

如何使用OpenVINO在Intel显卡上部署PaddleOCR-VL模型
电子说
描述
一,引言
1、为什么需要智能文档解析?
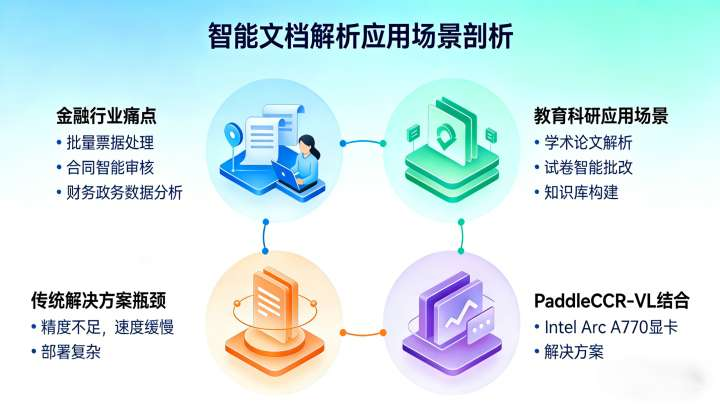
1.1 刚性应用场景剖析
在现代数字化转型浪潮中,文档智能解析已成为各行各业的刚性需求。在金融与教育领域,高效准确的文档处理能力直接影响着工作效率和业务质量。
1.2 金融行业的痛点与需求
批量票据处理:银行每日需处理成千上万的票据扫描件,传统人工录入耗时耗力且易出错
合同智能审核:金融机构需要快速提取贷款合同中的关键条款、金额、期限等信息
财报数据分析:投资机构需要从PDF财报中自动提取表格数据,进行快速分析和决策
1.3 教育科研的应用场景
学术论文解析:自动提取论文中的公式、图表、参考文献信息
试卷智能批改:识别手写答案与印刷题目的混合内容
知识库构建:从教材和文献中抽取知识点,构建结构化知识体系
1.4 传统解决方案面临三大瓶颈:
精度不足:复杂版式、混合元素识别准确率低
速度缓慢:大批量文档处理效率低下
部署复杂:需要专业技术团队长期维护
面对上述挑战,PaddleOCR-VL结合Intel Arc A770显卡提供了先进的解决方案,实现了性能与成本的最佳平衡。
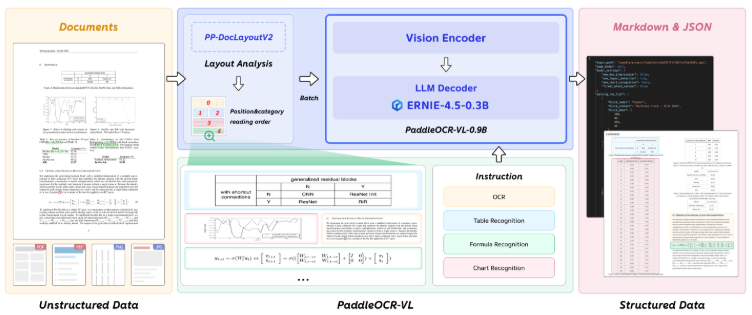
二,模型架构
PaddleOCR-VL 是一款先进、高效的文档解析模型,专为文档中的元素识别设计。其核心组件为 PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型组成,能够实现精准的元素识别。该模型支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过在广泛使用的公开基准与内部基准上的全面评测,PaddleOCR-VL 在页级级文档解析与元素级识别均达到 SOTA 表现。它显著优于现有的基于Pipeline方案和文档解析多模态方案以及先进的通用多模态大模型,并具备更快的推理速度。这些优势使其非常适合在真实场景中落地部署。
三,开始部署
首先,在命令提示行或Anconda执行命令下载源文件
git clone https://github.com/zhaohb/paddleocr_vl_ov.git
然后再执行命令,进行环境设置:
conda create -n paddleocr_vl_ov python=3.12 conda activate paddleocr_vl_ov pip install -r requirements.txt pip install --pre openvino==2025.4.0rc3 openvino-tokenizers==2025.4.0.0rc3 openvino-genai==2025.4.0.0rc3 --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
使用指令将魔搭社区转换完成的模型下载至本地
pip install modelscopemodelscope download --model zhaohb/PaddleOCR-Vl-OV
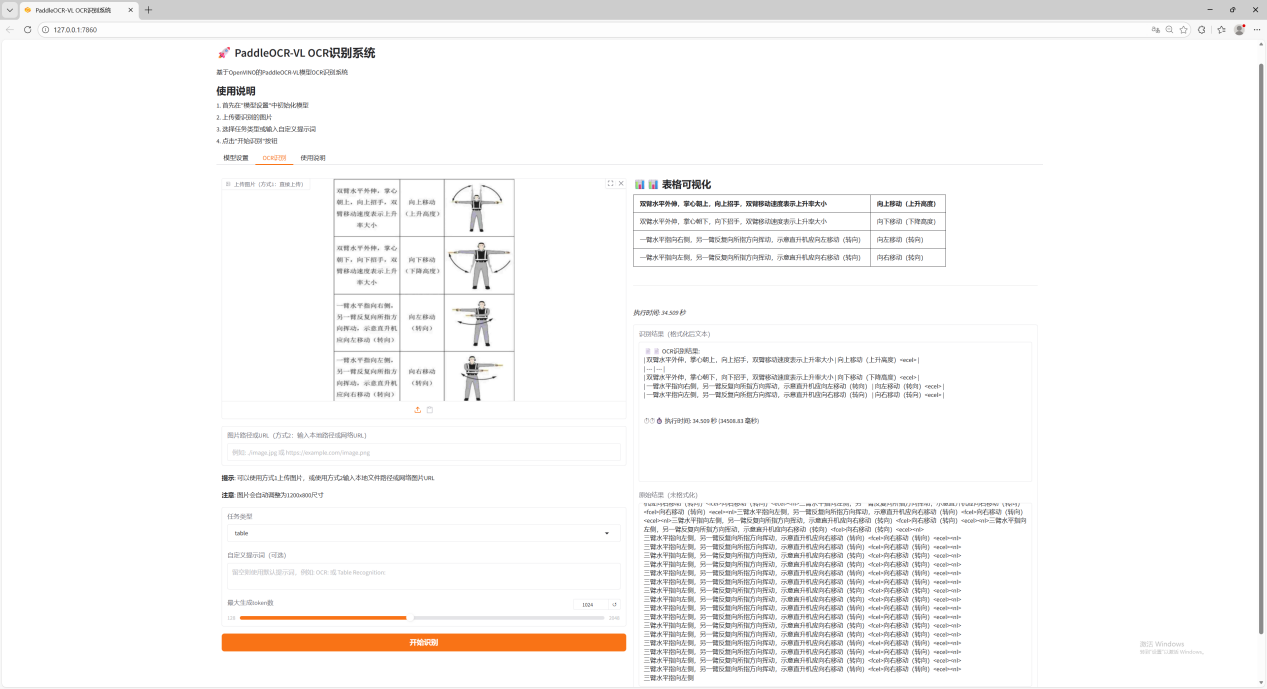
四,运行Demo
执行命令启动Gradio演示,启动成功后会点击访问地址拉起网页
Python paddleocr_vl_grdio.py

视频链接:如何使用OpenVINO在Intel显卡上部署PaddleOCR-VL模型
五,总结
本文完整演示了如何在Intel A770 显卡上部署并运行 PaddleOCR-VL 文档解析模型,结合 OpenVINO 工具套件实现高效推理。从环境搭建、模型下载到运行 Gradio 演示界面,整个流程清晰明了,用户可快速上手体验 PaddleOCR-VL 在复杂文档元素识别中的强大能力。如果您在部署过程中遇到任何问题或者有其他需求,欢迎随时联系我们获取支持。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
登临科技GPU+架构深度适配PaddleOCR-VL-1.6模型2026-06-04 1122
-
百度正式发布并开源新一代文档解析模型PaddleOCR-VL-1.52026-01-30 973
-
使用 Docker 一键部署 PaddleOCR-VL: 新手保姆级教程2025-12-18 7101
-
使用OpenVINO Model Server在哪吒开发板上部署模型2024-11-01 1496
-
NNCF压缩与量化YOLOv8模型与OpenVINO部署测试2023-11-20 2888
-
如何使用OpenVINO C++ API部署FastSAM模型2023-11-17 2075
-
基于OpenVINO C# API部署RT-DETR模型2023-11-10 2143
-
在OpenNCC上部署人脸检测模型2023-06-27 696
-
LabVIEW+OpenVINO在CPU上部署新冠肺炎检测模型实战(含源码)2023-03-23 2773
-
在英特尔独立显卡上部署YOLOv5 v7.0版实时实例分割模型2022-12-20 6162
-
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型2022-11-18 3945
-
如何用Arm虚拟硬件在Arm Cortex-M上部署PaddlePaddle2022-09-02 3221
-
介绍在STM32cubeIDE上部署AI模型的系列教程2021-12-14 3385
-
使用OpenVINO™ 部署PaddleSeg模型库中的DeepLabV3+模型2021-11-22 11339
全部0条评论

快来发表一下你的评论吧 !
