

沐曦曦云C500/C550 GPU产品适配腾讯混元开源翻译模型1.5版本
描述
12月30日,腾讯混元宣布推出并开源翻译模型1.5,共包含两个模型:Tencent-HY-MT1.5-1.8B 和 Tencent-HY-MT1.5-7B,两个模型均重点支持 33 个语种互译以及5种民汉/方言,除了中文、英语、日语等常见语种,也包含捷克语、马拉地语、爱沙尼亚语、冰岛语等小语种。目前两个模型均在腾讯混元官网上线,通过开源社区也可以直接下载使用。 沐曦曦云C500/C550已完成Day 0适配,完成在vllm框架下对Tencent-HY-MT1.5的推理支持。
本次发布,沐曦之所以能实现快速适配,正是基于全栈自研MXMACA软件栈的强大生态适配能力。近日,MXMACA已发布3.3.0.X版本,作为连接沐曦自研GPU硬件与上层应用生态的关键协同载体,将持续聚焦生态强化与场景深度适配。
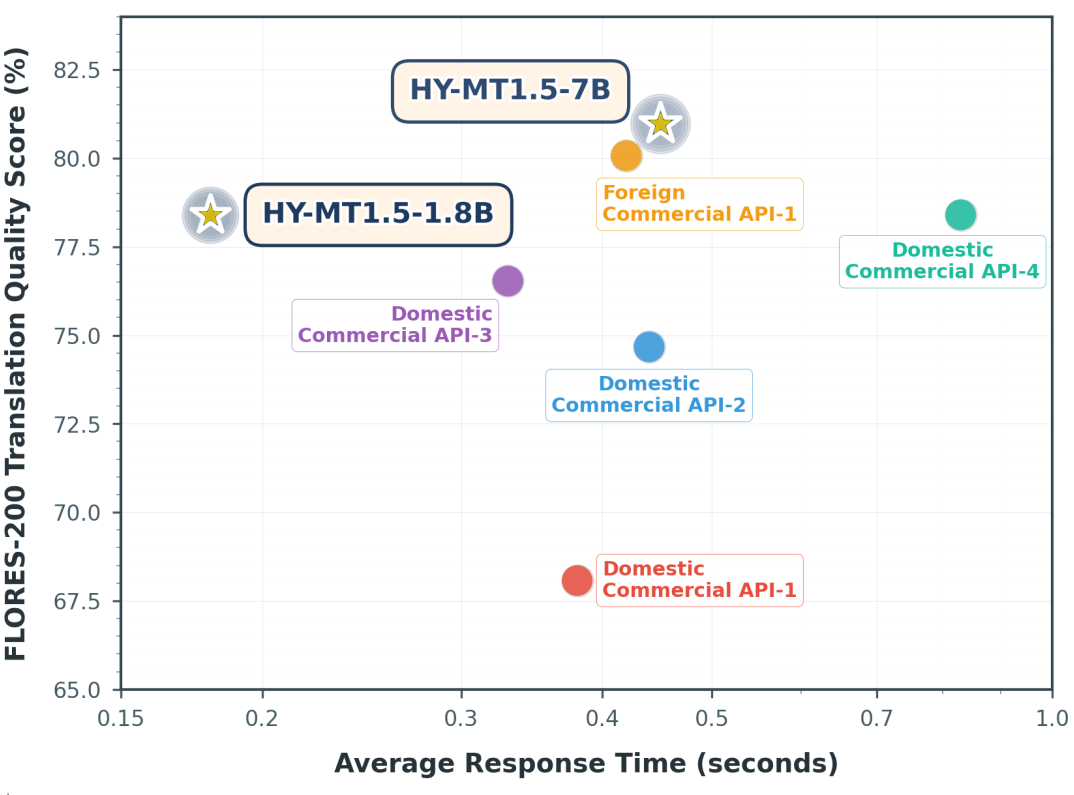
HY-MT1.5-1.8B模型在FLORES-200质量评估中取得了约78%的分数,同时平均响应时间仅为0.18秒,超越主流商用翻译API,显示出明显的速度优势,凭借优秀的模型设计和推理逻辑,其领先的推理效率使其高度适用于即时通讯、智能客服、移动翻译等高吞吐、实时翻译应用场景。
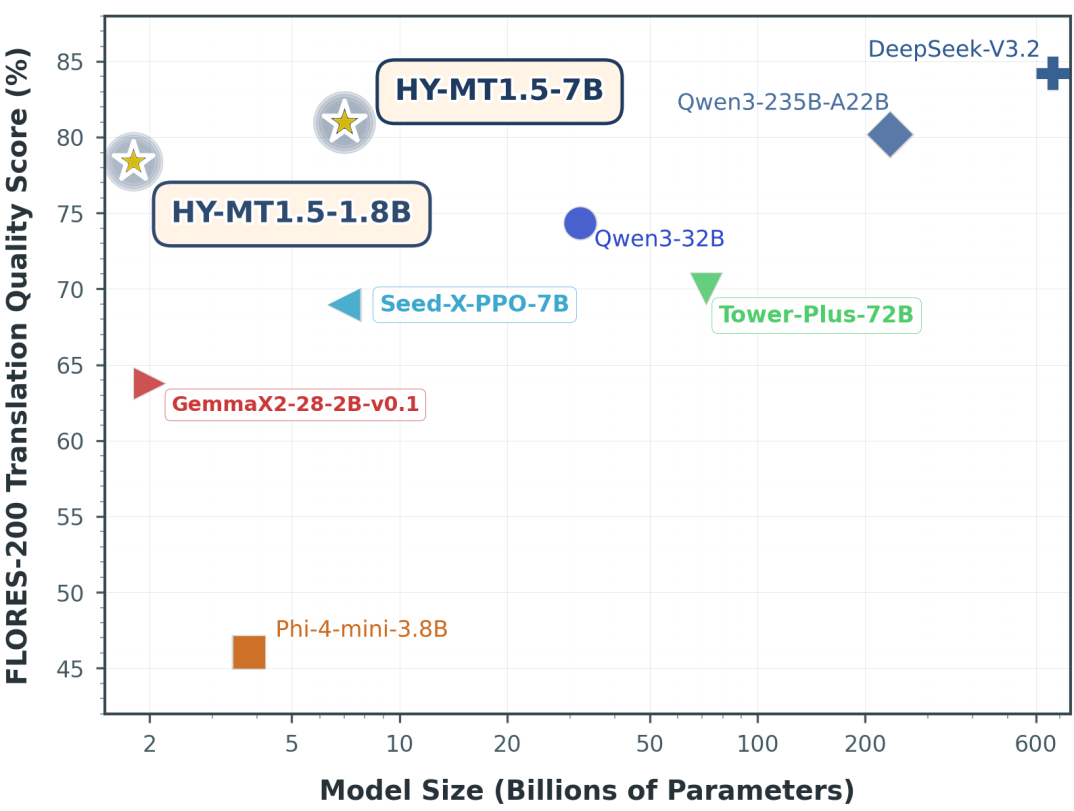
HY-MT1.5-7B 模型是此前获得WMT25 30个语种翻译比赛冠军模型的升级版,重点提升了翻译准确率,相较前一版本大幅减少了译文中夹带注释和语种混杂的情况,实用性进一步增加。
沐曦与腾讯混元长期保持合作关系,依托全栈自研算力底座,持续为混元大模型提供自主可控的训推一体支撑,实现国产算力与国产大模型的深度协同。
关于沐曦股份
沐曦股份致力于自主研发全栈高性能GPU芯片及计算平台,为智算、通用计算、云渲染等前沿领域提供高能效、高通用性的算力支撑,助力数字经济发展。
-
完成适配!曦云C500在智谱AI升级版大模型上充分兼容、高效稳定运行2023-08-23 9959
-
沐曦加速DeepSeek满血版单卡C500异构推理2025-03-20 2775
-
沐曦曦云C500通用计算GPU与百度飞桨完成Ⅱ级兼容性测试2025-03-31 2119
-
沐曦股份曦云C系列GPU Day 0适配智谱GLM-4.6V多模态大模型2025-12-17 989
-
沐曦曦云C500/C550 GPU产品适配PaddleOCR-VL-1.5模型2026-01-30 1722
-
沐曦曦云C500/C550 GPU产品适配腾讯混元图像3.0图生图模型2026-02-02 733
-
沐曦曦云C500/C550 GPU产品适配智谱GLM-OCR模型2026-02-03 1130
-
曦云C系列GPU Day 0 适配智谱全新一代大模型GLM-52026-02-12 1305
-
沐曦曦云C500/C550 GPU产品深度适配MiniMax M2.5模型2026-02-26 1395
-
沐曦股份曦云C系列GPU产品Day 0适配智谱GLM-5.1旗舰模型2026-04-09 633
-
沐曦股份曦云C系列GPU产品Day 0适配腾讯混元Hy3 preview语言模型2026-04-28 1904
-
沐曦股份曦云C系列GPU产品深度适配腾讯混元翻译模型Hy-MT22026-05-22 2093
-
沐曦股份曦云C系列GPU产品Day 0适配阶跃星辰开源Step 3.7 Flash模型2026-05-30 1713
-
沐曦股份曦云C系列GPU产品Day 0适配MiniMax M3大模型2026-06-14 300
全部0条评论

快来发表一下你的评论吧 !
