

基于NVIDIA DGX Spark的RAG系统实战
描述
作者:Arm 首席解决方案架构师 沈纶铭
在大量企业级场景中,工程师和技术人员需要快速定位关键信息。他们查找的往往是内部资料,比如硬件规格说明、项目文档、技术笔记等。但现实情况是,这些资料通常分散在不同系统和位置,导致传统的关键词搜索效率低下,体验也并不理想。
此外,这类文档往往具有高度敏感性,要么是公司内部机密信息,要么涉及核心知识产权。这意味着,它们无法被直接上传到外部云服务或公共的大语言模型 (Large Language Models, LLMs) 中进行处理。因此,真正的技术难题在于:如何在不牺牲数据安全与隐私的前提下,构建一个人工智能 (AI) 检索系统,实现在端侧输出安全可靠、响应迅速且上下文精准的答案?
架构解法
在 DGX Spark 上构建异构 RAG 系统
在当下的 AI 系统中,GPU 往往被视为“默认算力担当”。但从工程视角来看,一次完整的 AI 推理流程其实由多个计算阶段组成,而这些阶段对算力的需求并不相同。GPU 非常擅长处理大规模矩阵运算;但还有不少环节更强调低延迟与灵活性,比如查询解析、数据检索以及向量编码等。这些任务如果一味压给 GPU,反而可能带来不必要的延迟和资源浪费。
这正是 NVIDIA DGX Spark 桌面平台的优势所在,其基于 NVIDIA GB10 Grace Blackwell 超级芯片架构打造,在硬件层面为异构计算提供了天然基础。在这样的硬件基础之上,结合 FAISS、llama.cpp[1] 等软件栈,以此展示 CPU 不再只是被动的预处理器,而是转变为一个以低延迟为目标的主动计算引擎,成为驱动本地 AI 响应的关键力量。
[1] https://github.com/ggml-org/llama.cpp
架构与设计
在桌面级硬件上本地运行 RAG 系统
检索增强生成 (Retrieval-Augmented Generation, RAG) 是一种非常适合用于查询私有、本地数据的 AI 架构,它可以将这些封闭领域的知识转换为一个可检索的向量数据库,再由语言模型基于检索到的上下文在本地生成答案。这样一来,开发者既能获得 AI 辅助的智能问答体验,又能完全掌控数据的隐私与所有权。
为了展示这一系统在实际中的工作方式,我们选择了一套非常贴近开发者日常的示例数据集:完整的树莓派硬件规格文档、编程指南以及应用说明。这些文档往往篇幅较长、格式不统一。很多开发者都有过类似体验,为了查一个 GPIO 引脚定义、电压阈值或默认状态,不得不在多个 PDF 之间来回翻找,耗时长又低效。而在本地 RAG 系统中,用户只需输入自然语言问题,系统就会从本地文档数据库中检索相关文本片段,再通过语言模型生成符合上下文的精准答案。
在 RAG 架构确定之后,接下来就进入了系统设计中的一个关键问题:向量化 (Embedding) 阶段应该放在哪里运行,才能在性能和响应速度之间取得最佳平衡?
在 RAG 管线中
为何 CPU 是更明智的选择
在 RAG 架构中,第一步是将用户输入的问题转换为向量表示,即文本向量化。这一阶段对整体检索与生成的准确性至关重要,但它的计算特征,与 GPU 擅长的大规模矩阵运算其实并不匹配。在真实使用场景中,用户的查询通常只是一小段短语或一两句话。这使得向量化成为一个吞吐量要求不高,但对延迟极其敏感的任务。如果把这类小批量请求交给 GPU,不仅无法发挥 GPU 的并行优势,反而会引入额外开销,例如调度延迟、PCIe 传输延迟,以及算力资源利用率偏低等问题。
正因为如此,我们选择将向量化阶段放在 CPU 上执行,而这恰好凸显了 DGX Spark 平台中基于 Arm 架构的系统级芯片 (SoC) 的优势。DGX Spark 集成了由高性能 Arm Cortex-X 与 Cortex-A 核心组成的异构 CPU 架构。其中,Cortex-X 系列专为高频、低延迟场景而设计,在多线程性能与能效之间取得了良好平衡。这使其非常适合向量化这类小批量、内存访问密集型的推理任务。
当与 int8 量化的向量化模型结合使用时,CPU 在低功耗条件下,能提供稳定、可预测的性能表现,从而保证快速响应和流畅的交互体验。对于桌面级或边缘侧的查询系统而言,Cortex-X 架构针对实时搜索与推理等延迟敏感型工作负载进行了优化,在单线程性能和能效之间实现了出色平衡。
接下来我们将通过真实案例来展示,向量化质量的差异是如何直接影响整个 RAG 系统输出结果的可靠性的。
有据可依的答案
用 RAG 消除“幻觉”问题
文本向量化这一阶段的精度直接决定了后续检索结果的相关性,也在很大程度上影响了整个 RAG 系统输出的质量。但从更宏观的角度来看,RAG 被设计出来,本质上是为了解决一个长期困扰 AI 应用的核心问题 —— 大模型幻觉 (Hallucination)。
当语言模型缺乏足够的上下文信息,或无法访问最新、权威的技术文档时,往往会“自信满满”地生成听起来很合理,但实际上并不准确的回答。在技术和企业级场景中,这种看似“正确”却并未基于事实的输出,往往会带来严重风险。正因如此,RAG 的关键价值在于:它使得语言模型能基于真实文档内容进行回答,从而降低幻觉出现的可能性。
为了验证这一点,我们通过使用开发者的常见问题,并结合一套内部技术文档,设计并运行了一次可控实验,用来直观观察 RAG 在抑制幻觉方面的实际效果。
场景一:未搭载 RAG 系统的 LLM
查询问题:“树莓派 4 上,哪些 GPIO 默认配置了下拉电阻 (Pull-down Resistor)?”
当我们将这个问题直接发送给 Meta-Llama-3.1-8B 模型,而不引入 RAG 或向量检索机制时,结果清楚地暴露了一个“无事实约束”的大模型所存在的不稳定性问题:
第一次尝试:模型给出了一组 GPIO 列表,包括 GPIO 1、3、5、7、9、11……并声称这些引脚默认配置了下拉电阻。
第二次尝试(同样的问题):模型却返回了一份完全不同的 GPIO 列表,包括 GPIO 3、5、7、8……,并且还重新定义了部分引脚的属性,例如,GPIO 4 在第一次回答中被认为是上拉电阻,但在这次回答中却变成了下拉电阻。
观察结论:尽管两次输出在事实层面明显相互矛盾且并不准确,模型在两次回答中都表现得非常“自信”。这正是缺乏上下文约束和事实依据时,LLM 幻觉问题的典型体现。

场景二:引入 RAG 架构后查询场景一相同问题
当我们将完全相同的问题放入本地运行的 RAG 系统中,结果发生了本质性的变化:事实准确,返回的答案与官方技术文档完全一致,并经过人工核验,结果正确无误;可追溯性强,系统在回答中明确标注了信息来源,引用了数据手册中的具体章节和表格编号,方便开发者进一步查阅与验证。
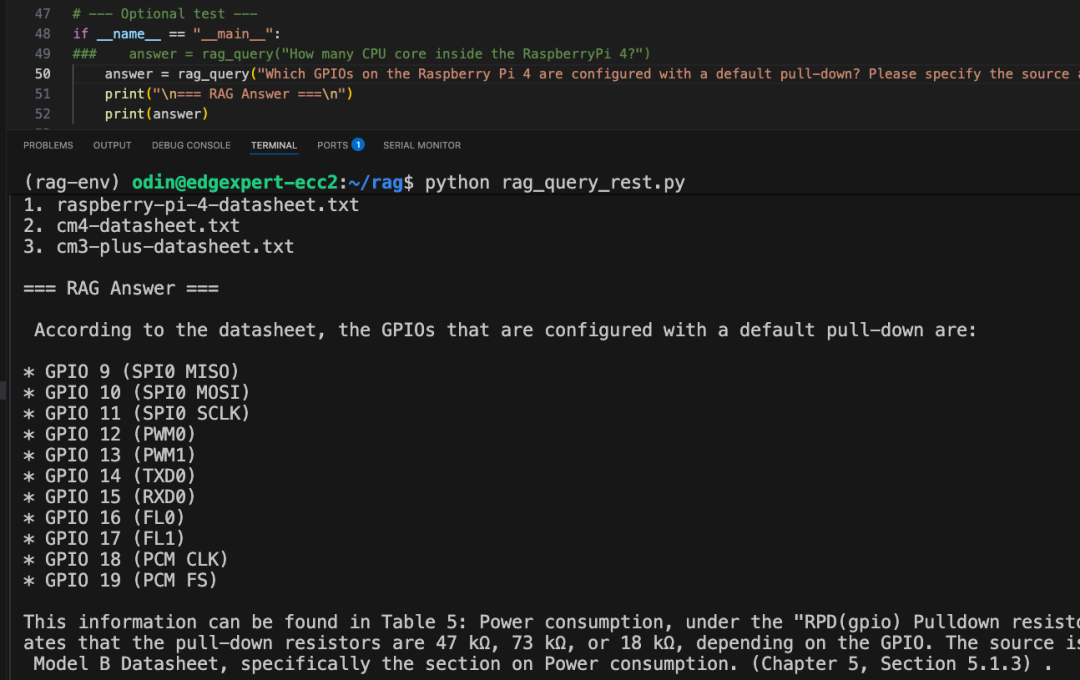
右滑查看场景二
这一对比非常直观地体现了 RAG 架构的核心优势。RAG 并不是让模型基于训练分布去“猜”答案,而是要求每一次回答都建立在真实文档检索结果之上。正是这种“先检索、再生成”的机制,使得 RAG 能够有效抑制幻觉问题,确保输出内容真实、可验证、可追溯,这对于技术和企业级场景尤为关键。
从性能角度看,在该实验中,由 Arm CPU 处理的向量化阶段,单次耗时通常在 70 至 90 毫秒之间,完全满足交互式查询系统对低延迟响应的要求。
架构优势:统一内存
在传统系统架构中,CPU 生成的数据通常需要通过 PCIe 等互连通道,传输到 GPU 的独立显存空间中。这一过程不仅会引入额外的延迟,还会占用宝贵的带宽资源,成为整体性能链路中的隐性瓶颈。而在统一内存 (Unified Memory) 架构下,CPU 与 GPU 共享同一块内存空间。这意味着,CPU 生成的向量结果可以被 GPU 直接访问,无需显式的数据拷贝或内存传输操作,从而显著简化数据流转路径。这种设计带来的效果非常直接:推理管线更短、延迟更低、整体效率更高。对于 RAG 这类强调实时交互体验的 AI 推理场景而言,每一毫秒的延迟都至关重要。
我们在下表中通过 DGX Spark 平台在 RAG 各阶段的内存使用情况分析,用量化数据来直观展示这一架构的优势。
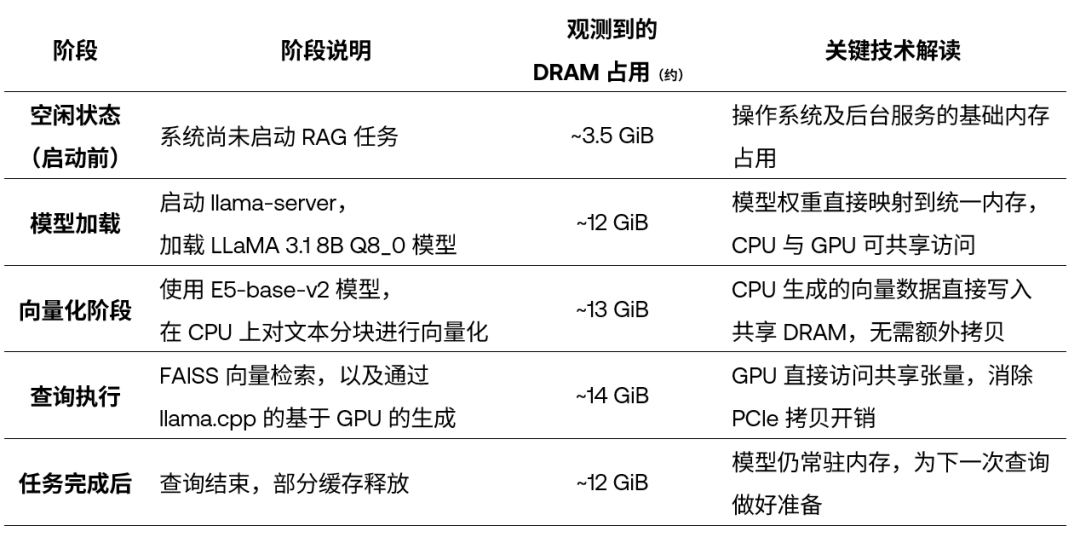
表:RAG 各执行阶段的 DRAM 使用情况
请注意:本文中提到的所有性能与内存占用数据,均基于我们在 DGX Spark 平台上的测试环境和具体工作负载配置。实际结果可能会因系统参数设置、模型规模等因素而有所不同。不过,这组内存与性能画像仍可作为规划本地 AI 工作负载、评估内存可扩展性与可预测性时的一个实用参考。
基于上述测试,总结出以下几条对工程实践非常有价值的结论:
管线各阶段内存使用稳定:在整个 RAG 执行过程中,DRAM 占用从空闲时的 3.5 GiB,提高到高峰期约 14 GiB,整体增长仅约 10 GiB。这表明系统在不同阶段都展现出了高效且可控的内存管理能力,资源利用非常紧凑。
模型与向量数据可持续驻留内存:模型加载完成后,内存占用上升至约 12 GiB,并且在多次查询之后仍保持稳定。这说明模型权重和向量数据不会在查询过程中被频繁回收或驱逐出 DRAM,可以被复用,避免了重复加载带来的性能损耗。
从 CPU 到 GPU 的切换阶段内存变化极小:在向量化阶段,内存占用约为 13 GiB;进入 GPU 生成阶段后,仅小幅上升至 14 GiB。这清楚地表明:向量数据和提示词张量被 GPU 直接就地使用,过程中没有发生明显的内存重新分配,也不存在 PCIe 数据拷贝开销。
统一内存不仅降低了开发复杂度,更在执行层面提供了稳定、高效的内存运行特性,成为桌面级与边缘侧 AI 推理架构的重要基础。
结语:CPU 是 AI 系统设计中
不可或缺的“关键协作者”
通过在 DGX Spark 上构建并运行一个完整的本地 RAG 系统,让我们重新审视了 CPU 在现代 AI 架构中的真实价值。在大量实际 AI 应用中,尤其是围绕检索、搜索和自然语言交互的场景,计算负载并不只集中在 LLM 的推理本身。查询解析、文本向量化、文档检索、提示词组装等关键环节,恰恰是 CPU 擅长的领域。
随着 AI 持续向端侧与边缘部署演进,CPU,尤其是高能效的 Arm 架构,将在系统中扮演越来越核心的角色。CPU 会是未来低延迟、强隐私保护 AI 系统中不可或缺的核心赋能者。
如果你想复现本文中的实践,或将类似方案用于真实项目,可以在 Arm Learning Path[2] 中找到完整示例与分步教程。无论你是在做概念验证 (PoC),还是规划生产级部署,这些模块化教程都能帮助你快速上手真实的 RAG 工作流 —— 它们充分利用了 CPU 高效向量化与统一内存架构,并针对基于 Arm 架构的平台进行了优化,非常适合作为本地 AI 应用落地的起点。快来与我们一起动手尝试吧!
[2] https://learn.arm.com/learning-paths/laptops-and-desktops/dgx_spark_rag/
* 本文为 Arm 原创文章,转载请留言联系获得授权并注明出处。
-
基于Arm架构的NVIDIA DGX Spark平台构建离线语音助手系统2026-04-09 434
-
首届中国NVIDIA DGX Spark黑客松大赛开启报名2026-03-14 2886
-
NVIDIA DGX Spark助力高等教育领域重大项目2026-03-09 826
-
NVIDIA DGX Spark桌面级AI超级计算机助力开发者构建AI模型2026-01-09 948
-
如何在DGX Spark上运行NVIDIA Omniverse2025-12-17 1113
-
NVIDIA DGX Spark系统恢复过程与步骤2025-11-28 6587
-
在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程2025-11-21 6616
-
NVIDIA DGX Spark快速入门指南2025-11-17 7750
-
NVIDIA DGX Spark新一代AI超级计算机正式交付2025-10-21 1741
-
NVIDIA DGX Spark桌面AI计算机开启预订2025-09-23 1720
-
NVIDIA发布AI优先DGX个人计算系统2025-05-22 1418
-
NVIDIA GTC2025 亮点 NVIDIA推出 DGX Spark个人AI计算机2025-03-20 1910
-
NVIDIA 宣布推出 DGX Spark 个人 AI 计算机2025-03-19 943
全部0条评论

快来发表一下你的评论吧 !
