

A64指令集通关笔记:加载与存储指令全解析
电子说
描述
作为嵌入式 Linux 开发者,A64 指令集是我们绕不开的基本功。最近我在复习这部分内容时,整理了一份带思考题解答的笔记,希望能帮大家快速掌握核心要点。
开篇:为什么必须啃下A64加载与存储指令这块硬骨头?
作为技术开发者,我们总在追求“更底层、更高效、更可控”的代码能力。A64 指令集的加载与存储指令,正是通往底层系统能力的第一道关卡。这部分知识不是“炫技”,而是解决核心工程问题的必备工具,尤其在嵌入式 Linux、内核开发、性能优化等场景中,直接决定你的代码是否稳定、高效。
知识脑图:A64 加载与存储指令体系
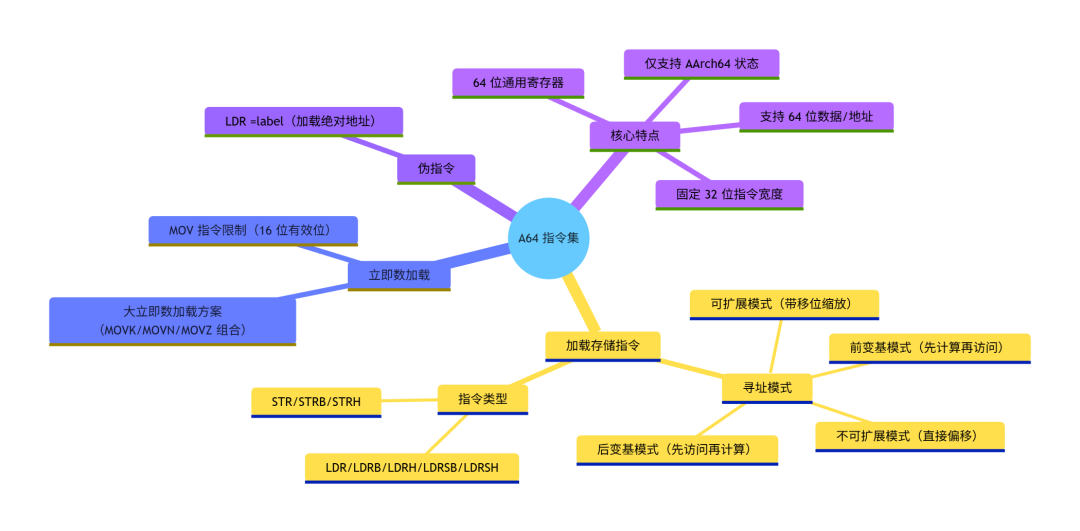
掌握加载与存储指令的核心价值
1.系统稳定性的基石
内核 panic、驱动崩溃、内存访问错误,80% 的底层问题都和加载/存储指令的错误使用有关。比如错误的寻址模式导致的野指针,或者符号扩展错误引发的寄存器值异常,看懂这些指令才能快速定位根因。
2.性能优化的关键抓手
嵌入式系统和高性能计算中,内存访问是性能瓶颈的重灾区。选择正确的寻址模式(如前变基 vs 后变基)、合理使用可扩展模式优化偏移计算,能让内存拷贝、DMA 操作等场景的性能提升 20% 以上。
3.跨平台兼容性的保障
当你的代码需要在 ARMv8 架构的服务器、手机、嵌入式设备间移植时,A64 指令的一致性是核心保障。错误的立即数加载方式或寻址模式,会导致代码在不同设备上表现出诡异的兼容性问题。
4.逆向与安全的必备技能
分析恶意代码、固件漏洞时,加载/存储指令是追踪内存数据流动的关键。比如通过 LDRSB 识别符号扩展漏洞,或通过MOVK 拼接大立即数定位加密密钥的加载逻辑。
哪些开发人员必须掌握这部分知识?
|
开发角色
|
核心场景
|
|
Linux 内核开发者
|
页表操作、中断处理、内存管理子系统,频繁使用加载/存储指令操作物理地址。
|
|
嵌入式驱动工程师
|
外设寄存器访问、DMA 缓冲区操作,必须精准控制内存访问的寻址模式和数据宽度。
|
|
性能优化工程师
|
热点函数的汇编级优化,比如用LDRP/STRP 指令优化多核缓存一致性。
|
|
固件安全研究员
|
分析固件漏洞、逆向恶意代码,通过加载/存储指令追踪内存 corruption 路径。
|
|
编译器/工具链开发者
|
实现 A64 指令的汇编器、反汇编器,需要深入理解指令编码和伪指令转换规则。
|
|
移动端底层开发者
|
Android Kernel、TrustZone 开发,涉及大量特权级内存访问和立即数加载。
|
一句话总结:只要你的代码需要触碰“裸金属”或操作系统内核层,A64 加载与存储指令就是你的“基础设施”。
分享一些常见的知识点:
1. A64 指令集有什么特点?
A64 是 ARMv8 架构的 64 位指令集,核心特点包括:
•纯 64 位执行:只能运行在 AArch64 状态,不兼容 32 位代码。
•固定 32 位指令宽度:编码效率更高,取指和译码更简单。
•64 位通用寄存器:X0-X31 全 64 位,支持 64 位数据和地址操作。
•简化指令格式:移除了复杂的条件执行,让流水线效率更高。
2. 为什么 A64 支持 64 位数据/地址,指令编码却只有 32 位?
这是一个精妙的设计平衡:
•指令宽度固定 32 位:保证指令对齐,提升取指效率,降低硬件复杂度。
•64 位能力通过指令组合实现:例如用MOVZ + MOVK 拼接 64 位立即数,用基址+偏移实现 64 位地址访问。
•编码优化:通过寄存器编号压缩、立即数分段编码等方式,在 32 位空间内高效表达 64 位操作。
3. LDR X0, [X1] 与LDR X0, [X1, #8] 的区别
•LDR X0, [X1]:基址寻址,直接把 X1 寄存器中的地址指向的 64 位数据加载到 X0。
•LDR X0, [X1, #8]:基址+偏移寻址,计算X1 + 8 得到有效地址,再加载该地址的 64 位数据到 X0。
4. 前变基模式 vs 后变基模式
•前变基(Pre-indexed):LDR X0, [X1, #8]!
先计算X1 + 8 得到地址,加载数据到 X0,再把新地址写回 X1。
•后变基(Post-indexed):LDR X0, [X1], #8
先以 X1 的值为地址加载数据到 X0,再计算 X1 + 8 并写回 X1。
一句话记忆:前变基是“先算后用再更新”,后变基是“先用后算再更新”。
5. 这段代码执行后 X0 的值是多少?
my_data:.word 0x40ldr x0, my_data
•.word 0x40 在内存中存储的是 32 位值 0x40。
•LDR 指令默认加载 64 位,会做零扩展,所以 X0 = 0x0000000000000040。
6. 解释这段代码
ldr x0, LABEL_1
•#define 是汇编预处理器宏,把LABEL_1 替换为0x100000。
•LDR X0, LABEL_1 实际是伪指令,会被汇编器转换为合适的指令,将绝对地址0x100000 加载到 X0。
注意:如果直接用MOV X0, 0x100000 会失败,因为 MOV 指令的立即数有效位只有 16 位。
7. 这段代码执行后 X1 和 X2 的值是多少?
my_data:.quad 0x8aldr x5, =my_data // X5 = &my_dataldrb x1, [x5] // 加载1字节,零扩展ldrsb x2, [x5] // 加载1字节,符号扩展
•0x8a 是十六进制,二进制为10001010。
•LDRB 做零扩展:X1 = 0x000000000000008a
•LDRSB 做符号扩展:最高位是 1,所以高位补 1,X2 = 0xffffffffffffff8a
8. 可扩展模式 vs 不可扩展模式
•可扩展(Scaled)模式:偏移量会根据数据宽度自动缩放
例如LDRH X0, [X1, X2, LSL #1],半字加载时偏移量左移 1 位(×2)。
•不可扩展(Unscaled)模式:偏移量直接使用原始值
例如LDR X0, [X1, X2],64 位加载时偏移量不缩放。
9. 哪些 MOV 指令能成功执行?
mov x0, 0x1234 16 位以内mov x0, 0x1abcd 16 位以内mov x0, 0x12bc0000 16 位有效位(0x12bc)左移 16 位mov x0, 0xffff0000ffff 超过 16 位有效位,无法编码
核心规则:MOV 指令的立即数必须能表示为“16 位值 + 任意 16 位倍数的左移”。
10. 如何加载一个很大的立即数到通用寄存器?
对于超过 16 位的立即数,需要用 MOVZ + MOVK 组合加载:
// 加载 0x123456789abcdef0movz x0, 0xef0, lslmovk x0, 0x9abc, lslmovk x0, 0x5678, lslmovk x0, 0x1234, lsl
11. 这条 MOV 指令有什么问题?
mov x0, (1 << 0) | (1 << 2) | (1 << 20) | (1 << 40) | (1 << 55)
•问题:立即数的二进制位分布在 0、2、20、40、55 位,无法用 MOV 指令的“16 位有效位 + 左移”规则编码。
•解决方案:改用MOVZ + MOVK 分多次加载。
12. 这段代码执行后 X0 和 X1 的值是多少?
string1:.string "Booting at EL"ldr x0, string1 // 加载字符串首地址指向的数据(4字节)ldr x1, =string1 // 加载字符串的绝对地址
•X0:加载的是字符串首地址处的 4 字节数据(即字符 'B','o','o','t' 的 ASCII 码)。
•X1:通过伪指令=string1 加载字符串的绝对地址。
13. 这段代码执行后 X0 和 X1 的值是多少?
my_data:.word 0x40ldr x0, my_data // 加载my_data地址的4字节数据ldr x1, =my_data // 加载my_data的绝对地址
•X0:加载的是my_data 存储的值0x40,零扩展为 64 位 → 0x0000000000000040。
•X1:加载的是my_data 这个符号的绝对地址(链接时确定)。
总结
A64 指令集的设计非常注重效率和硬件友好性,32 位固定宽度指令和 64 位操作能力的结合,是理解整个架构的关键。加载与存储指令作为最常用的指令类型,掌握它们的寻址模式和编码规则,能让你在调试汇编代码时事半功倍。
-
Arm A64指令集体系结构2023-08-02 961
-
ARM A64指令集体系结构2022-06-02 991
-
MSP430指令集的相关资料推荐2021-11-29 970
-
PIC16指令集与PIC18指令集相关资料推荐2021-11-24 1612
-
MSP430指令集2021-11-19 1233
-
PIC单片机指令集2021-11-16 1149
-
简单介绍ARM的指令集2020-08-18 3080
-
thumb指令集是什么_thumb指令集与arm指令集的区别2017-11-03 19604
-
9325指令集+初始化2016-01-20 3080
-
芯唐M0指令集2016-01-13 1093
-
ARM和Thumb-2指令集快速参考卡2016-01-12 869
-
ARM和Thumb-2指令集2012-10-26 2582
-
ARMv4指令集模拟器设计及优化技术2009-11-07 718
-
sse5指令集下载2007-12-25 1036
全部0条评论

快来发表一下你的评论吧 !
