

基于NVIDIA模组与软件套件推动边缘与机器人AI推理
描述
NVIDIA 正式推出 NVIDIA Jetson T4000,将高性能 AI 与实时推理能力带入更广泛的机器人和边缘 AI 应用。T4000 针对更严格的功耗和散热限制进行了优化,最高可提供 1200 FP4 TFLOPs 的 AI 算力和 64 GB 内存,在性能、能效和可扩展性之间实现了理想平衡。凭借高能效设计和量产就绪的形态规格,T4000 让先进 AI 技术更容易被新一代智能机器采用,包括自主机器人、智慧基础设施和工业自动化等应用场景。
该模组集成 1 路 NVENC 和 1 路 NVDEC 硬件视频编解码引擎,支持实时 4K 视频编码与解码。这种均衡设计非常适合需要将先进视觉处理与 I/O 能力相结合、同时又必须满足功耗和散热要求的平台。
| 参数 | NVIDIA Jetson T4000 | NVIDIA Jetson T5000 |
| AI 性能 | 1,200 FP4 稀疏 TFLOPs | 2,070 FP4 稀疏 TFLOPs |
| GPU | 1,536 核 NVIDIA Blackwell 架构 GPU,配备第五代 Tensor Core; 支持多实例 GPU(6 个 TPC) | 2,650 核 NVIDIA Blackwell 架构 GPU,配备第五代 Tensor Core; 支持多实例 GPU(10 个 TPC) |
| 内存 | 64 GB,256-bit LPDDR5x|273 GB/s | 128 GB,256-bit LPDDR5x|273 GB/s |
| CPU | 12 核 Arm Neoverse-V3AE 64 位 CPU | 14 核 Arm Neoverse-V3AE 64 位 CPU |
| 视频编码 | 1x NVENC | 2x NVENC |
| 视频解码 | 1x NVDEC | 2x NVDEC |
| 网络 | 3x 25GbE | 4x 25GbE |
| I/Os | 最多 8 条 PCIe Gen5 通道;5× I2S;1× 音频集线器(AHUB);2× DMI;4× UART;3× SPI;13× I2C;6× PWM 输出 | 最多 8 条 PCIe Gen5 通道;5× I2S;2× 音频集线器(AHUB);2× DMI;4× UART;4× CAN;3× SPI;13× I2C;6× PWM 输出 |
| 功耗 | 40W-70W | 40W-130W |
表 1. Jetson T4000 模组与 Jetson T5000 模组的核心规格
Jetson T4000 模组在外形尺寸和引脚定义上与 NVIDIA Jetson T5000 模组完全兼容。开发者可以为 T4000 和 T5000 设计通用载板,只需在散热和模组固有特性方面考虑差异即可。
NVIDIA Jetson T4000 与 T5000 性能基准测试
Jetson T4000 和 T5000 模组在多种大语言模型(LLM)、文本转语音(TTS)以及视觉-语言-动作(VLA)模型上都表现出色。相比上一代 NVIDIA Jetson AGX Orin 平台,Jetson T4000 的性能最高可提升至 2 倍。下表展示了 T4000 与 T5000 在主流 LLM、TTS 和 VLA 模型上的性能数据。
| 模型家族 | 模型 |
Jetson T4000 (tokens/sec) |
Jetson T5000 (tokens/sec) |
T4000 vs T5000 |
| QWEN | Qwen3-30B-A3B | 218 | 258 | 0.84 |
| QWEN | Qwen 3 32B | 68 | 83 | 0.82 |
| Nemotron | Nemotron 12B | 40 | 61 | 0.66 |
| DeepSeek | DeepSeek R1 Distill Qween 32B | 64 | 82 | 0.78 |
| Mistral | Mistral 3 14B | 100 | 109 | 0.92 |
| Kokoro TTS | Kokoro 82M | 1,100 | 900 | 0.82 |
| GR00T | GR00T N1.5 | 376 | 410 | 0.92 |
表 2. Jetson T4000 与 Jetson T5000 模组的性能基准测试
NVIDIA JetPack 7.1:面向下一代边缘 AI 的先进软件栈
NVIDIA JetPack 7 是目前 Jetson 平台最先进的软件套件,能够为在边缘端部署生成式 AI 和人形机器人提供支持。全新的 Jetson T4000 模组由 JetPack 7.1 驱动,并引入了多项增强 AI 与视频编解码能力的软件新特性。
NVIDIA TensorRT Edge-LLM:提升机器人和边缘系统的推理能力
在 JetPack 7.1 中,NVIDIA 正式为 Jetson Thor 平台引入对 TensorRT Edge-LLM 的支持。
TensorRT Edge-LLM SDK 是一个开源的 C++ SDK,用于在 Jetson 等边缘平台上高效运行 LLM 和视觉语言模型(VLM)。它面向机器人及其他实时系统,这些系统需要现代 LLM 的智能能力,但无法承受数据中心级别的计算、内存和功耗需求。
大多数主流 LLM 技术栈都是围绕云端 GPU 设计的:拥有充足的内存、宽松的时延要求、大量 Python 服务以及弹性扩展作为保障。而机器人和其他边缘设备所面临的约束完全不同——每一毫秒、每一瓦功耗以及运行时行为都会直接影响物理世界中的实际动作。TensorRT Edge-LLM SDK 正是为填补这一差距而设计,它为 Jetson Thor 级别的嵌入式 GPU 提供了面向量产的 LLM 运行时。
在机器人工作负载中,目标不仅仅是“能够运行一个 LLM”,而是要让 LLM 与感知、控制和规划等已经高度占用 GPU 和 CPU 资源的系统协同运行。以边缘为先的设计理念意味着 LLM 运行时需要与现有 C++ 代码库无缝集成,遵循严格的内存预算,并在高负载下提供可预测的时延。
TensorRT Edge-LLM SDK 专注于在边缘端实现 LLM 和 VLM 的快速、高效推理,并与 PyTorch 等主流训练生态保持兼容。典型工作流非常直接:将训练好的模型导出为 ONNX,通过 TensorRT 进行优化,然后在设备端由 SDK 端到端驱动推理引擎运行。
其中一个显著特征在于,该方案以轻量级 C++ 工具包的形式实现,最初针对 NVIDIA DriveOS LLM SDK 中的车载系统进行了优化。相比由大量 Python 包、Web 服务器和后台服务堆叠而成的复杂依赖体系,开发者只需链接一个精简的 C++ 运行时,该运行时可直接与 TensorRT 和 NVIDIA CUDA 进行交互。
与以 Python 为中心的 LLM 框架相比,这种方式为机器人应用带来了多项实际优势,包括:
更低的系统开销:C++ 可执行文件避免了 Python 解释器启动开销、垃圾回收暂停以及 GIL 竞争,更容易满足严格的时延要求。
更易于实时系统集成:C++ 能更直接地控制线程、内存池和调度机制,非常契合实时或准实时的机器人软件架构。
更小的软件体量:更少的依赖使 Jetson 上的部署更简单,容器镜像更小,也让 OTA 更新更加稳健。
量化是提升效率的关键手段之一。该 SDK 支持 FP8、NVFP4 和 INT4 等多种低精度格式,在合理调优的情况下,可在较小精度损失下显著压缩模型权重和 KV-cache 的占用。
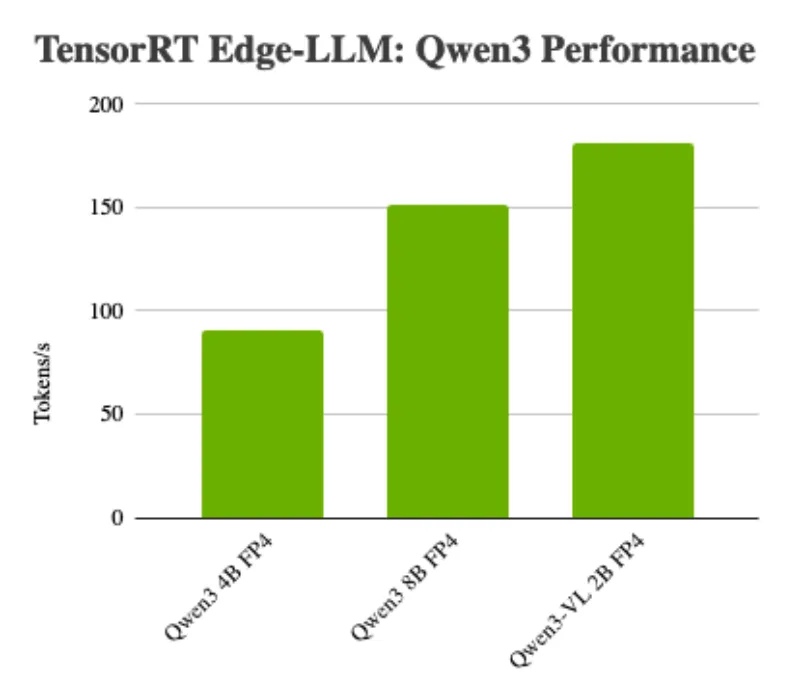
图 1. TensorRT Edge-LLM 在多种 Qwen3 模型上的性能表现
Video Codec SDK:为 Jetson Thor 提供实时感知与媒体处理能力
随着 JetPack 7.1 的发布,NVIDIA Video Codec SDK 现已支持 Jetson Thor。
Video Codec SDK 是一套完整的 API、 高性能工具、示例应用、可复用代码和文档集合,用于在 Jetson Thor 平台上实现硬件加速的视频编码和解码。其核心是 NVENCODE 和 NVDECODE API,提供 C 风格接口,可高效访问 NVENC 和 NVDEC 硬件加速器,暴露绝大多数硬件能力以及常用和高级编解码特性。
为简化集成,SDK 还在这些 API 之上封装了可复用的 C++ 类,使应用能够轻松使用 NVENCODE 或 NVDECODE 接口所提供的完整功能集。
图 2 展示了 JetPack 7.1 BSP 中 Video Codec SDK 及其驱动的整体架构,以及相关的示例应用和文档。

图 2. Video Codec SDK 架构
Video Codec SDK 为多媒体开发者带来以下关键优势。
跨 NVIDIA GPU 的统一开发体验
借助 Video Codec SDK,开发者可以在整个 NVIDIA GPU 产品线上获得一致、简化的开发体验,无需为不同 GPU 类别维护独立的代码库或调优策略,从而降低工程成本。
基于 GPU 的应用可以通过 Video SDK API 无缝扩展或迁移到 Jetson Thor 的集成 GPU 上,而无需重新设计视频处理流程。嵌入式平台团队也能使用与工作站和服务器一致的成熟 API 及工具,并获得相同级别的性能优化。这种一致性不仅加速了开发与验证,还能够让长期维护、系统扩展以及跨平台功能一致性保障更加便利。
对下一代机器人感知与多媒体应用的精细化控制
Video Codec SDK 提供了将预设与调优模式相结合的 API,使开发者能够精确控制视频质量、时延和吞吐量,实现高度灵活的、面向具体应用的编码策略。
通过对重建帧访问和迭代编码的 API 支持,SDK 可实现 CABR 工作流,自动在保证感知质量的前提下找到最低码率,从而降低带宽需求。同时,通过 SDK 暴露的空间/时间自适应量化(AQ)与前瞻控制机制,可以实现细粒度的感知质量优化,将码率精准分配到最重要的区域,从而在不增加码率的前提下获得更清晰、更稳定的视频效果。
Video Codec SDK 主要由两大部分组成:
视频用户态驱动通过 NVENCODE 和 NVDECODE API 访问片上硬件编码器和解码器
Video Codec SDK 13.0 包含示例代码、头文件和文档,可通过 NVIDIA Video Codec SDK 网页,使用 APT(参考操作说明)或 通过 NVIDIA SDK Manager 安装

图 3. Video Codec SDK 的组成
PyNvVideoCodec 是 NVIDIA 提供的 Python 视频编解码库,为 NVIDIA GPU 上的硬件加速视频编码和解码提供了简洁而强大的 Python API。
PyNvVideoCodec 库在内部调用 Video Codec SDK 的核心 C/C++ 编解码接口,同时对外提供易用的 Python API,其性能与直接使用 Video Codec SDK 非常接近。
开始开发
NVIDIA Jetson T4000 拥有成熟的合作伙伴生态,提供量产就绪的系统方案,帮助用户快速从原型阶段过渡到实际部署。开发者可以直接选择经过验证的边缘系统,这些系统已集成模组、电源、散热设计以及机器人和物理 AI 工作负载所需的 I/O。众多合作伙伴的系统充分利用了模组的先进摄像头处理流程,支持 MIPI CSI 和 GMSL,能够处理高要求的多摄像头实时视觉任务。Jetson T4000 提供 16 条 MIPI CSI 通道,使合作伙伴能够打造可同时接入多路摄像头的视频采集平台,支持复杂的机器人、工业检测和自主机器应用。
这些系统均针对 JetPack SDK、CUDA 以及完整的 NVIDIA AI 软件栈进行了优化,现有应用和模型通常只需极少修改即可迁移。众多合作伙伴还提供生命周期支持、区域认证和定制化服务,帮助团队在从试点到规模化部署的过程中降低供应链和合规风险。想要了解可用系统并找到最适合您应用的方案,请访问 NVIDIA 生态系统页面。
总结
借助由 JetPack 7.1 驱动的 Jetson T4000,NVIDIA 将 Blackwell 级 AI 能力、实时推理和先进多媒体功能扩展到更广泛的边缘与机器人应用领域。从在 LLM、语音和 VLA 工作负载上的显著性能提升,到 TensorRT Edge-LLM 的引入以及统一的 Video Codec SDK,T4000 在性能、能效和软件成熟度之间实现了出色平衡。Jetson T4000 使开发者能够在不同性能层级之间灵活扩展,在边缘端构建下一代自主机器、感知系统和物理 AI 解决方案。
关于作者
Shashank Maheshwari 是 NVIDIA Jetson 软件产品经理。他拥有杜克大学 (Duke University)、Fuqua 商学院 (The Fuqua School of Business) 工商管理硕士 (MBA) 学位和工商管理学士 (B.E.) 学位来自 BITS Pilani 的电子产品。
Aayush Pathak 是 NVIDIA 的硬件产品经理,专注于嵌入式边缘和自主机器领域。他在半导体行业拥有丰富的经验,设计过超级计算机 SoC,并致力于开发低功耗、节能的硬件。他拥有南加州大学电气工程硕士学位和芝加哥大学工商管理硕士学位。
Suhas Sheshadri 是 NVIDIA 的产品经理,专注于 Jetson 软件。他以前在NVIDIA 的自主驾驶团队工作,为 NVIDIA 驱动平台优化系统软件。在空闲时间,苏哈斯喜欢阅读量子物理和博弈论方面的书籍。
-
基于 NVIDIA Blackwell 的 Jetson Thor 现已发售,加速通用机器人时代的到来2025-08-26 1419
-
NVIDIA 通过云端至机器人计算平台驱动人形机器人技术,赋能物理 AI2025-05-19 1881
-
盘点#机器人开发平台2025-05-13 1609
-
使用NVIDIA Jetson打造机器人导盲犬2024-11-09 1907
-
使用机器学习和NVIDIA Jetson边缘AI和机器人平台打造机器人导盲犬2024-11-08 1534
-
NVIDIA Jetson还能让AI驱动维修机器人?2023-08-18 1891
-
开发者使用 NVIDIA Jetson 让 AI 驱动维修机器人2023-08-15 1423
-
GTC23 | NVIDIA 扩大 Isaac 软件的接入范围并提高 Jetson 平台的可用性,加快机器人技术从云到边缘的发展2023-03-25 1289
-
NVIDIA AI机器人开发— NVIDIA Isaac Sim入门2022-10-19 3144
-
嵌入式模拟智能为机器人提供了新的自主水平2021-12-20 1262
-
DAC软件套件下载2021-03-23 1201
-
NVIDIA发布AI Enterprise软件套件,助力各行业释放AI潜力2021-03-11 1959
-
NVIDIA构建自主机器统一平台,机器人技术大幅提升2020-03-16 649
-
NVIDIA 在首个AI推理基准测试中大放异彩2019-11-08 4871
全部0条评论

快来发表一下你的评论吧 !
