间,都是在走弯路,没有什么研究成果。
直到1970年,统计语言学的出现才使得语音识别重获新生。
统计语言学带来的重生
推动这个技术路线转变的关键人物是德里克·贾里尼克(Frederick Jelinek)和他领导的IBM华生实验室(T.J.Watson)。
统计语言学带来的结果是,让IBM当时的语音识别率从70%提升到90%,同时语音识别的规模从几百单词上升到几万单词,这样语音识别就有了从实验室走向实际应用的可能。
人类的语言是非常复杂的。不同于音频识别,语音识别的难点在于把一段音频不仅转换成对应的字,还要是一段逻辑清晰、语音明确的语句。
举个例子,我们对计算机念一句话,“周五一起吃饭吧”。计算机根据音频做出的识别可能结果是这样的:州午衣起痴范爸。
如果仅看读音和文字的一一对应,这个准确度可以说是很高了,因为如果念的口齿稍有不清更糟糕的结果可能是“邹五意起次换吧”。
但是无论哪种结果,在实际应用上都是不可行的,完全没法交流嘛。
那么统计语言学带来的变革是什么呢?
我们知道,虽然人类的语言很复杂,但仍有一定规律可循,无论是“州午衣起痴范爸”,还是“邹五意起次换吧”都不是一个正常人会说的话。统计语言学的作用就是找出人类说话的规律,这样就可以大大减少了语言识别产生的误差。这其中一个非常关键的概念就是语素。
语素是语言中最小的音义结合体,一个语言单位必须同时满足三个条件——“最小、有音、有义”才能被称作语素。语素又可以分成三类:
单音节语素:构词由一个字才有意思的词组成
双音节语素:构词由两个字才有意思的词组成
多音节语素:构词由两个字以上才有意思的词组成
啥意思呢?举个例子。
你、我、他,这三个字都是单音节语素,因为每个字都能自成一个含义。
你可能要说了,那不是废话吗,还有什么字是没有含义的吗?
当然有!比如挨君最喜欢吃的“馄饨”。
馄饨就是一个双音节语素。单独的馄或者饨都不具备任何含义,只有组合在一起的时候才有真正的意义。类似的还有“琵琶”、“霹雳”等等。另外比如“沙发”这类词,一旦拆分开其含义就完全脱离原来语素的,也被称为双音节语素。
最后一种情况就是多音节语素,主要是专有名词还有拟声词,比如喜马拉雅,动次打次。
我们再看回刚才的例子,当机器知道语素之后,即便同音它也不会把“周五”识别成“州午”,因为后者没有任何意义,也不会把“吃饭”识别成“痴范”。
又有人要说了,现在很多网络用语把吃饭说成次饭,我也能看懂啊。
如果说“次饭”你能理解那当然普大喜奔啦,要是“邹五意起次换吧”你都能理解的话,那对于语音识别团队来说可真是天大的喜讯了。然而真实情况是,视人视场景不同,识别准确率永远是语音识别第一位的追求。
以上,根据语素等人类语言规律挑选同音字的工作,在语音识别中我们称为语言模型。
语言模型的好基友
语音识别中还有一个模型,就是声学模型。
声学模型和语言模型是语音识别里的一对好基友。声学模型负责挑选出与音频匹配的所有字,语言模型负责从所有同音字里挑出符合原句意思的字。
声学模型的原理说起来跟做牛肉火锅有点像。
我们拿到一段语音,首先要把它切成若干小段,这个过程叫做分帧。
跟片好的牛肉会被分成匙仁、吊龙、匙柄一样,片好的帧会根据声学特征被计算机算法识别为一个个【状态】,多个状态又可以组合成音素。
音素是语音中的最小的单位,比如哦(o),只有一个音素;我(wo)则有两个音素,w、o;吼(hou),则有三个音素,h、o、u。
有了音素就可以对应找到匹配的字。
所以你可以这么理解,【状态】就像生牛肉,还不是人类可以“食用”的模样,需要用计算机算法来“涮一涮”成为音素才能成为一个【字】。
PS:如果你对【状态】这个概念还不太理解,那也没关系,因为近几年出现了一个叫CTC的新技术,建模单元放大到了音节或音素的单位,直接跳过了【状态】这个概念,所以这个知识点以后都不会考了。
刚才提到语言模型为语音识别带来的重生,并不是说在此之前声学模型就已经非常成熟了,相反,语音识别重生不久(到20世纪90年代)再次转凉就是因为声学模型太弱,缺少足够的数据和算法。这一状况直到互联网的出现并且带来了极其丰富的大数据后,才稍微得以改善。
可以这么说,语音识别的童年,是灰暗坎坷的。
语音识别是如何工作的
说完语音识别的两个模型,现在我们可以大致梳理下语音识别的基本步骤,如下图:
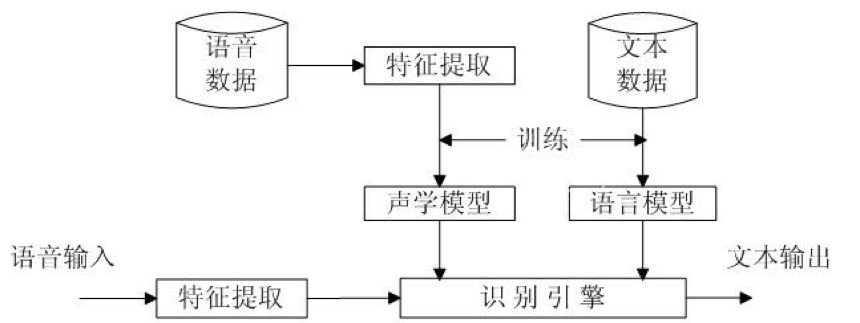
你通过微信发送了一段语音,对方因为在开会无法听,于是使用了语音转文字的功能。语音识别系统先把这段语音分帧,然后提取每一帧的特征形成【状态】,几个状态(通常为3个)又会组合成一个音素,音素又构成了诸多同音字,接着语言模型从诸多同音字中挑选出可以使语义完整的字,最后一个个呈现在你面前。
虽然过程看着挺简单的,但事实上,受各种语音语调、方言、说话环境、说话方式等等的影响,语音识别要提高准确率非常非常非常…非 常 难。得亏现在有了大数据和深度学习,这两个模型才得到了好好的训练,包括现在很多语音识别厂商都表示已经可以实现97%的识别准确率。
这里插播一段广告,
网易人工智能对语音识别技术的研究开始于2014年,目前通过网易AI平台已服务于网易游戏、有道词典等产品。网易AI平台语音识别技术的优势有:领先的中英文语音识别转写技术,中文转写准确率可达97%以上;提供基于垂直行业语音模型进行深度优化训练,在游戏行业的语音识别准确性保持业界顶尖水平;提供标准规范的SDK和API接口,接入迅速,使用便捷。
说了这么多,语音识别算是人工智能领域比较成熟的技术,但对于人类的远大愿景而言,这才只是起步,就像小婴儿现在只能听,接下来还要会说、会做、会想。不过有了深度学习之后,这一切现在看来似乎有了触达的可能。
-
语音识别技术的应用与发展2024-11-26 2381
-
情感语音识别:技术发展与挑战2023-11-28 1188
-
离线语音识别及控制是怎样的技术?2023-11-24 2030
-
离线语音识别和控制的工作原理及应用2023-11-07 1188
-
语音识别技术:现状、挑战与未来发展2023-10-12 4466
-
语音识别技术的进步与挑战2023-09-22 1665
-
浅析语音识别技术的发展历程2022-02-07 5906
-
【语音识别】你知道什么是离线语音识别和在线语音识别吗?2021-04-01 6997
-
语音识别的技术历程2019-08-22 5116
-
基于labview的语音识别2019-03-10 12749
-
语音识别是什么2018-11-18 10916
-
国内语音识别技术上市公司汇总_语音识别技术现状_语音识别原理及应用2017-12-13 10584
-
语音识别技术的应用及发展2014-12-16 2642
-
语音识别技术,语音识别技术是什么意思2010-03-06 3133
全部0条评论

快来发表一下你的评论吧 !
