

基于现场可编程器件的原型技术验证asic的设计
描述
在对asic设计进行fpga原型验证时,由于物理结构不同,asic的代码必须进行一定的转换后才能作为fpga的输入。现代集成电路设计中,芯片的规模和复杂度正呈指数增加。尤其在asic设计流程中,验证和调试所花的时间约占总工期的70%。为了缩短验证周期,在传统的仿真验证的基础上,涌现了许多新的验证手段,如断言验证、覆盖率驱动的验证,以及广泛应用的基于现场可编程器件(fpga)的原型验证技术。
采用fpga原型技术验证asic设计,首先需要把asic设计转化为fpga设计。但asic是基于标准单元库,fpga则是基于查找表,asic和fpga物理结构上的不同,决定了asic代码需要一定的修改才能移植到fpga上。但应该注意到这只是由于物理结构不同而对代码进行的转换,并不改变其功能,因此对代码的这种修改只能限制在一定范围内。
基本原理
基于fpga原型验证的流程
由于fpga的可编程特性,基于fpga的原型技术已经被广泛采用。和仿真软件相比,fpga的硬件特性可以让设计运行在较高的频率上,加速仿真。另一方面,可以在asic芯片设计前期并行设计外围电路及应用软件,缩短了芯片验证周期。
fpga原型验证和其他验证方法是不同的,任何一种其他验证方法都是asic验证中的一个环节,而fpga验证却是一个过程。由于fpga与asic在结构、性能上各不相同,asic是基于标准单元库,fpga用的是厂商提供的宏单元模块,因此首先要进行寄存器传输级(rtl)代码的修改。然后进行fpga器件映射,映射工具根据设置的约束条件对rtl代码进行逻辑优化,并针对选定的fpga器件的基本单元映射生成网表。接着进行布局布线,生成配置文件和时序报告等信息。当时序能满足约束条件时,就可以利用配置文件进行下载。如果时序不能满足约束,可通过软件报告时序文件来确认关键路径,进行时序优化。可以通过修改约束条件,或者修改rtl代码来满足要求。
需要转换的代码
存储单元
存储单元是必须进行代码转换的,asic中的存储单元通常用代工厂所提供的memory compiler来定制,它可以生成.gsp、.v等文件。.v文件只用来做功能仿真,通常不能综合。而最后流片时,只需将标准提供给代工厂。如果直接将asic代码中的存储单元作为fpga的输入,通常综合器是综合不出来的,即使能综合出来,也要花费很长时间,并且资源消耗多、性能不好。而fpga厂商其实已经提供了经过验证并优化的存储单元。因此存储单元要进行代码转换。
时钟单元
数字电路中,时钟是整个电路最重要、最特殊的信号。在asic中,用布局布线工具来放置时钟树,利用代工厂提供的pll进行时钟设计。fpga中通常已经配置一定数量的pll宏单元,并有针对时钟优化的全局时钟网络,一般是经过fpga的特定全局时钟管脚进入fpga内部,后经过全局时钟buf适配到全局时钟网络的,这样的时钟网络可以保证相同的时钟沿到达芯片内部每一个触发器的延迟时间差异是可以忽略不计的。因此时钟单元也是需要进行转换的。
增加流水
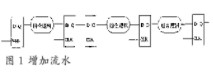
由于实现结构上的不同,fpga器件内部的单元延时远大于asic的基本门单元延时。导致在同样设计的情况下,asic可以满足其时序,而fpga有可能无法满足。为了验证的需要,修改asic代码实现fpga原型时,对asic实现的流水结构在fpga实现时需要适当增加流水。比如在一个很长的组合逻辑路径中加入寄存器。如图1所示。
同步设计
在fpga设计中,同步设计是应该遵循的重要原则。异步设计容易导致电路处于亚稳态,产生毛刺。当从asic设计转向fpga设计时,应该进行仔细的同步。具体体现在主时钟选取、功能模块的统一复位、同步时序电路设计。
在fpga设计中要使用时钟使能代替门控时钟。在asic的设计中,为了减少功耗,使用门控时钟(clock gating),门控时钟的结构如图2所示。当写有效时,数据才写进存储器,那么只有写有效时,寄存器才会发生翻转,这样可以减少功耗。
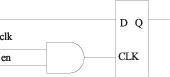
图2 门控时钟示意图
由于设计的异步特性,对于fpga来说,使用这种门控时钟容易产生毛刺,导致数据不正确。所以在fpga设计中,使用有使能信号的电路来替换门控时钟电路。可以在寄存器前面加上mux来实现时钟使能信号,如图3所示。现在的fpga厂商则提供可以直接有使能,同步set和reset引脚的寄存器,如图4所示。

图3 用mux生成时钟使能信号
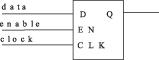
图4 fpga内带有时钟使能的寄存器
充分利用fpga中已有的ip核
fpga厂商及第三方厂商已经实现并优化了很多典型的ip核,例如xilinx提供了基础逻辑、总线接口与i/o、视频与图像处理、数字信号处理、存储器接口、微处理器、控制器等大量ip核。在代码转换时可以充分利用这些资源,对代码进行优化来提高设计性能。如在fpga中使用srl实现移位寄存器,用三态buffer来替换三态总线和三态mux,改进算术单元和有限状态机的编码。
代码转换的实现
结合同济大学微电子中心的“32位高性能嵌入式cpu开发”项目,为了在流片之前确保功能的可靠性,对32位全定制高性能嵌入式cpu bc320进行了原型验证。
设计采用memec design公司的ff1152开发板。该板使用了xilinx的virtex-ⅱ pro系列芯片中的xc2vp30。该fpga拥有30 816个逻辑单元,相当于有30多万的asci门。另有2mb的片上block ram,644个i/o口。采用了xilinx的全自动、完整的集成设计环境ise 7.1i,进行fpga综合使用的工具是synplify pro。
用bc320的asic rtl代码作为fpga的输入,具体的代码转换如下。
存储单元
设计中用到了很多sram,例如icache中的sram。在fpga实现时根据所需ram的宽度、深度和功能来决定采用哪种单元来进行替换。xilinx提供了片外ram、block ram和lut ram。
ise提供了两种具体的实现方法:ip生成器(core generator)和语言模板(language templates)。ip生成器是xilinx fpga设计中的一个重要设计输入工具,它提供了大量xilinx和第三方公司设计的成熟高效ip核。
这里是用core generator来产生了名为块存储器(block memory)的单口存储器模块。core generator用图形化设置参数的方式来提供块存储器,其界面如图5所示。块存储器的大小根据向量的大小来制定,一个普通单元向量只需要4个512×32bit的块存储器就够了。core generator产生块存储器时,除了参数设置外,还需要输入一个为.coe的文件来初始化块存储器的内容。core generator产生的文件同时考虑了后端执行和仿真两方面,主要有三个文件:file.v,file.mif,file.edn。其中.v文件为verilog格式的sram仿真模型; .mif文件为作为其初始化内容,其内容和.coe文件里的具体向量内容是一致的;而实际后端文件为.edn,包含了块存储器的全部信息。
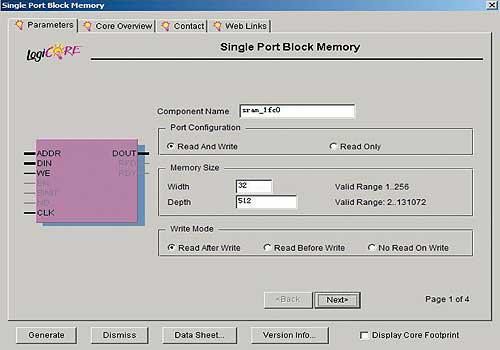
图5 ip生成器的界面
language templates主要利用xilinx的块存储器元件库,直接进行调用。xc2vp30内部的单口块存储器型号主要有:16k×1bit、1k×16bit、2k×8bit、4k×4bit、512×32bit、8k×2bit。可以根据自己的需要随意调用这些模块,在rtl代码中实例化,并把sram初始值作为参数传递进去。这些模块在synplify pro中根据选定的fpga型号被自动识别,然后综合成统一的.edn文件,再进行后续操作。语言模板方式的灵活性比较强,可以设置多个不同位宽,不同深度的块存储器,仿真也比较方便,但是参数设定时,sram初始值的设置比较麻烦。
另外,xilinx提供工具data-mem,它可以每次只改变fpga中块存储器的内容,而不需将整个设计重新翻译、映射和布局布线,为大量的向量验证节约了时间。
时钟单元
在bc320设计中,cpu内核通过sysad接口与外部sram连接。这些外部sram的时钟和主时钟是不一致的,在asic中,用一个pll来实现。这个pll模块是无法用synplify pro综合的,在fpga上必须将它用xilinx的数字时钟管理模块(dcm)来替换。同样可以利用core generator和language templates这两种方法。
利用core generator产生mydcm.v文件来代替原先的pllgs_500.v,代码如下。第二段代码是修改后的代码。
module pllgs_500( pll_k,
pll_m,
pll_n,
pll_pd,
pll_tst,
reset,
xin,
clk_out,
tst_out);
module mydcm(clkin_in,
rst_in,
clkfx_out,
clkin_ibufg_out,
locked_out);
时钟使能带代替门控时钟
把实现门控时钟信号转换成实现使能信号,例如信号pcepl,代码如下。第二段代码是修改后的代码。
module(out,in,clk, pcepl);
……
always @ (clk or pcepl)
assign pceplv = pcepl & clk;
always @(posedge pceplv)
begin
out 《= in;
end
endmodule
module(out,in,clk, pcepl);
……
always @(posedge clk)
begin
if (pcepl)
out 《= in;
else
out 《= out;
end
endmodule
外部器件配置单元和顶层封装
在ff1152开发板上集成了很多接口和器件,在原型验证时,可以充分利用这些接口和器件做为和设计的交互环境。这些接口和器件需要正确配置后才能正常工作,这部分配置工作可以用fpga实现。
设计增加了lcd接口单元、内部记分牌(scoreboard)模块和通用异步串行接收发送(uart)模块。作为保存向量内容的sram设定好后,可以用同样的方法将寄存器参考值也保存在另外的块存储器中。然后运行cpu,将cpu实际产生的寄存器值和已保存过的参考值在记分牌模块中进行实时比较,然后将结果输出到lcd显示屏上。
为了便于代码的管理和维护,可以对原rtl代码进行一定的封装。将原asic流程的代码单独封装在一个模块中,再和fpga实现时添加的片外配置控制单元的代码一起形成新的fpga实现顶层。
所以在asic代码的基础上增加了对这几个器件完成配置工作的代码部分。
为了原型系统获得更高的性能,还可以对其他一些模块的代码进行适当的改进,如算术单元和状态机的编码风格等。但对于全定制的cpu bc320,没有必要修改算术单元模块的代码,关键是存储模块和时钟单元。因此要根据自己的设计适当选择要修改的代码。
-
利用可编程器件CPLD/FPGA实现VGA图像控制器的设计方案2020-08-30 1901
-
现场可编程门阵列有哪些应用?2019-08-06 4146
-
FPGA原型验证的技术进阶之路2020-08-21 4879
-
FPGA可编程器件和CPLD可编程器件有哪些相同点和不同点2021-11-10 3660
-
可编程器件的编程原理是什么?2021-11-30 2239
-
基于可编程器件的任意进制计数器的设计2010-12-29 737
-
DSP器件的现场可编程技术2010-01-07 1186
-
现场可编程门阵列(FPGA)——知识专题2011-09-08 3275
-
EDA技术与可编程ASIC的设计实现2016-05-19 684
-
可编程器件绪论2017-09-19 794
-
电子技术基础知识存储器、复杂可编程器件和现场可编程门阵列的介绍2019-02-22 1449
-
可编程逻辑器件和ASIC对比介绍2020-09-04 3488
-
什么是FPGA原型验证?如何用FPGA对ASIC进行原型验证2023-04-10 2970
-
简单认识现场可编程门阵列2023-12-01 2302
-
可编程器件的特点和发展历程2023-12-21 2418
全部0条评论

快来发表一下你的评论吧 !
