

 双目视觉是如何实现深度估计的?
双目视觉是如何实现深度估计的?
描述
[首发于智驾最前沿微信公众号]自动驾驶的纯视觉方案中,单目摄像头因无法直接感知深度,在环境理解上存在根本局限,双目视觉技术在此需求下应运而生。它通过模拟人眼,利用双摄像头的视差来推算距离,将二维图像转化为三维信息,从而为车辆决策提供关键的深度感知能力。
什么是双目深度估计?
平时我们用眼睛看东西其实就是一种最自然的深度估计。人的两只眼睛有一定的间距,大脑通过融合两只眼睛看到的略有不同的图像来判断远近。计算机视觉里“双目深度估计”就是借鉴这个原理,将两个相机并排排列,并拍下同一场景,然后分析两幅图像的差异来推算距离。
单目摄像头拍摄的二维图像,仅包含色彩与亮度信息,无法直接提供场景中物体的距离数据。要获取“距离”这一关键的深度信息,关键在于利用视差,也就是在另一个位置放置第二个相机,同时对同一场景成像。此时,物体在两个视角的图像中会产生位置偏移,通过计算这一偏移量,便可以精确推算出物体的三维距离。
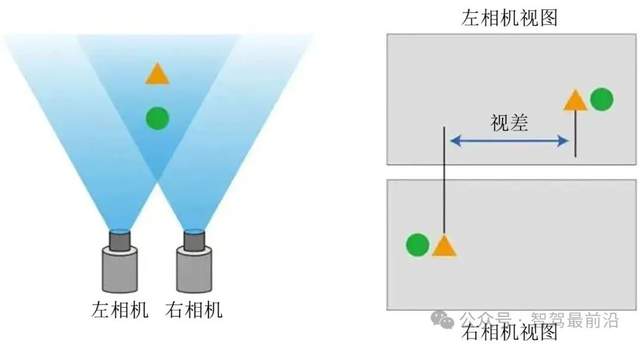
图片源自:网络
如果我们知道了两个摄像头之间的距离(基线)和摄像机的焦距,当我们找到两个图像里同一个物体对应点的位置差(视差)时,就能用一个非常简单的公式计算出这个点的真实深度,即:
深度=焦距×基线/视差。
从公式中我们可以看到,视差越大,物体越近;视差越小,物体越远。

双目深度估计的主要步骤
既然说到了视差,那么关键问题来了,怎么从一对左右图像里找到这些对应点?这中间其实涉及到多个流程。

图片源自:网络
两个摄像头从出厂到装在一起时,会有一些位置和角度误差,所以我们需要先做几何标定,确定每个摄像头的内部参数(比如焦距、主点位置)和它们之间的外部关系(位置和朝向)。只有这样才能让后面比较两个图像时的像素位置是准确对应的。
在完成双目系统的校准后,接下来要做的就是立体矫正。这一过程的目的是把两个图像都调整成在同一条水平线上,这样同一场景点在左右图像里的对应关系只会在水平方向上变化,这极大简化了后面的匹配难度。
立体匹配的核心任务,就是在左右两幅图像中为同一物体找到相互对应的像素点。由于之前已经做了立体矫正,这个搜索被大大简化了,只需要在右图中沿着与左图像素点对应的同一水平线去扫描,找出看起来最相似的那个区域即可。尽管如此,要为图像中每一个像素找到对应点,计算量依然会非常庞大。因此可借助如经典的块匹配(Block Matching)或效果更优的半全局匹配(Semi-Global Matching,SGM)来实现高效的匹配。
当我们找到每个像素的对应关系之后,就可以算出视差值。视差是同一个点在左右图像中水平方向坐标差的数量,这个差值越大代表这个点离相机越近。最后,把视差值带入我们前面提到的公式,就能得到每一个像素对应的深度值。这样我们就生成了一张“深度图”,每个像素不再只是颜色信息,还可以是一个距离值。
深度学习方法对双目深度估计有何作用?
通过传统计算机视觉方法完成上面的这些步骤,其实就可以做好双目深度估计了,但是传统方法主要依赖手工设计的特征和匹配算法,如比较左右图像里像素块的相似度,然后决定它们是不是对应的点。这样一来在一些纹理稀少的区域、光照变化大的情况下,这种匹配就很容易出错,而且计算量也不小。
近年来,深度学习也被引入双目深度估计领域。其核心目标与传统方法一致,仍是寻找左右图像间的对应关系并计算视差,但实现方式发生了根本改变。深度学习不再依赖人工设计的匹配代价与规则,而是通过卷积神经网络自动从数据中学习匹配特征。

图片源自:网络
该网络以左右视图作为输入,直接输出视差图或深度图。在大量立体图像数据训练下,网络能够自主掌握哪些图像特征利于匹配、哪些场景容易产生歧义,从而显著提升匹配的鲁棒性。因此,在遮挡区域、重复纹理或缺乏纹理的环境等传统方法容易失效的场景下,基于深度学习的方法会表现出更高的准确度和稳定性。
深度学习方法的处理流程是先用神经网络提取左右图像的特征,然后构建一个“代价体”,表示在不同视差值下左右特征的匹配代价。接着再让网络学习从代价体里回归出最终的视差值。整个过程可以端到端训练,不需要手工调各种参数。
当然,端到端的深度学习系统需要大量带真实深度标注的数据来训练模型,而且在训练数据和真实应用场景不一致时表现可能下降。这就需要一些自监督、数据增强等策略来提升鲁棒性。
双目深度估计会遇到什么问题?
双目深度估计一个常见的问题是像素匹配不准确。如果物体表面没什么纹理,两个视角的图像看起来就会一模一样,这就让系统难以判断哪个点是对应到哪个点。有些算法为了弥补这个问题,会用更复杂的特征或者上下文信息来辅助匹配,但仍不是万无一失的。

图片源自:网络
我们讲的匹配过程是假设两个图像在同一时间点拍的。如果场景里有如行人、车辆等移动的物体,而两个摄像头抓拍的时间有微小差异,这就会让匹配变得更难。深度学习方法可以用时序信息来缓解,但这本质上还是一个复杂问题。
在双目立体系统的设计中,基线长度的选取,本质上是在测量精度和工程落地之间做选择。基线越长,同一物体在左右图像中产生的视差就越大,这不仅使匹配更容易,也能有效提高深度估计的精度。过长的基线会带来安装空间、机械稳定性以及视野重叠区域减少等问题。但基线过短,远处物体的视差将变得极其微小,在像素级的计算中很容易被图像噪声、量化误差等因素所淹没,从而导致深度估计失效。
最后,还有像光照变化、遮挡、反射表面这些现实场景都会让匹配变得不稳定。这也是为什么在双目系统设计中,需要花费大量精力在图像预处理、匹配优化、后处理滤波等步骤上。
最后的话
双目深度估计的应用场景十分广泛,除了自动驾驶,它在工业检测、无人机测绘、实时三维建模等领域也发挥着重要作用。在需要快速感知和重建三维空间的场景中,双目视觉结合点云生成等技术,能够实现高效的实时环境建模。虽然激光雷达等主动式传感器在精度上更具优势,但双目方案以其显著的成本优势,成为许多对成本敏感应用的理想选择。
审核编辑 黄宇
- 相关推荐
- 热点推荐
- 双目视觉
-
双目视觉在智能驾驶领域的应用2025-07-09 1642
-
双目立体视觉是什么?单目视觉与双目立体视觉的区别?2023-08-17 6461
-
双目视觉简介及算法一般流程2020-10-23 13903
-
在DM642开发评估板上实现双目视觉监控系统的软硬件设计方案2020-05-07 1759
-
LabVIEW双目视觉 【转载】2020-03-02 9293
-
钜芯发布业内首颗智能双目视觉芯片2017-10-26 11539
-
基于SoC的双目视觉ADAS解决方案2016-11-05 3785
-
一种基于图像处理的双目视觉校准方法2015-12-18 961
-
【WRTnode2R申请】双目视觉随动平台2015-09-10 2566
-
双目视觉传感器的现场标定技术2012-03-02 1011
-
基于结构光双目视觉的智能机器人系统2011-08-31 1815
-
双目视觉立体匹配算法研究2010-08-14 1495
-
一种变结构控制的双目视觉伺服控制方法2010-01-13 706
-
基于神经网络的双目视觉传感器建模2009-07-10 439
全部0条评论

快来发表一下你的评论吧 !
