

DeepSeek开源Engram:让大模型拥有"过目不忘"的类脑记忆
电子说
描述
2026年1月13日凌晨,DeepSeek突然发布由创始人梁文锋署名的新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,并同步开源记忆模块Engram。这一机制通过可扩展查找结构,让大模型实现O(1)时间复杂度的"条件反射式"记忆检索,被业界视为破解Transformer效率瓶颈的关键钥匙。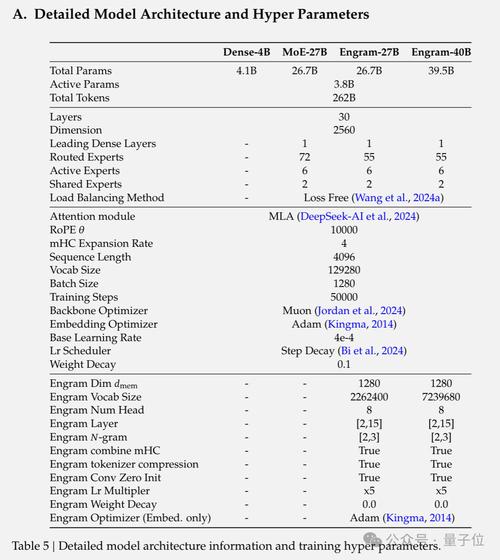
传统Transformer的"记忆困境"
当前大语言模型面临三大结构性问题:注意力计算的O(n²)复杂度在长序列下成为瓶颈;所有知识隐式存储在参数中,检索常识需激活整个网络;早期层负担过重,既要做语义理解又要承担知识检索。这种"低效的反复计算"导致算力浪费,尤其在知识调用、代码补全等需要高频查表的任务中表现突出。
Engram的"双通道记忆"设计
DeepSeek从神经科学汲取灵感:人脑分为程序性记忆(骑自行车)和陈述性记忆(回忆电话号码)。Engram将这一机制映射到模型架构中——条件记忆负责快速查表,注意力负责灵活推理,两者协同构成"稀疏性的新轴"。
技术实现上,Engram采用哈希N-Gram嵌入机制:对输入Token序列进行连续N个词的切片,通过哈希算法映射到可扩展的静态查找表。这种方法是确定性且O(1)时间复杂度的,无论存储多少万亿记忆片段,检索速度恒定,算力消耗极低。同时,轻量化门控机制会根据当前上下文判断是否启用查表结果,避免生硬注入。
实测数据:性能提升超预期
DeepSeek在同等参数和算力条件下进行严格对比测试(均为38亿激活参数,2620亿训练Token):
知识密集型任务 :MMLU提升3分,CMMLU提升4.0分,TriviaQA提升1.9分
通用推理与代码 :BBH大幅提升5.0分,HumanEval代码生成提升3.0分,数学任务MATH提升2.4分
长上下文能力 :Multi-Query NIAH准确率从84.2跃升至97.0,Variable Tracking从77.0提升到89.0
更关键的是,Engram让模型早期层不再做"苦力活",第5层的表征即可达到基线模型第12层的水平,有效深度增加一倍,省下的层数用于更复杂的推理。
行业意义:DeepSeek V4的前奏
梁文锋连续署名两篇论文(mHC架构与Engram),预示DeepSeek V4的技术轮廓日渐清晰。如果说mHC是底层架构创新,Engram则是在架构层面做"分工重构"。这种"存算分离"设计,完美契合算力受限环境下的性价比路线——在同等算力下实现更强性能。
对行业而言,开源Engram的价值在于:它提供了第一个可微分、可训练、原生嵌入模型结构的记忆增强方案,让开发者无需从零构建。从代码补全到医疗知识库,从多语言翻译到法律条文检索,O(1)查找式记忆将为垂直领域大模型带来35-45%的吞吐量提升和25-35%的成本降低。
效率革命的"阳谋"
DeepSeek此举既是技术突破,更是战略卡位。当行业陷入"算力军备竞赛",它选择用架构创新打破硬约束。Engram的巧妙在于不挑战Transformer根基,而是增强其薄弱环节,与MoE形成"计算-记忆"双稀疏,实现1+1>2。
但挑战同样存在:哈希冲突率如何控制?静态记忆表更新机制是否成熟?在创意生成等需要强泛化场景下,Engram是否会产生"记忆固化"副作用?这些都需要大规模实战检验。
Engram的开源,标志着大模型优化从"参数竞赛"转向"架构效率"。当梁文锋将"记忆痕迹"这一神经科学概念注入AI,我们看到的不仅是性能数字的提升,更是中国AI企业在技术路线上从追随到并跑的自信。若DeepSeek V4搭载Engram如期上线,或将证明:在算力受限时代,聪明的架构设计比野蛮的参数量堆砌更具长期价值。这场记忆革命,才刚刚开始。
审核编辑 黄宇
-
教你如何搭建浅层神经网络"Hello world"2020-12-10 1775
-
几种IO口模拟串口"硬核"操作2022-02-10 5983
-
"STM32F0 Error: Flash Download failed - ""Cortex-M0""解决"2021-12-01 5657
-
世界知识产权日|从“白马非马”看开源的知识产权"围城"2022-04-29 1786
-
芯片工艺的"7nm" 、"5nm"到底指什么?2023-07-28 13528
-
全方位精准测量技术助力:中国经济加力发展向前"进"2024-07-15 2608
-
电缆局部放电在线监测:守护电网安全的"黑科技"2025-04-14 1220
-
仓储界的"速效救心丸",Ethercat转PROFINET网关实战案例2025-05-11 1026
-
为什么GNSS/INS组合被誉为导航界的"黄金搭档"?2025-07-09 1337
-
Modbus RTU通讯协议:瑞银电能表的"普通话"指南2025-07-18 2542
-
南柯电子|现场解决EMC电磁辐射干扰:"雷区"让90%的人栽在接地2025-09-25 877
-
"Access violation" 错误,复位位置,重新打印2025-11-08 923
-
选EtherCAT模块,别只看价格,先看"体检报告"2026-02-04 684
-
从"替代人力"到"智能协同":履带式巡检机器人的产业跃迁2026-02-05 570
-
AI 网关:企业 AI 时代的 "智能交通枢纽"—— 六大行业典型场景深度解析2026-06-01 1018
全部0条评论

快来发表一下你的评论吧 !
