

先楫方案 | LED车尾灯纯硬件高刷新率解决方案
描述
上海先楫半导体科技有限公司(先楫半导体, HPMicro) 基于国产高性能MCU HPM6P00推出纯硬件高刷新率的LED车尾灯解决方案。
HPM6P00系列MCU是先楫半导体推出的高性能MCU,该MCU搭载单核32位RISC-V处理器,主频高达600MHz,内置1MB ⾼速Flash和256KB SRAM,32KB 高速缓存 (I/D Cache),128KB ILM(本地指令存储器)和128KB DLM(本地数据存储器) 零等待RAM。该系列支持2个集成电路内置音频总线I2S,每个I2S支持多种音频标准如I2S,LSB对齐,MSB对齐,PCM,TDM等,能满足多种单声道和立体声应。每个I2S支持4路发送数据信号和4路接收数据信号,支持工作在主模式和从模式,支持独立的时钟配置,可以支持多种码率的音频。I2S 每个 TX 带有8字深,32位宽的输入输出FIFO缓冲区域,为高速数据流输出提供了硬件基础。
本车尾灯显示方案基于HPM6P00的I²S接口,结合链式DMA与SPI外设,实现对LED行驱动芯片(ICN2012)与列驱动芯片(ICN2038)的高效控制。通过利用I²S多通道同步输出特性,配合链式DMA自动完成整屏扫描与数据刷新,实现了CPU 零负载参与刷屏过程,仅需在后台更新显存数据,系统性能远超传统GPIO扫描方式,刷新率与显示效果显著提升。


方案特性
1、核心特性:
全硬件自动扫描:基于链式DMA + I²S + SPI协同工作,刷屏过程无需CPU介入。
高刷新率与低延迟:支持最高25MHz驱动时钟,单行(128列)扫描时间仅约7μs。
灵活的色彩深度:支持RGB111/222/333/444/555等多种灰度等级。
强大的扩展能力:单系统最多可驱动 256列 × 232行 LED点阵。
高可靠性设计:支持R/G/B信号分流控制(R2/G2/B2),避免过流风险。
2、关键性能指标:
当前硬件配置:128列 × 26行
最大理论扩展:256列(基于8×32位FIFO)× 232行(基于32位GPIO组解码)
扫描时钟:≤ 25MHz(受驱动芯片限制)
CPU占用率:刷屏期间 0%
数据更新方式:CPU仅更新SRAM中的显示缓冲区,由DMA自动搬运至I²S发送
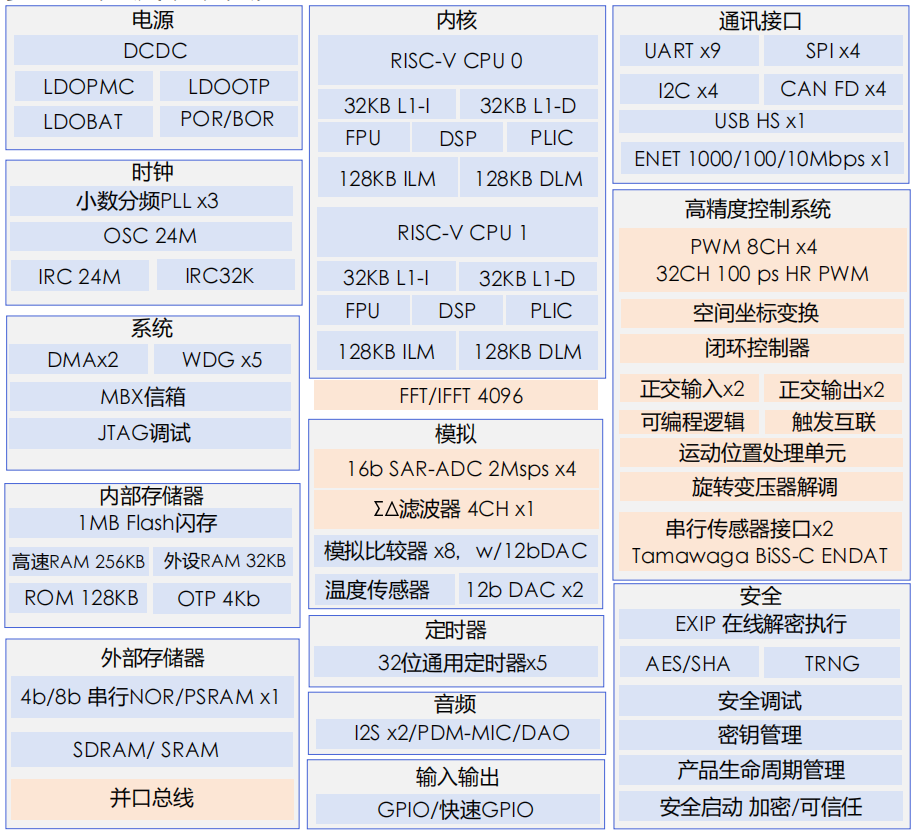
系统架构
1、本方案以先楫半导体HPM6P00系列高性能MCU为核心控制器,充分发挥其丰富的外设与高带宽互联架构。系统利用其两路I²S接口共8个发送通道,分别控制LED的色光与锁存信号(R1/G1/B1、R2/G2/B2、LE、OE)。其中,R2/G2/B2通道可根据设计需求,用于扩展驱动能力或实现信号分流,以支持更高密度或更大电流的LED阵列。行选控制则由一组GPIO实现,用于寻址与使能相应的行驱动芯片。
2、为确保两路I²S输出数据严格同步,本方案引入SPI模块作为主时钟源,由其提供统一的位时钟(SCLK)至两个I²S接口,从而保证色彩与控制信号的时序对齐。
3、整个扫描与刷新流程完全由链式DMA自主协调,无需CPU介入。DMA自动从显存搬运数据,通过I²S发送至驱动芯片,并同步控制GPIO切换行选,实现了从内存到屏端的全硬件自动化驱动。
4、系统整体架构如下图所示,清晰展示了数据流、控制流与时钟关系:
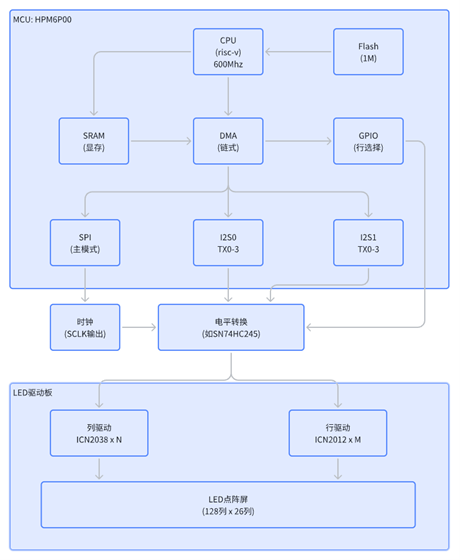
软件设计
该方案软件采用分层与硬件加速协同的设计架构,实现了从图形渲染到信号输出的全流程高效管理。其核心在于利用链式DMA构建了一个自主运行的刷新“引擎”,使CPU在刷屏过程中完全解放。具体数据流与控制流如下图所示:
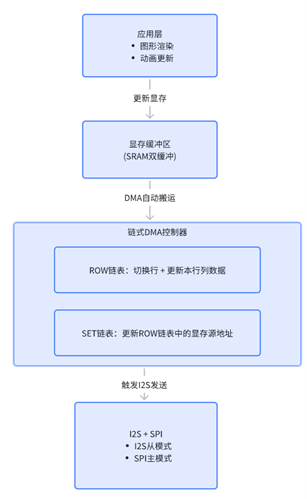
1、架构核心解读:
a. 应用层: 仅负责内容的生成与更新(如图形、动画),将最终帧数据写入显存缓冲区。
b. 显存双缓冲: 在SRAM中开辟两个缓冲区,前台用于DMA读取发送,后台用于应用写入,避免画面撕裂,实现平滑更新。
c. 链式DMA控制器(核心引擎):
ROW链表:像一个预设好的“行扫描脚本”,每个节点自动完成一行LED的驱动(切换行+发送该行所有列数据)。所有节点链接成环,实现周而复始的自动扫描。
SET链表:是关键的性能优化设计。它充当“导演”角色,在每一帧刷新开始时,自动修改所有ROW节点中指向显存的地址,使其指向新一帧的数据。这避免了为每一行重复配置DMA,极大地节省了内存和CPU配置开销。
d. 硬件输出层: I²S在SPI提供的主时钟下同步工作,将DMA搬运来的并行像素数据,转化为串行信号输出至LED驱动芯片,完成最终的电平控制。
2、DMA链式配置:

a. ROW链表:
每个节点对应一行的扫描过程:先输出行选信号(通过GPIO组),随后通过I²S发送该行对应的所有列RGB数据。
所有行的ROW节点链接成一个循环链表,DMA自动依次执行,实现连续行扫。
b. SET链表:
用于在帧刷新时,批量更新所有ROW节点中对应的显存源地址(指向新帧数据)。
此设计避免了为每一行单独预配置大量DMA描述符,极大节省了RAM开销。
总结而言: 此架构通过“双缓冲显存”与“ROW+SET双链表DMA”的精密配合,构建了一个高度自动化、低延迟的刷新流水线。CPU仅在后台更新显存内容,刷屏全流程由DMA驱动硬件自主完成,实现了极致的性能与效率。
性能实测
1、测试条件
显示分辨率:128列 × 26行
色彩深度:RGB555(16位色)
I²S时钟:25MHz (受限驱动芯片频率)
驱动芯片限制频率:25MHz
2、实测结果
单行扫描时间:约7μs(128列数据)
整帧刷新时间:26行 × 7μs x 32(RGB555)≈ 6ms
理论最大帧率:≥ 100 fps(纯扫描,不含渲染时间)
CPU占用率:刷屏期间 0%(由DMA全权负责)
数据更新延迟:CPU写入显存后,最晚在下一帧即可显示(双缓冲机制下无撕裂)
3、优势对比
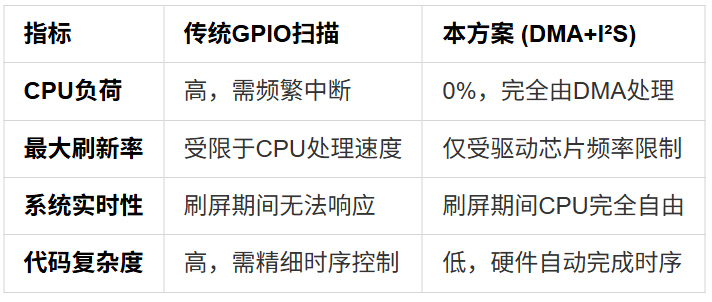
-
基于FPGA的汽车尾灯控制电路设计与实现2011-11-10 14821
-
电动车尾灯改LED真相2015-12-29 9682
-
罗姆汽车尾灯电流调解模块方案2019-03-15 2823
-
如何实现汽车尾灯控制设计2019-06-24 2910
-
基于Proteus的汽车尾灯控制系统该如何去设计?2021-06-15 2690
-
数电课设汽车尾灯控制电路2021-07-22 2914
-
汽车尾灯控制设计2008-12-13 1204
-
汽车尾灯VHDL设计2007-08-21 5073
-
基于Multisim的汽车尾灯控制方案2011-10-08 29351
-
汽车尾灯控制电路工作原理及设计2012-11-01 73112
-
汽车尾灯逻辑检测装置的设计2017-11-21 1256
-
汽车尾灯气密性检测是如何做到的2021-01-22 1809
-
【大大芯方案】引领尾灯视觉潮流,大联大推出基于NXP 产品的汽车尾灯方案2023-11-02 1508
-
多元化、高辨识显示丨基于G32A1445的汽车尾灯解决方案2024-05-11 2582
-
汽车尾灯电流高速采集监测方案2024-11-25 1684
全部0条评论

快来发表一下你的评论吧 !
