

涂鸦Omni AI Foundation V2.6发布:低代码+多模态,重塑AI硬件创新体验
描述
涂鸦智能AI开发者平台始终致力于打造行业内最具竞争力的AI硬件创新中间件平台。我们不断强化平台能力、提升开放水平,通过更安全、更可靠、更可规模化的技术体系,持续助力客户实现自主创新,加速下一代AI硬件产品的落地。
今天,我们非常高兴地宣布:面向多模态AI硬件的基座平台Omni AI Foundation正式发布V2.6版本。本次升级不仅显著提升了端到端多模态交互体验,还全面开放了基于自研架构Dynamic Orchestration Agent System(DOS)的工作流编排引擎,为全球开发者提供更强大、更灵活、更高效的AI硬件构建能力。
核心亮点一睹为快:
端到端交互平均时延1.3秒,全球网络和实时算力稳定性双重加码;
开放编排引擎,赋能开发者低代码构建复杂AI应用,有效降低开发成本;
自然语音与意图分类等核心算法升级,灵活适配不同场景的多模态交互需求;
正式上线OmniMem个体记忆系统,提升AI设备交互一致性与情感体验。
关于Omni AI Foundation:
Omni AI Foundation是涂鸦智能倾力打造的多模态AI与实时音视频基座平台。它整合了涂鸦在实时音视频(RTC)、AI Agent运行环境、多Agent编排架构及全球部署方面的核心能力,为企业和开发者提供从设备接入、多模态交互到业务流程编排的全生命周期AI解决方案。
01
端到端时延与全球稳定性再上新台阶
我们持续加强全球化基础设施投入和技术布局,截至当前已在全球部署7个数据中心、数10个主流国家实时媒体加速网络、数千个主流城市边缘加速节点。基于Tuya Real-Time Communication(T-RTC) 加速网络,为全球开发者提供全球一致的端到端实时交互体验。
● 全球领先的响应速度:在全球范围内,包含记忆、知识库以及工具调用的复杂场景下,端到端交互平均时延已稳定在1.3秒以内,显著优于行业平均水平。
(注:以上数据基于800ms VAD时延测得,整体体验优于行业300-500ms VAD时间。)
● 金融级服务可靠性:通过动态负载均衡技术,支持全球主流大模型就近加速接入和实时(公共/专享)算力调度,毫秒级容灾降级切换,服务稳定性高达99.95%。
● 全球网络优化:Omni AI Foundation协议全面支持TCP、UDP及WebSocket协议,并针对不同业务场景实现了拥塞控制算法的自适应匹配,确保了在全球任何角落都能获得稳定、低延迟的连接体验。
(注:WebSocket面向浏览器侧开放、UDP已释放APP SDK集成,嵌入式SDK后续释放。)
02
更开放、更灵活,赋能开发者低代码构建复杂AI应用
本次升级的核心亮点在于聚焦技术架构的全面升级,着力解决开发者在AI硬件创新中普遍面临的多模态能力集成复杂、自主创新受限、开发效率不足等痛点。主要升级包括:
▍多Agent编排引擎:可视化协同、最短路径、多路并行
Omni AI Foundation现已全面支持可视化的多Agent协同流程。开发者可通过拖拽式操作,快速搭建「统一输入→意图理解与分类→多Agent并行处理→统一输出」的复杂业务链路。新架构具备最短路径决策与并行处理能力,以平衡开发者既要实现更复杂的差异能力又要保持实时端到端响应交互。同时在能力扩展上允许开发者在不同Agent中灵活启用或关闭MCP工具,以更简化的提示词来降低模型幻觉,提升响应时间。
▍更简化的MCP集成:端云能力统一、视觉端到端快50%
平台全面重构了设备侧MCP集成方案。在支持标准MCP协议的基础上,将AI硬件常用能力(如实时图像抓取、图像识别、传感器数据采集、设备控制等),统一抽象为标准化云端服务,使AI Agent可以在统一、安全、可控的方式下调用端侧能力,显著降低了端侧开发成本,同时实现了更快的端到端多模态响应,视觉理解链路整体性能提升约50%。
(注:端侧MCP集成需基于wukong V3.13.0以上版本使用。)
▍更加丰富的平台协议开放,支持拓展更多应用场景
为满足开发者更为丰富的应用场景,除支持Tuya Wukong AI、TuyaOpen、Tuya APP SDK外,新增开放WebSocket以支持PC/浏览器等终端接入,后续将开放更原子的Foundation SDK,以支持客户在更多开放系统中使用。
03
核心算法模型持续升级,全面释放多模态交互潜能
为更好适配不同芯片平台、硬件形态及应用场景中的自然语音与多模态交互需求,我们持续迭代核心算法模型,在确保算法可靠性与一致性的前提下,为开发者提供更加灵活、开放且可自主选择的模型能力组合。
▍高精度VAD模型:在“流畅响应”与“误判控制”之间取得最佳平衡
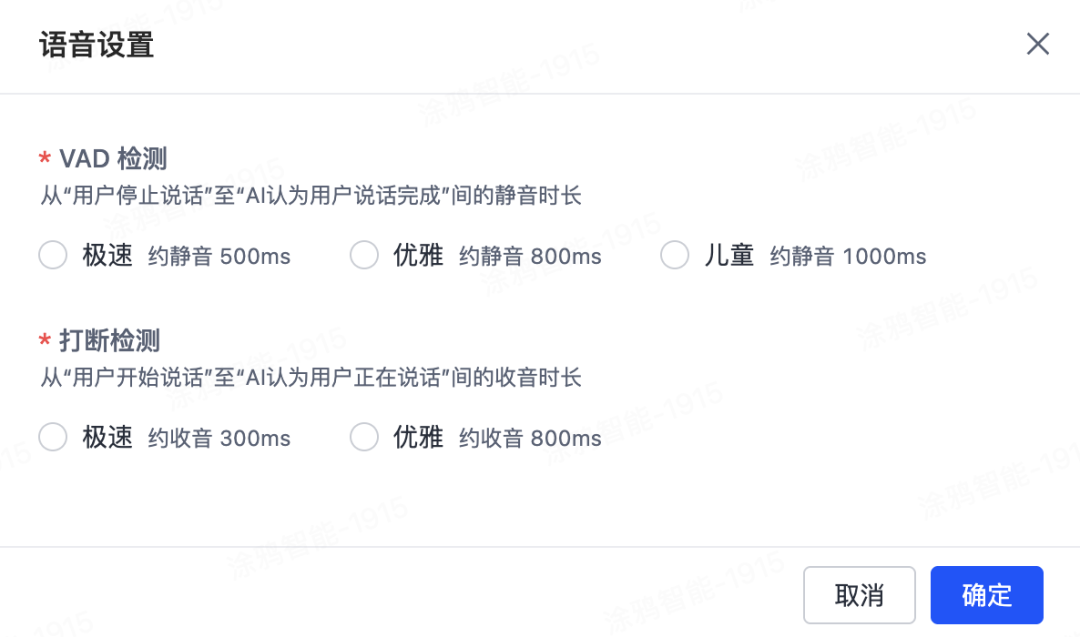
在语音活动检测(VAD)落地中,开发者往往面临两难:一方面,追求毫秒级响应速度,极易将环境噪声误判为有效语音,导致频繁中断;另一方面,过度强调准确率又会牺牲交互即时性,造成延迟和不自然体验。涂鸦自研的高精度VAD模型基于海量真实场景数据进行深度优化,实现了低至500ms静音检测和300ms的极速打断能力,为用户带来更自然流畅的对话体验。
“建议开发者在涂鸦AI开发者平台将打断检测设为极速300ms,VAD检测设为优雅800ms——即便VAD为800ms,全球端到端平均时延仍可控制在1.3s,有效保证用户体验。”
▍领域意图分类模型:降低意图幻觉,加速决策响应
当开发者为AI产品拓展能力时,大模型常常会出现意图幻觉增多、响应链路变长等问题。针对这一痛点,涂鸦基于多年在AI硬件领域的场景经验与生态数据,推出自训练的领域意图分类模型。该模型基于涂鸦对AI硬件的数据积累和市场洞察持续迭代,开发者只需在工作流中选择,即可为AI产品实时添加能力扩展。
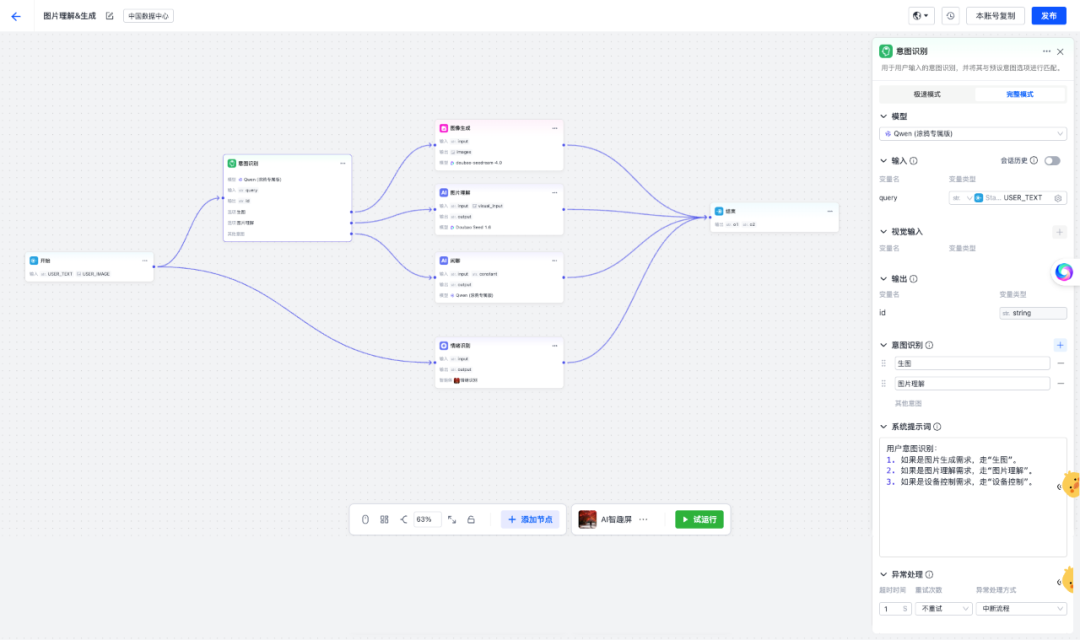
目前,涂鸦意图分类模型已全面覆盖涂鸦官方技能,后续将逐步开放对第三方MCP工具与客户自定义技能的分类与召回支持,为开发者提供更高鲁棒性的技能拓展。
▍突破全球多语言技术壁垒,支撑客户业务出海
在全球市场部署AI应用,多语言支持是一大核心技术壁垒。不同语言的语法结构、语调、口音差异巨大,训练一个在所有语言上都表现优异的统一模型极具挑战。
涂鸦的意图分类与语音识别(ASR)模型,已针对全球主要市场(如英语、西班牙语、日语及东南亚多语种)进行专项优化和数据增强,确保不同语言环境下的高识别率和意图理解准确性。同时,我们也为开发者在不同地区挑选最为优秀的合作伙伴,以保障开发者AI产品在当地可获得行业最佳的准确率和响应时间,为客户的全球化业务提供坚实可靠的技术支撑。
(注:以下测试均基于开源音频测试集(CommonVoice)测得。)
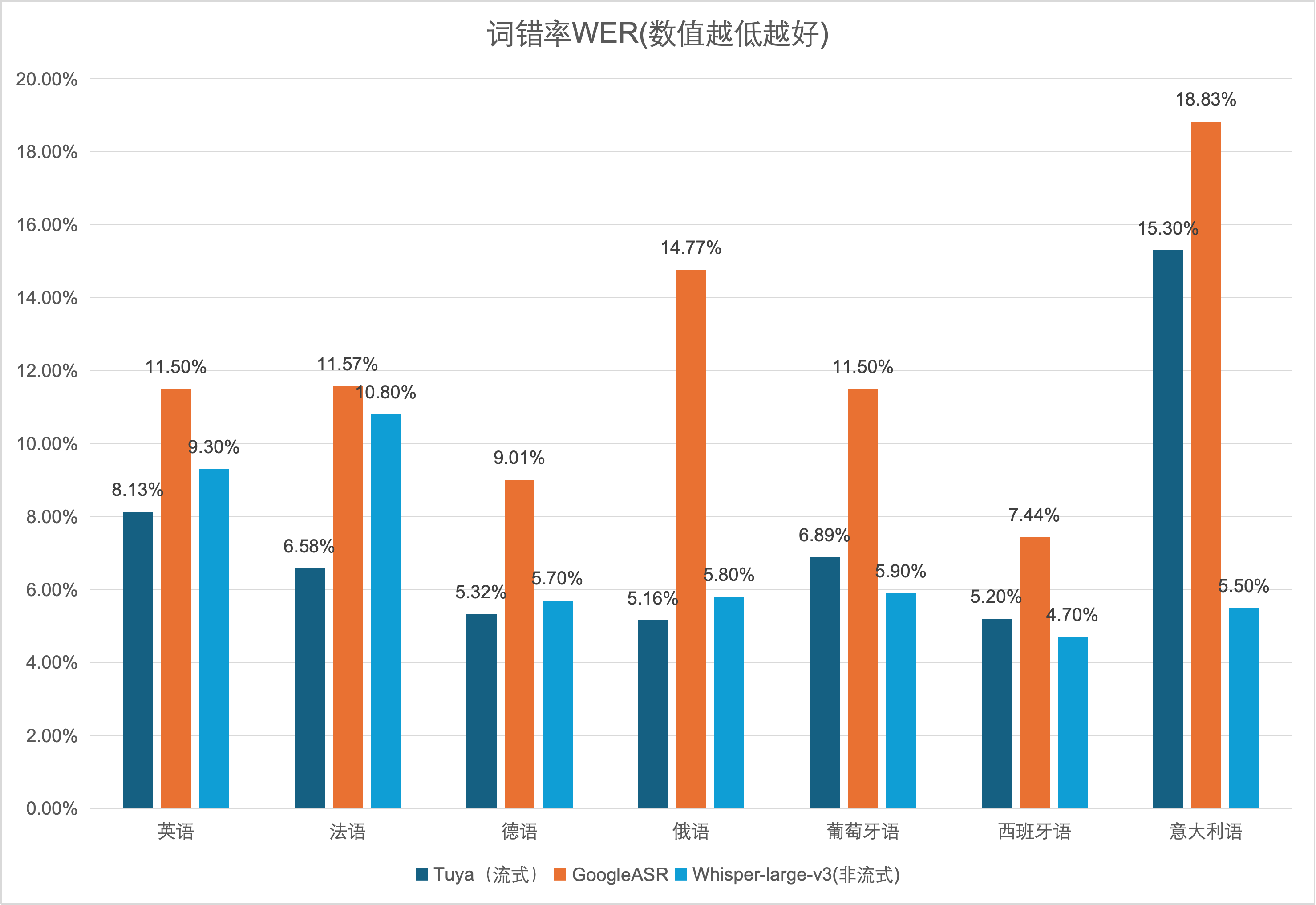
(注:Whisper-large-v3为离线模型无法在对话式语音交互场景使用,但离线模型相比流式模型拥有更低的WER,借助Whisper-large-v3的参考数据将更好帮助我们验证本地区ASR准确率。)
04
OmniMem个体记忆正式商用,重构AI记忆体验
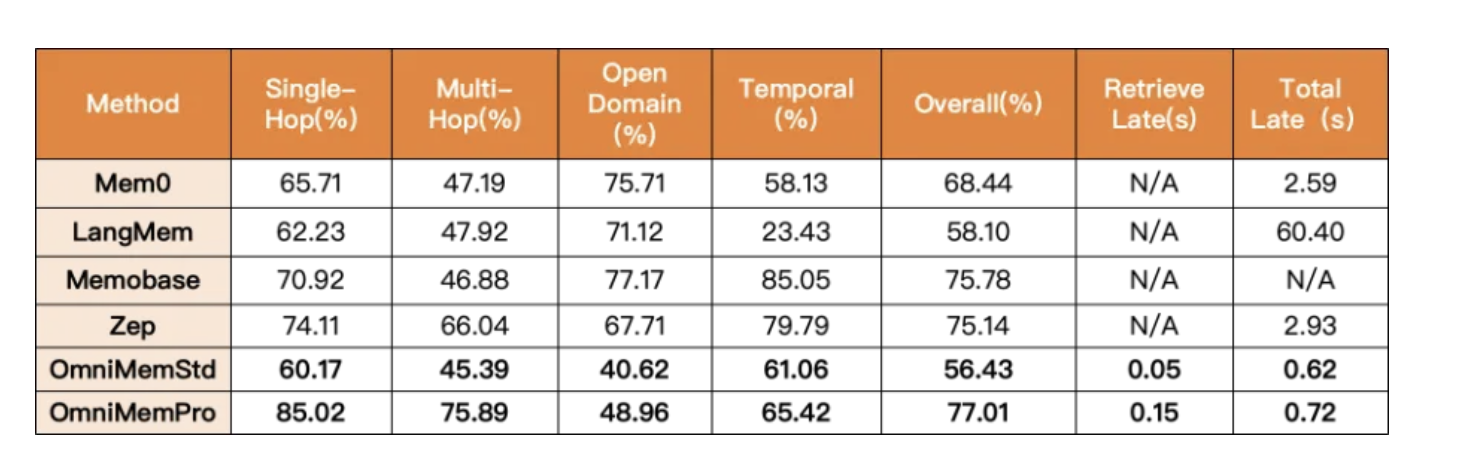
OmniMem通过针对AI记忆领域的时间处理、信息干扰、记忆割裂和动态更新等多个技术痛点进行攻坚,凭借底层架构优化与算法创新,实现了低延迟+高精度的有效平衡。平台只需一步配置,即可快速解锁AI记忆的核心能力。
OmniMem以开源测试集的领先得分、低延迟表现、多维度痛点解决方案与低门槛落地体验,成为“更懂用户、更稳性能、更具价值”的AI记忆选择。后续,我们将带来多模态记忆融合、跨设备迁移能力优化、记忆拟人化体验升级等新能力,持续完善能力边界,让智能记忆的价值持续生长。
戳这里,详细了解OmniMem的核心技术与优势。
-
NVIDIA发布Nemotron 3 Nano Omni开放式多模态模型2026-05-08 671
-
何同学“AI寻牛”硬件激发创意,2025 SparkS全球AI硬件创新大赛启动2025-11-19 1455
-
代码如何重塑硬件设计,AI如何加速创新?2025-09-06 1067
-
华为AI WAN SPN打造行业数智化新体验2025-05-07 1428
-
涂鸦WuKong AI 2.0开发框架发布!情绪感知+多模态交互,重新定义AI玩具新体验2025-03-27 2019
-
移远通信智能模组全面接入多模态AI大模型,重塑智能交互新体验2025-03-20 1008
-
FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......2025-03-03 7721
-
Tata Communications发布Kaleyra AI:重塑客户互动新体验2024-12-23 1326
-
Build 2024发布多项Azure AI Speech全新多模态功能2024-05-28 1462
-
谷歌发布多模态AI新品,加剧AI巨头竞争2024-05-16 1036
-
李未可科技正式推出WAKE-AI多模态AI大模型2024-04-18 1222
-
RZ/V2L DRP-AI支持包版本.7.41发布说明2024-02-01 394
-
Flash loader demonstrator V2.6 无法下载程序2019-03-27 4088
-
丘钛科技打造AI时代的智能新体验2018-12-14 6129
全部0条评论

快来发表一下你的评论吧 !
