

如何在NVIDIA Jetson AGX Thor上部署1200亿参数大模型
描述
上一期介绍了如何在 NVIDIA Jetson AGX Thor 上使用 Docker 部署 vLLM 推理服务,以及使用 Chatbox 作为前端调用 vLLM 运行的模型(上期文章链接)。本期我们将尝试能否在 Jetson AGX Thor 上部署并成功运行高达 1,200 亿参数量的 gpt-oss-120b 大模型。
gpt-oss-120b 是由 OpenAI 于今年发布的开放权重 AI 模型,采用了广受欢迎的混合专家模型(MoE)架构和 SwigGLU 激活函数。其注意力层使用 RoPE 技术,上下文规模为 128k,交替使用完整上下文和长度为 128 个 Token 的滑动窗口。模型的精度为 FP4,可运行在 NVIDIA Blackwell 架构 GPU 上。
本期具体内容包括:
vLLM 镜像下载及容器构建
模型下载与运行
使用 Chatbox 作为前端调用 gpt-oss-120b
Jetson AGX Thor 模型运行资源占用及性能
一、vLLM 镜像下载及容器构建
参考上期教程,拉取 vLLM 镜像并构建容器。
1. 在命令行运行 docker pull nvcr.io/nvidia/vllm:25.10-py3 下载容器。

2. 下载完成后,运行容器,创建启动命令。
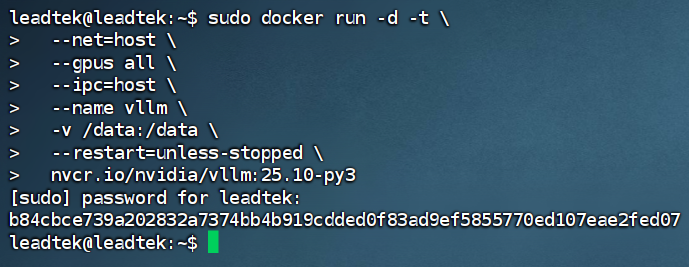
3. 容器创建成功后,使用 docker exec -it vllm /bin/bash 命令进入此容器。

二、模型下载与运行
1. 在线下载模型并运行
1.1 登录 Hugging Face,下载 gpt-oss-120b 模型。
容器内执行 huggingface-cli login,输入 Hugging Face 的token,出现“Login successful”即表示登录成功。
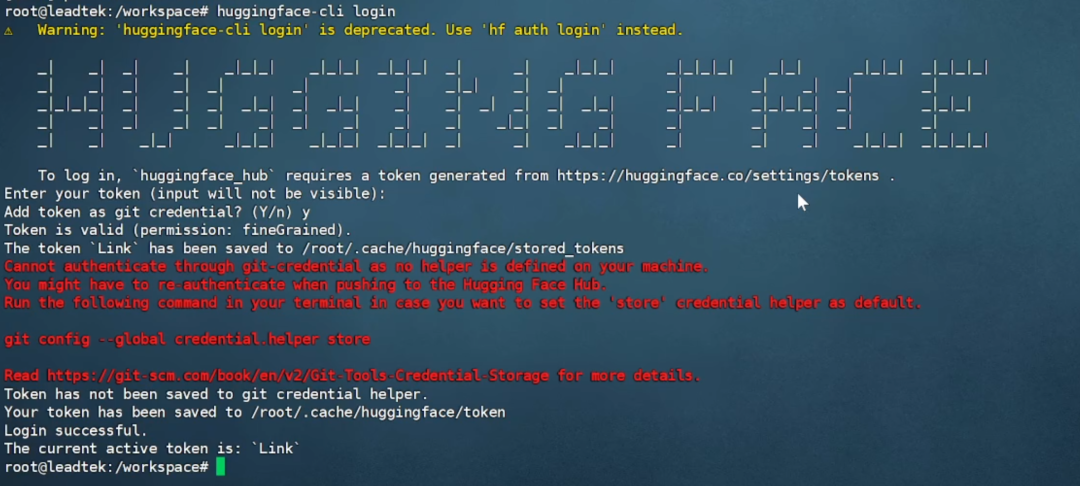
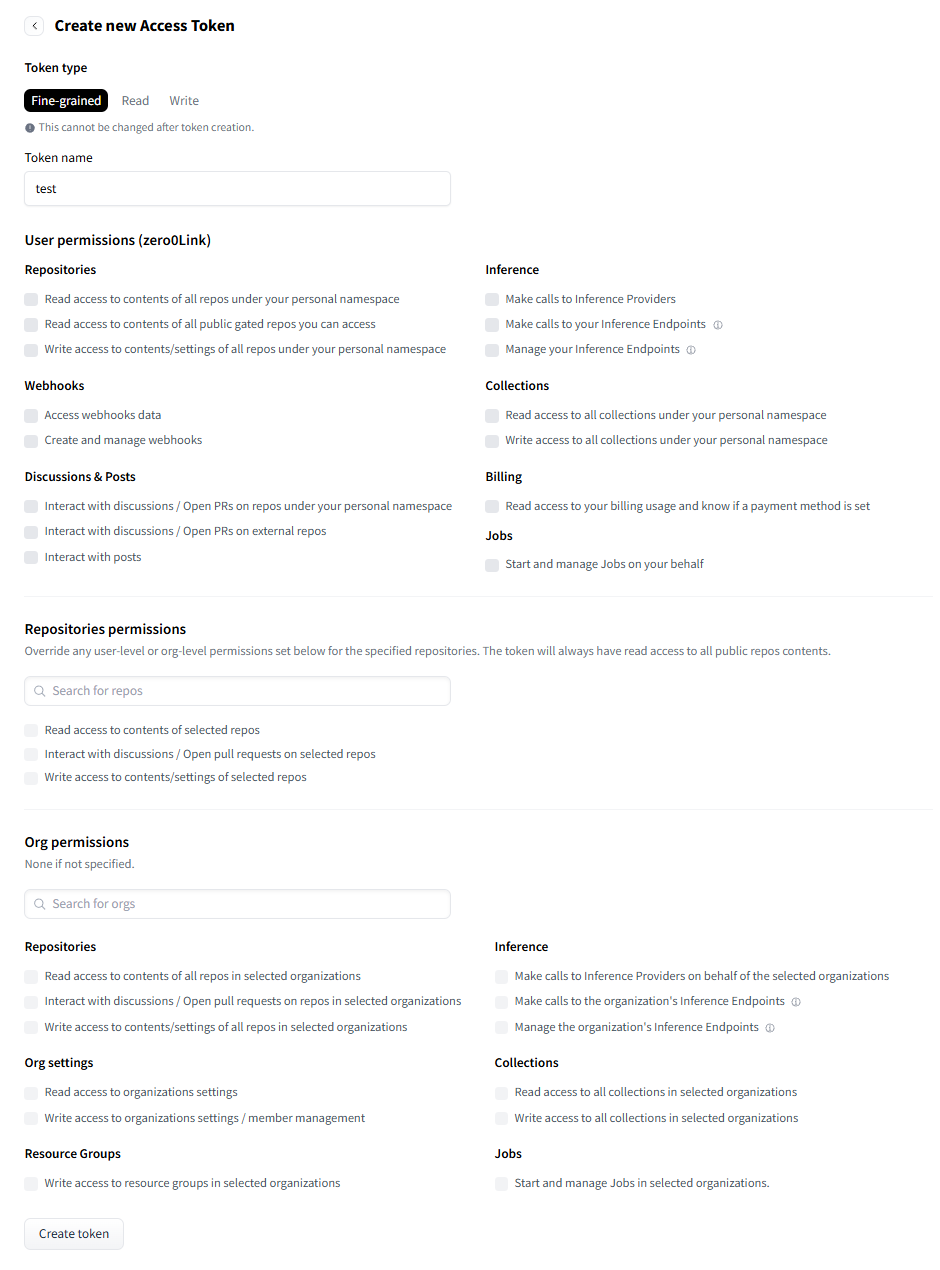
注:token 获取方式为注册并登录 huggingface.co,点击右上角用户头像 -Access Tokens,然后在新页面点击 Create new token,输入 token name,最后在最下方点击 Create token,复制并保存即可。
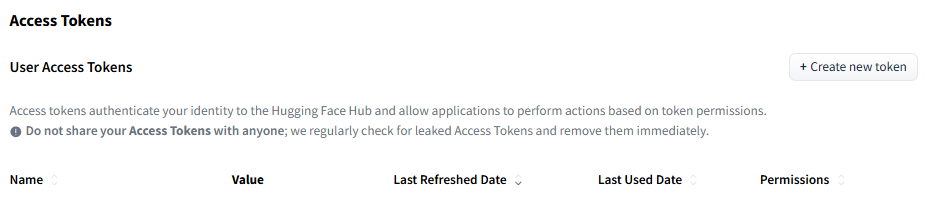
上下滑动查看图片
1.2 容器内运行 vllm serve openai/gpt-oss-120b,从 Hugging Face 上在线下载模型并开始运行。
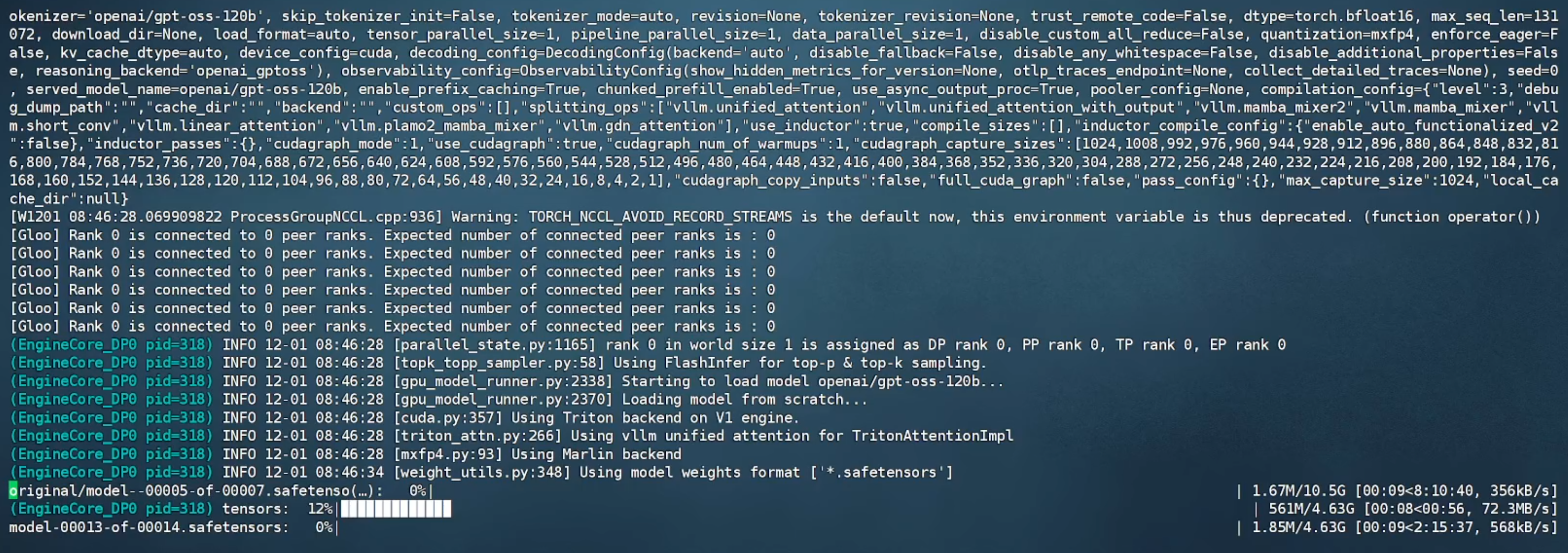
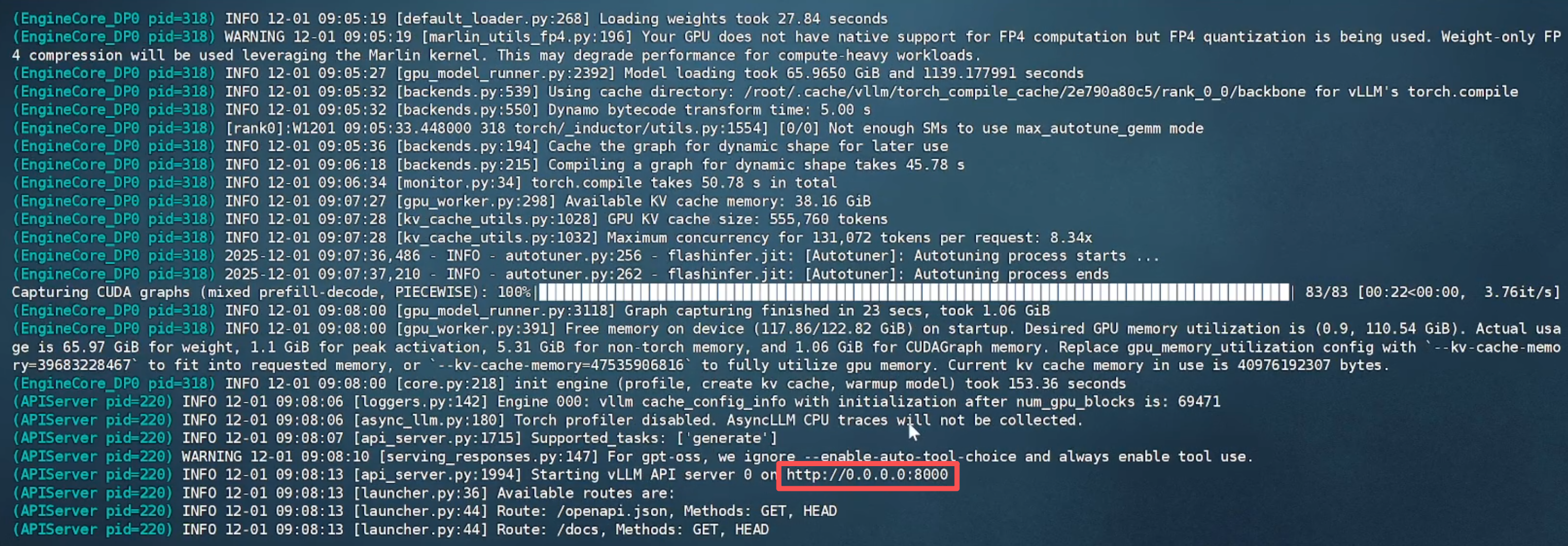
1.3 等待模型文件下载完成后(需科学上网),出现 API 端口号即可进行调用。
2. 本地模型运行
上述方法会将模型文件下载至容器的默认目录,再次运行时将直接调用已下载的文件。为避免容器删除导致文件丢失,建议将模型文件复制到本地映射的目录(如 /data)中进行保存。
以在当前路径举例,命令行执行以下代码,即可保存到本地指定目录:
cp -r models--openai--gpt-oss-120b /data

我们将本地模型文件命名为:local/gpt-oss-120b,容器内命令行执行以下命令,即可正常运行本地模型:
vllm serve /data/models--openai--gpt-oss-120b/snapshots/b5c939de8f754692c1647ca79f bf85e8c1e70f8a --served-model-name "local/gpt-oss-120b"
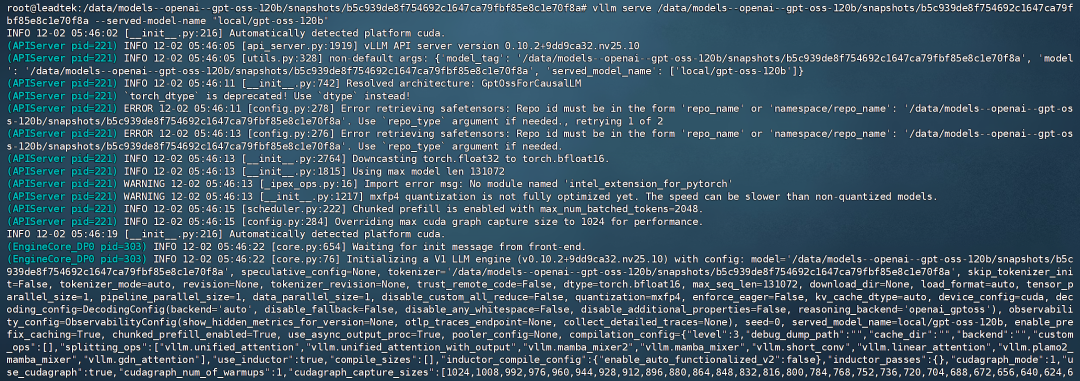
模型运行成功:
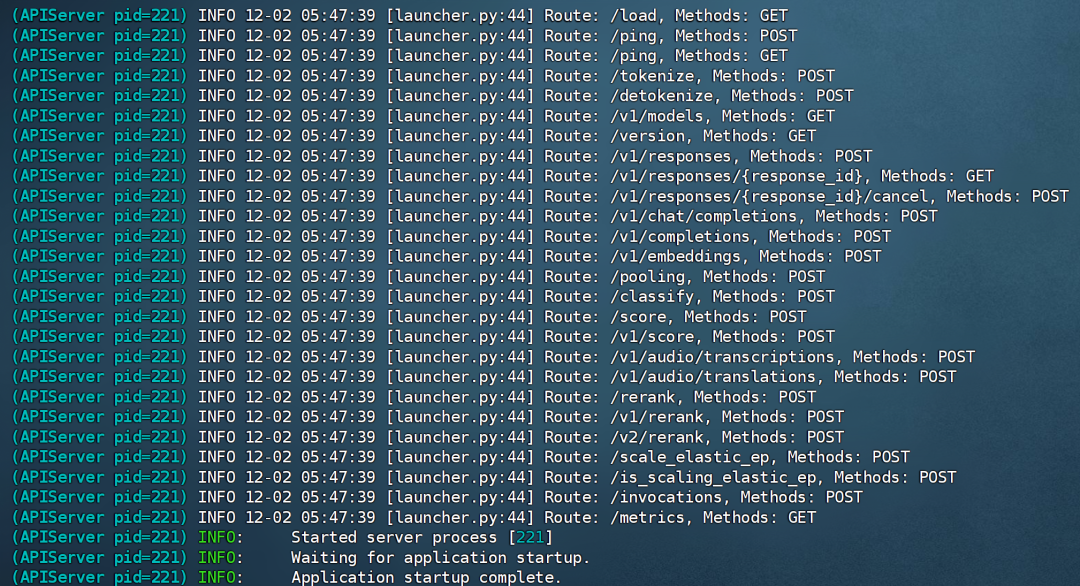
三、使用 Chatbox 作为前端调用 gpt-oss-120b
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。在这里,可以选择 Chatbox 作为前端调用 vLLM 运行的 gpt-oss-120b 模型,用于本地或在线与 AI 进行对话。
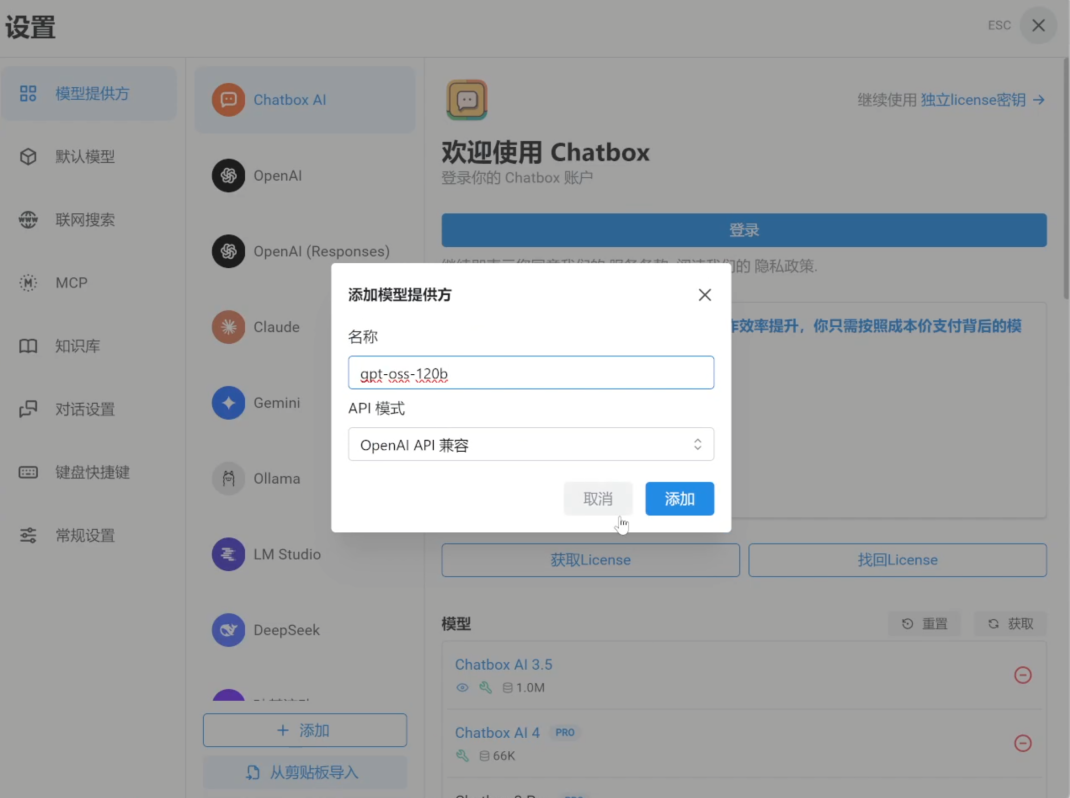
1. 参考上期教程,局域网内下载安装 Chatbox Windows 版本,点击“设置提供方” — “添加”,输入模型名称,再次点击“添加”。

上下滑动查看图片
2. API 主机可输入 Jetson AGX Thor 主机 IP 以及 vLLM 服务端口号。
(例:http://192.168.23.107:8000)
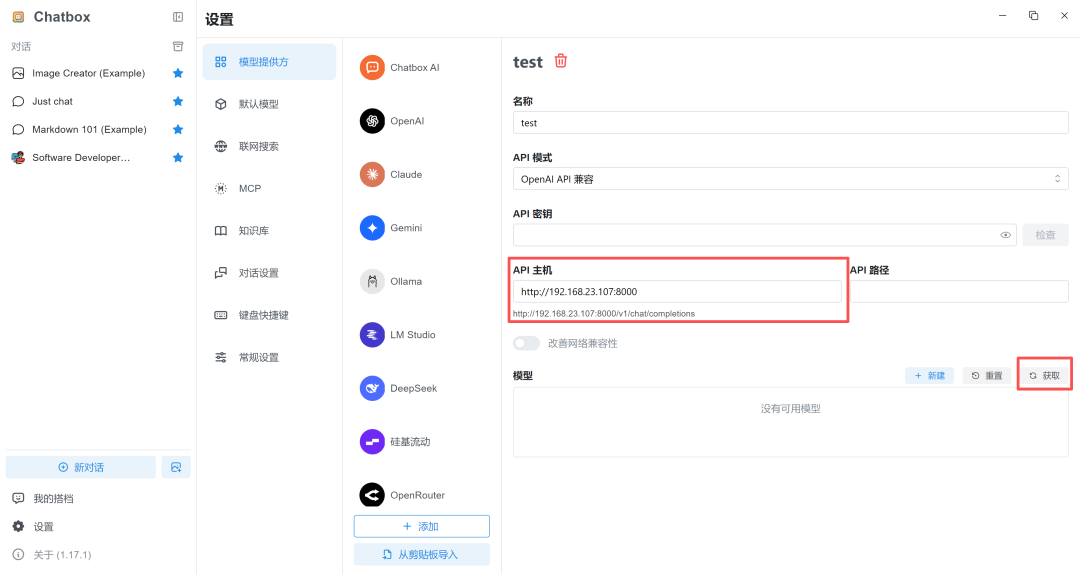
3. 选择 vLLM 运行的模型,点击“+”。
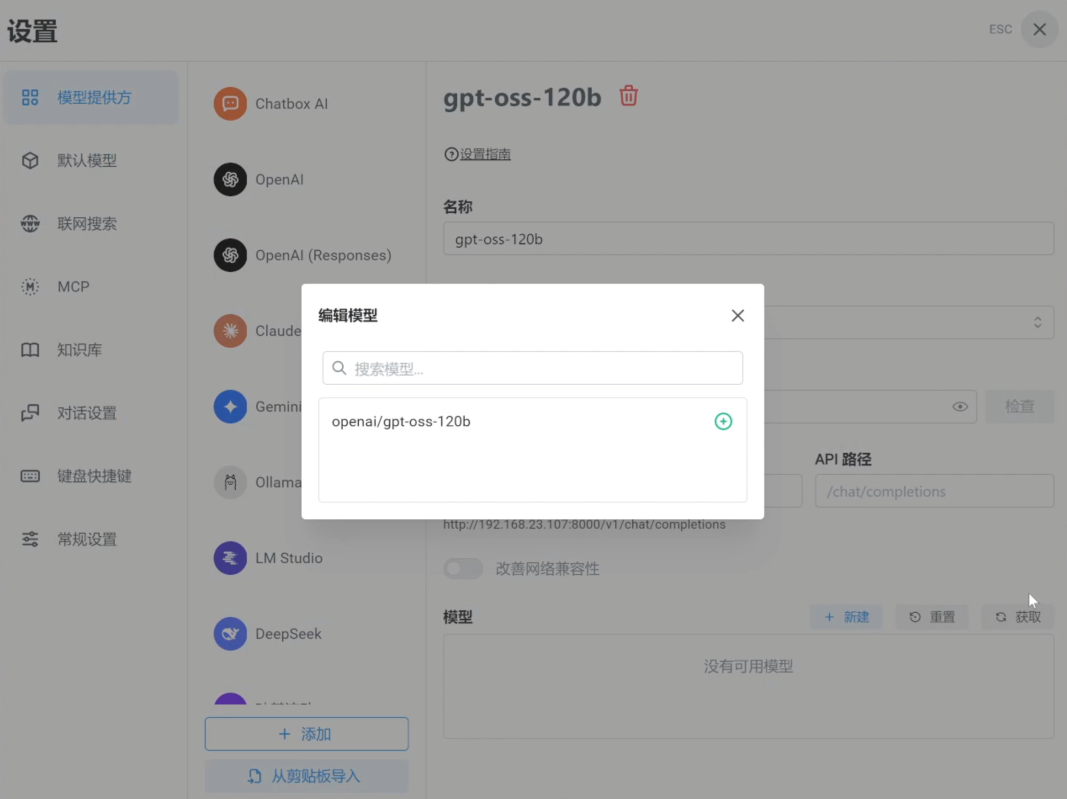
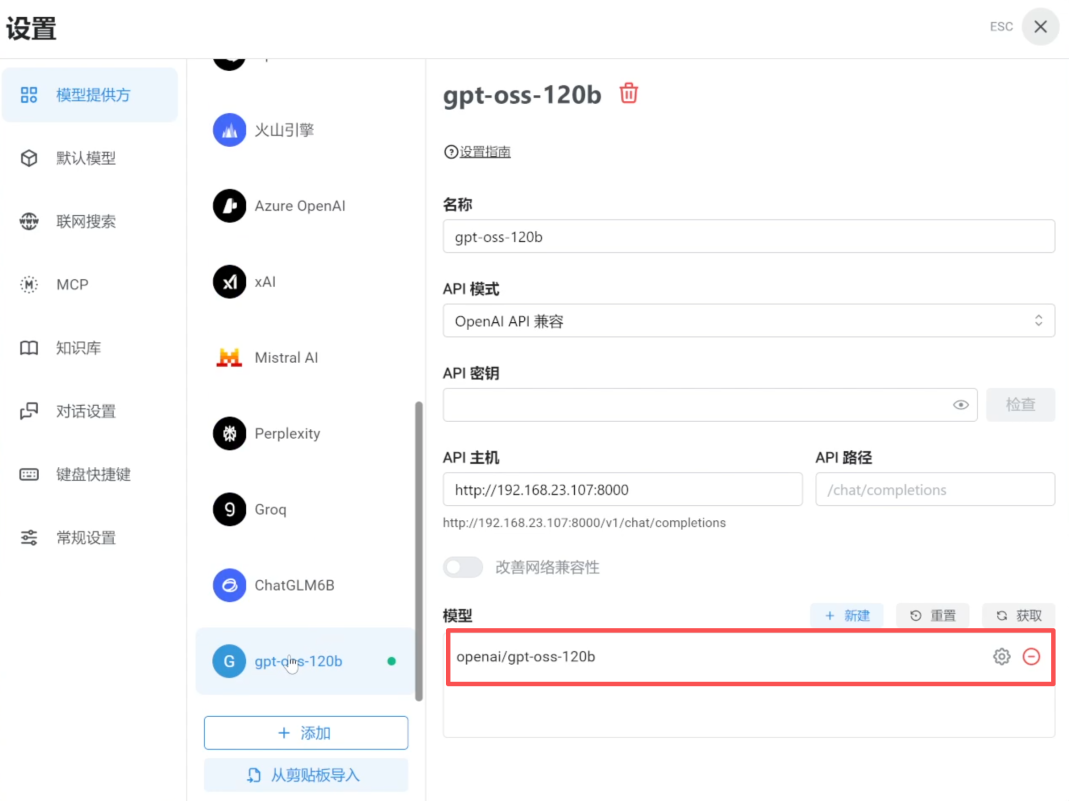
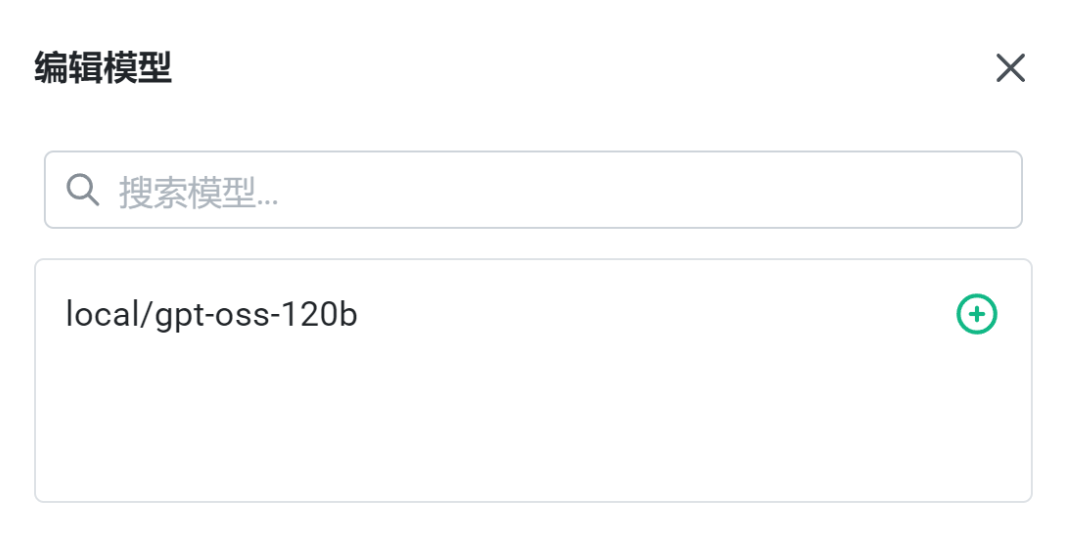
注:这里同样可以添加前述步骤已保存或通过其他方式获取的模型文件。
4. 点击“新对话”,右下角选择该模型即可开启对话。
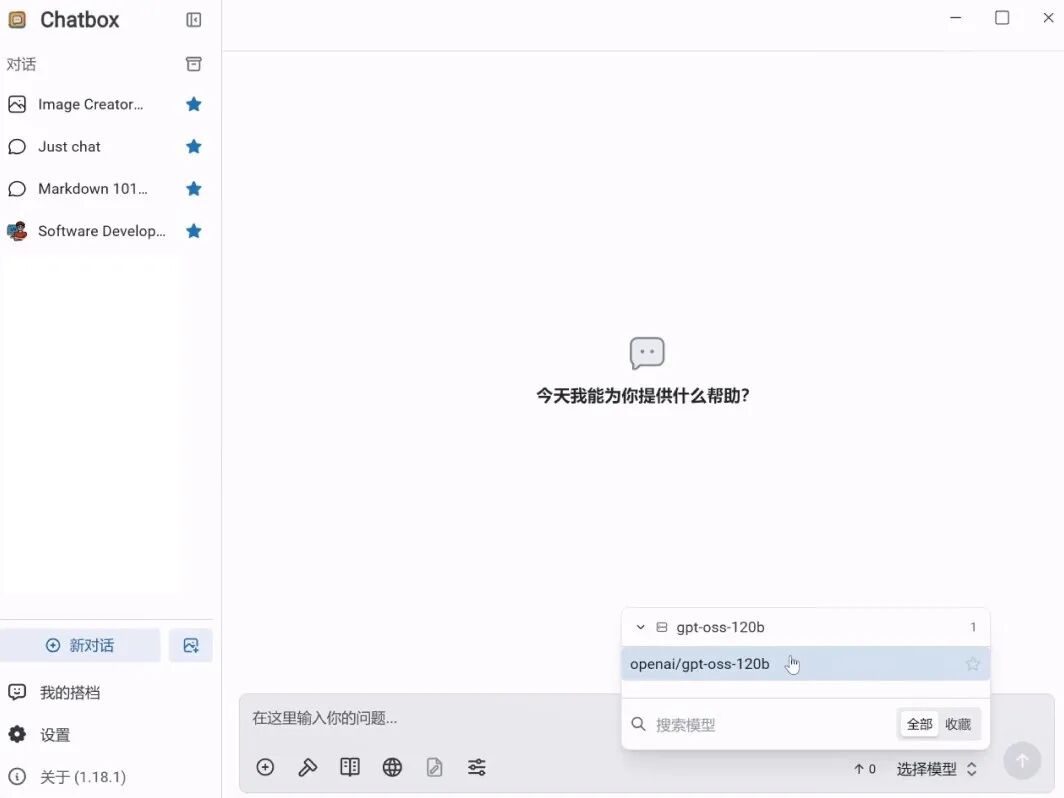
5. 运行示例
我们在此示例提问一个问题,运行结果如下:
以上视频已作 3 倍加速处理
四、Jetson AGX Thor 模型运行资源占用及性能
接下来分析运行 gpt-oss-120b 时的资源使用情况。
命令行执行 jtop 命令,可见加载完模型后,内存占用约为 115G。

当模型在进行推理任务时,部分 CPU 核心持续满载,同时 GPU 使用率也维持在 95% 左右的高位。
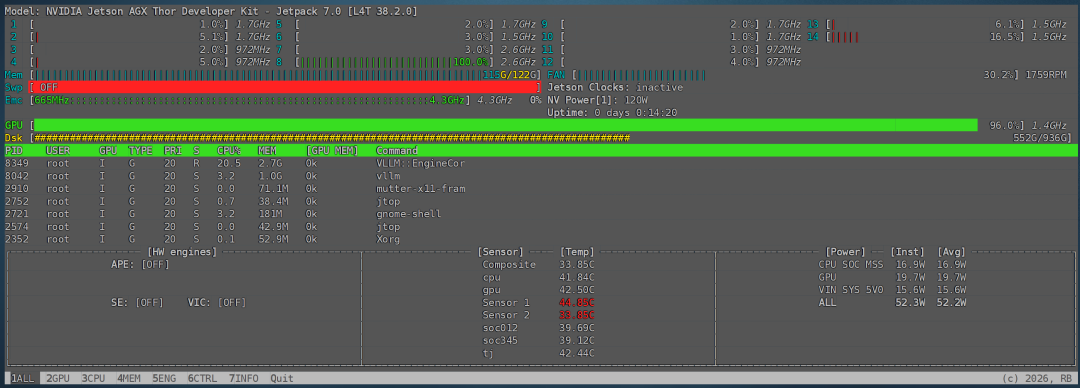
我们使用 AI 生成的脚本,测试了输入 128 tokens、输出 128 tokens 且并发数为 1 时的吞吐量。
容器内执行:
# 创建测试脚本
cat > /tmp/test_performance.py << 'EOF'
import time
import requests
import json
import statistics
# 配置
API_URL = "http://localhost:8000/v1"
MODEL_NAME = "local/gpt-oss-120b"
NUM_REQUESTS = 30
# 生成大约128个token的prompt(英文)
prompt_words = []
# 添加一些常见单词来达到约128个token
for i in range(32):
prompt_words.append(f"Sentence {i+1}: Artificial intelligence is transforming various industries through automation and data analysis.")
prompt = " ".join(prompt_words)
print(f"Prompt length (words): {len(prompt.split())}")
results = []
total_tokens = 0
print(f"Starting benchmark with {NUM_REQUESTS} requests...")
print(f"Model: {MODEL_NAME}")
print(f"Input tokens: ~128, Output tokens: 128")
print("-" * 60)
for i in range(NUM_REQUESTS):
payload = {
"model": MODEL_NAME,
"prompt": prompt,
"max_tokens": 128,
"temperature": 0.1,
"top_p": 0.9
}
try:
start_time = time.time()
response = requests.post(
f"{API_URL}/completions",
json=payload,
timeout=300
)
end_time = time.time()
if response.status_code == 200:
result = response.json()
latency = end_time - start_time
results.append(latency)
# 估算生成的token数
generated_text = result["choices"][0]["text"]
output_tokens = len(generated_text.split())
total_tokens += 128 + output_tokens # 输入 + 输出
print(f"Request {i+1:3d}: latency={latency:.2f}s, output_tokens={output_tokens}")
else:
print(f"Request {i+1:3d}: Failed with status {response.status_code}")
except Exception as e:
print(f"Request {i+1:3d}: Error - {e}")
# 稍微延迟一下,避免压力过大
time.sleep(0.1)
# 计算统计信息
if results:
total_time = sum(results)
avg_latency = statistics.mean(results)
throughput_tokens = total_tokens / total_time
# 计算百分位数
sorted_latencies = sorted(results)
p50 = sorted_latencies[int(len(sorted_latencies) * 0.5)]
p95 = sorted_latencies[int(len(sorted_latencies) * 0.95)]
p99 = sorted_latencies[int(len(sorted_latencies) * 0.99)]
print("
" + "="*60)
print("PERFORMANCE RESULTS")
print("="*60)
print(f"Model: {MODEL_NAME}")
print(f"Total requests: {NUM_REQUESTS}")
print(f"Successful requests: {len(results)}")
print(f"Total test time: {total_time:.2f}s")
print(f"
Latency Statistics:")
print(f" Average latency: {avg_latency:.2f}s")
print(f" P50 latency: {p50:.2f}s")
print(f" P95 latency: {p95:.2f}s")
print(f" P99 latency: {p99:.2f}s")
print(f"
Throughput:")
print(f" Total tokens: {total_tokens}")
print(f" Throughput: {throughput_tokens:.2f} tokens/second")
print(f" Average per request: {total_tokens/len(results):.1f} tokens")
print("="*60)
else:
print("No successful requests!")
EOF
滑动查看完整代码
命令行执行:
python /tmp/test_performance.py
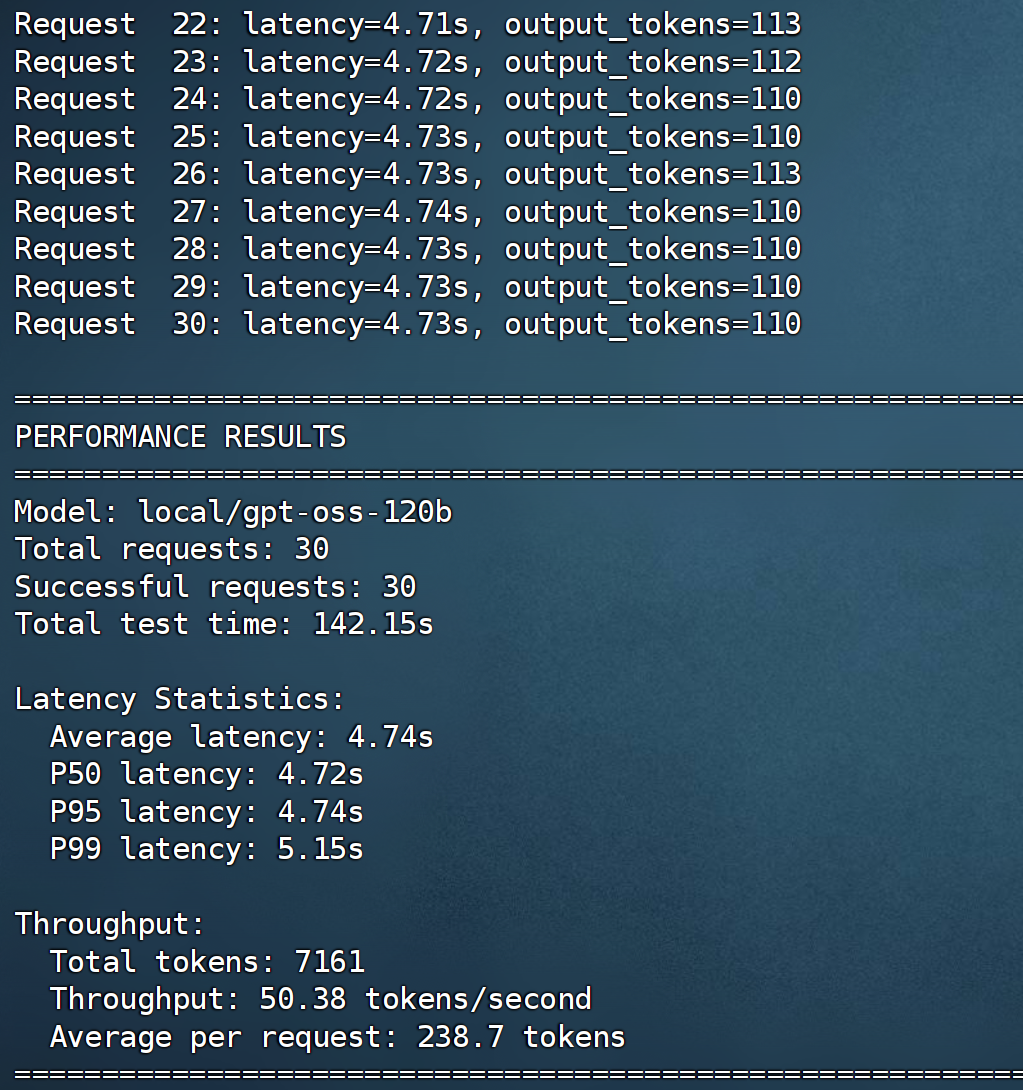
根据上图的测试结果,在单用户、输入 / 输出长度为 128 tokens、并发数为 1 的条件下,系统吞吐量达到了 50.38 tokens / second。这意味着在 Jetson AGX Thor 上能够流畅运行 1,200 亿参数模型。
-
NVIDIA Jetson AGX Thor Developer Kit开发环境配置指南2025-11-08 8066
-
如何在NVIDIA Jetson AGX Thor上通过Docker高效部署vLLM推理服务2025-11-13 4778
-
京东和美团已选用NVIDIA Jetson AGX Xavier 平台2023-08-01 1883
-
Arm方案 基于Arm架构的边缘侧设备(树莓派或 NVIDIA Jetson Nano)上部署PyTorch模型2025-07-28 3370
-
NVIDIA Jetson的相关资料分享2021-11-09 1531
-
怎么做才能通过Jetson Xavier AGX构建android图像呢?2023-06-07 770
-
NVIDIA Jetson AGX Orin提升边缘AI标杆2022-04-09 3065
-
NVIDIA 推出 Jetson AGX Orin 工业级模块助力边缘 AI2023-06-05 2664
-
利用 NVIDIA Jetson 实现生成式 AI2023-11-07 2801
-
NVIDIA Jetson AGX Thor开发者套件概述2025-08-11 2300
-
基于 NVIDIA Blackwell 的 Jetson Thor 现已发售,加速通用机器人时代的到来2025-08-26 1444
-
NVIDIA Jetson AGX Thor开发者套件重磅发布2025-08-28 2016
-
通过NVIDIA Jetson AGX Thor实现7倍生成式AI性能2025-10-29 1989
-
NVIDIA Jetson系列开发者套件助力打造面向未来的智能机器人2025-12-13 3793
-
NVIDIA Jetson模型赋能AI在边缘端落地2026-03-16 1087
全部0条评论

快来发表一下你的评论吧 !
