

如何基于FFmpeg解码ADPCM音频
描述
在数字音频的浩瀚星图中,ADPCM是⼀颗低调却恒久的星,它诞生于1970年代贝尔实验室的走廊,见证了从电话交换机到 PlayStation 游戏机的沧桑变迁,如今依然在工业控制器的蜂鸣声、监控录像的背景音、老旧 WAV文件的字节流中默默运转;⽽FFmpeg,这位开源音视频领域的"全能管家",正是与ADPCM对话的最佳桥梁。本篇将通过代码和原理,完整拆解ADPCM的编解码魔法。
理解 ADPCM:压缩的哲学
1.1 为什么需要 ADPCM
1980年代,存储介质寸土寸金,一分钟CD音质的PCM音频(44.1kHz/16bit/立体声)需要约10MB空间,这在软盘时代是天文数字;工程师们开始思考:能否只存储"变化",而非"全部"?人类语音和自然声音有一个显著特征:相邻采样点高度相关,前一个样本是1000,下一个大概率在950~1050之间,⽽非跳到30000。ADPCM正是抓住了这个规律。
1.2 ADPCM 的核心思想
ADPCM(Adaptive Differential Pulse Code Modulation,自适应差分脉冲编码调制)的名字藏着三个关键词:
| 关键词 | 含义 |
| Differential(差分) | 不存原始值,只存与预测值的差 |
| Adaptive(自适应) | 量化步长随信号动态调整 |
| Pulse Code(脉冲编码) | 最终输出为离散数字码 |
直观理解:
原始PCM序列: 1000 1050 1080 1120 1100 1060 ... ↓ ↓ ↓ ↓ ↓ ↓ 预测值: (0) 1000 1050 1080 1120 1100 ... ↓ ↓ ↓ ↓ ↓ ↓ 差值: 1000 +50 +30 +40 -20 -40 ... ↓ ↓ ↓ ↓ ↓ ↓ 量化后(4bit): 15 6 4 5 13 12 ... 压缩⽐: 16 bit → 4 bit = 4:1
1.3 ADPCM家族:30种变体的江湖
打开FFmpeg的 libavcodec/adpcm.c,会看到一个庞大的switch-case,这里住着30多位"兄弟姐妹":
ADPCM 家族谱系图 ├── 微软阵营 │ ├── ADPCM_MS ← Windows 系统音频,7组自适应系数 │ └── ADPCM_IMA_WAV ← 更简单,兼容性更好 │ ├── 苹果阵营 │ ├── ADPCM_IMA_QT ← QuickTime 音频 │ └── ADPCM_QT ← 古老的 QuickTime 格式 │ ├── 游戏机阵营 │ ├── ADPCM_XA ← PlayStation CD-ROM │ ├── ADPCM_PSX ← PlayStation 音效 │ ├── ADPCM_THP ← GameCube/Wii 视频 │ ├── ADPCM_DTK ← GameCube 流媒体 │ └── ADPCM_ADX ← CRI Middleware,⼤量日系游戏 │ ├── 电信阵营 │ ├── ADPCM_G722 ← ITU-T 宽带语音,7kHz │ ├── ADPCM_G726 ← ITU-T 窄带语音,16/24/32/40kbps │ └── ADPCM_G726LE ← G.726 小端变体 │ └── 其他 ├── ADPCM_YAMAHA ← 雅马哈音源芯⽚ ├── ADPCM_AICA ← 世嘉 Dreamcast └── ADPCM_CT ← Creative Labs 声卡
好消息:虽然变体众多,但核⼼算法只有两大流派——IMA ADPCM 和 MS ADPCM,掌握这两个,其余触类旁通。
深入原理:从数学到代码
2.1 IMA ADPCM:简洁之美
IMA(Interactive Multimedia Association)ADPCM是最广泛使用的变体。
2.1.1 解码算法可以浓缩为以下公式:
差值 = step × (nibble[2] × 1 + nibble[1] × 0.5 + nibble[0] × 0.25 + 0.125) 如果 nibble[3] == 1,差值取负 新样本 = 旧样本 + 差值 新步⻓索引 = 旧步⻓索引 + index_table[nibble]
2.1.2 步长表89 级的精妙设计
IMA ADPCM使用⼀张固定的 89级步长表,覆盖从7到32767的动态范围:
static const int16_t ima_step_table[89] = {
7, 8, 9, 10, 11, 12, 13, 14,
16, 17, 19, 21, 23, 25, 28, 31,
34, 37, 41, 45, 50, 55, 60, 66,
73, 80, 88, 97, 107, 118, 130, 143,
157, 173, 190, 209, 230, 253, 279, 307,
337, 371, 408, 449, 494, 544, 598, 658,
724, 796, 876, 963, 1060, 1166, 1282, 1411,
1552, 1707, 1878, 2066, 2272, 2499, 2749, 3024,
3327, 3660, 4026, 4428, 4871, 5358, 5894, 6484,
7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899,
15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794,
32767
};
这张表的设计遵循近似指数增长,低索引对应⼩步长(精细量化),高索引对应大步长(粗糙量化),这使得ADPCM能够自动适应:
安静段落 → 小步长 → 高精度
剧烈变化 → 大步长 → 不溢出
2.1.3 索引调整表4 位的智慧
static const int8_t ima_index_table[16] = {
-1, -1, -1, -1, // nibble 0-3:差值小,降低步长
2, 4, 6, 8, // nibble 4-7:差值大,提高步长
-1, -1, -1, -1, // nibble 8-11:负向小差值
2, 4, 6, 8 // nibble 12-15:负向大差值
};
这张表决定了"自适应"特性:
差值小(nibble 0-3, 8-11)→ 索引减小 → 下次用更小步长
差值大(nibble 4-7, 12-15)→ 索引增大 → 下次用更大步长
2.1.4 完整解码实现
/**
* 解码单个 IMA ADPCM 样本
* @param nibble 4位编码值 (0-15)
* @param predictor 预测器状态(输⼊输出)
* @param step_idx 步长索引(输⼊输出)
* @return 16位 PCM 样本
*/
static inline int16_t decode_ima_sample(uint8_t nibble,int32_t *predictor,int32_t *step_idx) {
int step = ima_step_table[*step_idx];
// 核⼼公式:diff = step/8 + step/4*b2 + step/2*b1 + step*b0
// 使用位运算优化,避免浮点
int diff = step >> 3; // step/8,基础值
if (nibble & 4) diff += step; // bit2: +step
if (nibble & 2) diff += step >> 1; // bit1: +step/2
if (nibble & 1) diff += step >> 2; // bit0: +step/4
if (nibble & 8) diff = -diff; // bit3: 符号位
// 更新预测器
*predictor += diff;
// 钳位到 16 位有符号范围
if (*predictor > 32767) *predictor = 32767;
if (*predictor < -32768) *predictor = -32768;
// 更新步长索引
*step_idx += ima_index_table[nibble];
if (*step_idx < 0) *step_idx = 0;
if (*step_idx > 88) *step_idx = 88;
return (int16_t)*predictor;
}
2.2 MS ADPCM:微软的增强版
2.2.1 Microsoft ADPCM比IMA更复杂,但理论上能获得更好的音质
| 特性 | IMA ADPCM | MS ADPCM |
| 预测器 | 1个历史值 | 2个历史值 |
| 系数 | 固定 | 7组自适应系数 |
| WAV格式码 | 0x0011 | 0x0002 |
| 块头大⼩ | 4字节/声道 | 7字节/声道 |
2.2.2 MS ADPCM的预测公式
predictor = (sample1 * coef1 + sample2 * coef2) / 256 output = predictor + (nibble * delta)
2.2.3 7组自适应系数
static const int16_t ms_adapt_coef1[7] = { 256, 512, 0, 192, 240, 460, 392 };
static const int16_t ms_adapt_coef2[7] = { 0,-256, 0, 64, 0,-208,-232 };
编码器会为每个块选择最佳系数组,存储在块头中。
2.2.4 Delta自适应表
static const int16_t ms_adapt_table[16] = {
230, 230, 230, 230, 307, 409, 512, 614,
768, 614, 512, 409, 307, 230, 230, 230
};
// 更新公式
new_delta = (delta * ms_adapt_table[nibble]) / 256;
if (new_delta < 16) new_delta = 16; // 最小值保护
FFmpeg实战:完整解码流程
3.1 解码流程图

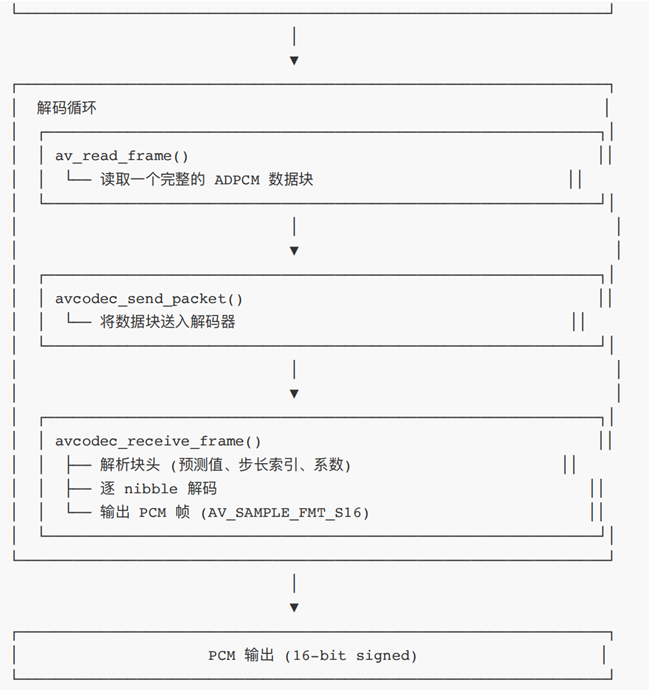
3.2 代码示例如下:
依赖的头文件
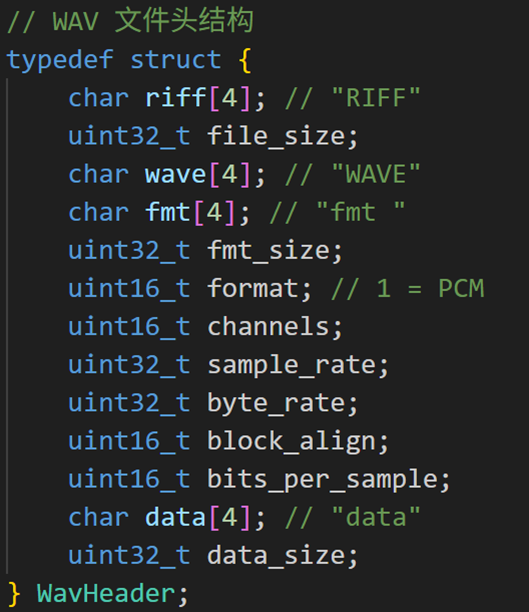
WAV文件头
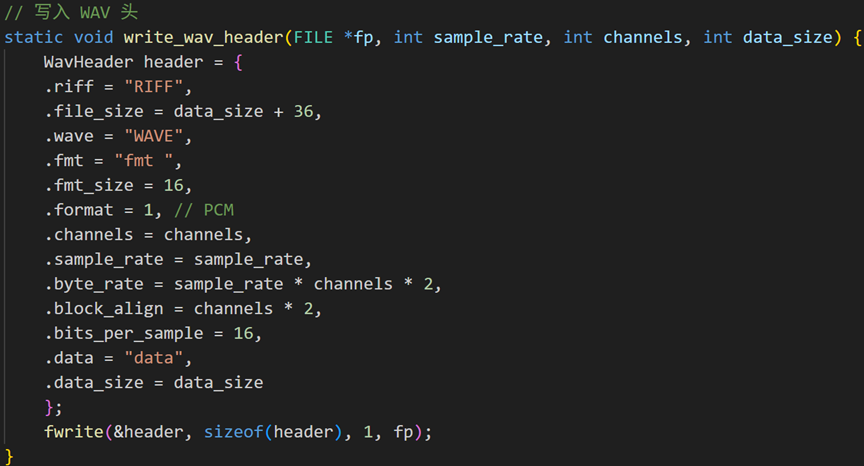
循环解码
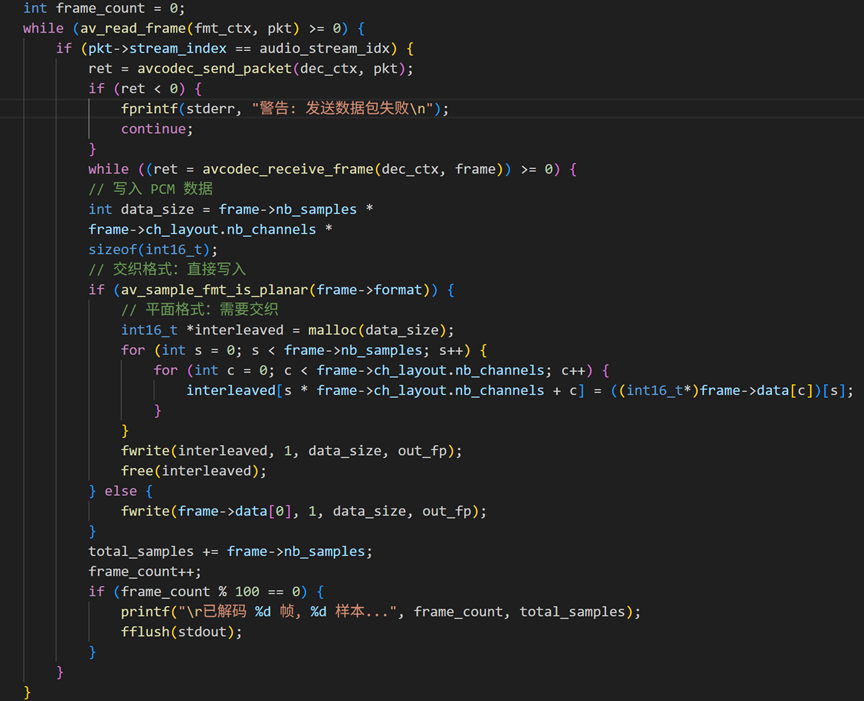
3.3 编译与运行
# 编译 gcc -o adpcm_decode adpcm_decode.c $(pkg-config --cflags --libs libavformat libavcodec libavutil) # 运行 ./adpcm_decode input_adpcm.wav output_pcm.wav # 输出示例: # ====== 文件信息 ====== # 格式: WAV / WAVE (Waveform Audio) # 时长: 5.23 秒 # 流数量: 1 # # ====== 音频参数 ====== # 编码格式: adpcm_ima_wav (ID: 69638) # 采样率: 44100 Hz # 声道数: 2 # 块对齐: 2048 字节 # ⽐特率: 352800 bps # 解码器: ADPCM IMA WAV # # ====== 开始解码 ====== # 已解码 100 帧, 204800 样本... # # ====== 解码完成 ====== # 总帧数: 113 # 总样本: 230912 # 输出⼤⼩: 901.22 KB # 输出⽂件: output_pcm.wav
深度避坑:那些"诡异问题"的根源
4.1 坑一:MS ADPCM和IMA ADPCM混淆
问题:解码后听到刺耳噪音或沉默。
原因:两种格式虽然都叫 ADPCM,但块结构完全不同。
诊断方法:
# 使⽤ ffprobe ffprobe -v quiet -select_streams a:0 -show_entries stream=codec_name input.wav # 或用 hexdump 直接看 hexdump -C input.wav | head -2 # 查看偏移 20-21 字节: # 0x0002 = MS ADPCM # 0x0011 = IMA ADPCM
解决方案:让 FFmpeg 自动识别,不要手动指定 codec_id。
4.2 坑二:块对齐(Block Align)错误
问题:解码正常但周期性出现噪音。
原因:ADPCM数据必须按块读取,每个块以状态信息开头,如果在块中间切断,状态会丢失。
诊断方法:
# 查看块对齐值 ffprobe -v quiet -select_streams a:0 -show_entries stream=block_align input.wav
正确做法:
// 确保每次读取完整的块
if (pkt->size % par->block_align != 0) {
fprintf(stderr, "警告: 数据包⼤⼩ (%d) 不是块对⻬ (%d) 的整数倍
",
pkt->size, par->block_align);
}
4.3 坑三:立体声声道错乱
问题:左右声道交换,或声音"撕裂"。
原因:IMA 和 MS ADPCM 的⽴体声交织方式不同:
IMA ADPCM ⽴体声交织: 块内: [L头][R头] [L样本组(8个)] [R样本组(8个)] [L组] [R组] ... MS ADPCM ⽴体声交织: 块内: [L头][R头] [LR] [LR] [LR] ... (每个nibble交替)
解决方案:使用 FFmpeg 的自动处理,它会正确解交织。
4.4 坑四:文件被截断
问题:解码到末尾时崩溃或输出噪音。
原因:某些录音软件在异常终止时未正确写⼊文件尾。
诊断方法:
# 检查⽂件完整性 ffprobe -v error input.wav # 如果有错误会输出
解决方案:
// 在解码器中启用错误容忍 dec_ctx->err_recognition = AV_EF_CAREFUL; // 或 AV_EF_IGNORE_ERR // 或用FFmpeg命令⾏修复 // ffmpeg -i broken.wav -c copy fixed.wav
4.5 坑五:采样率/声道数信息缺失
问题:FFmpeg 报告nvalid data found when processing input。
原因:某些非标准工具生成的 WAV文件fmt块不完整。
解决方案:手动指定参数:
// 强制指定采样率和声道数 av_dict_set(&options, "sample_rate", "44100", 0); av_dict_set(&options, "channels", "2", 0); avformat_open_input(&fmt_ctx, input_path, NULL, &options);
性能优化:让古老格式飞起来
5.1 性能基准
在典型的开发环境中(Intel i5/Apple M1 级别):
ADPCM解码是计算轻量型任务,瓶颈通常在I/O而非CPU。
| 配置 | 解码速度 | 实时倍率 | CPU占用 |
| FFmpeg单线程 | ~180,000样本/ms | ~4000x | ~3% |
| 纯C手写实现 | ~220,000样本/ms | ~5000x | ~2% |
5.2 优化策略
策略一:增大读取缓冲区。
// 默认缓冲区可能较⼩,增大可减少系统调用 AVDictionary *options = NULL; av_dict_set(&options, "buffer_size", "1048576", 0); // 1MB avformat_open_input(&fmt_ctx, path, NULL, &options);
策略二:跳过不需要的帧。
// 如果只需要某个时间段 av_seek_frame(fmt_ctx, audio_stream_idx, target_pts, AVSEEK_FLAG_BACKWARD);
策略三:使用SIMD加速。
对于需要极致性能的场景,可以使用SSE/NEON指令集批量处理多个样本:
// 伪代码示意 #include// ⼀次处理 8 个样本 __m256i step_vec = _mm256_set1_epi32(step); __m256i diff_vec = _mm256_srai_epi32(step_vec, 3); // step >> 3 // ... 后续 SIMD 运算
调试技巧:当声音"沉默"时
6.1 启用FFmpeg详细日志
av_log_set_level(AV_LOG_VERBOSE); // 或只看特定级别 av_log_set_level(AV_LOG_WARNING);
6.2 命令行快速诊断
#查看完整流信息 ffprobe -v quiet -print_format json -show_format -show_streams input.wav #解码第⼀秒并检查 ffmpeg -i input.wav -t 1 -f s16le -acodec pcm_s16le - | hexdump -C | head #⽣成波形图 ffmpeg -i input.wav -filter_complex "showwavespic=s=800x200" waveform.png #对⽐两个⽂件的频谱 ffmpeg -i original.wav -i decoded.wav -filter_complex "[0:a]showspectrumpic=s=800x400[s0];[1:a]showspectrumpic=s=800x400[s1];[s0] [s1]vstack" spectrum_compare.png
6.3 自检清单
当解码出现问题时,按顺序检查:
□ ⽂件是否完整?(⽂件大小是否合理) □ 格式是否正确识别?(ffprobe codec_name) □ 采样率/声道数是否正确? □ 块对齐是否正确? □ 是否有 DRM 保护? □ 是否使⽤了非标准扩展? □ 解码器是否正确初始化? □ 输出格式是否正确处理?(平面 vs 交织)
结语:技术,是时间的译者
每一段ADPCM音频背后,可能是90年代游戏厅的喧嚣、老式答录机的留言、工厂车间的运转声,用4位的密度,记录着16位的时光。通过FFmpeg解码,不只是波形数据,更是一段段被压缩却未曾遗忘的记忆。ADPCM的伟大,在于它用极简的算法,在那个存储金贵的年代,让声音得以保存和传递。而今天仍在使用和研究它,这是对这份工程智慧的致敬。当调用avcodec_receive_frame的那一刻,当predictor加上diff的那一瞬,一段1980年代的声音,正穿越40年的时光,完整地回到耳畔。
供稿:闫超美
责编:开发者与活动运营组 李健
编审:品牌管理组 丽娜
审核:开源鸿蒙项目群工作委员会执行总监 陶铭
开源鸿蒙项目群工作委员会执行秘书 曹云菲
-
瑞芯微RK3562平台FFmpeg硬件编解码移植及性能测试实战攻略2025-11-28 1787
-
瑞芯微RK3588平台FFmpeg硬件编解码移植及性能测试实战攻略2025-10-21 2480
-
FFmpeg 6.0 发布2023-03-06 2053
-
Linux下基于ffmpeg音视频解码2022-09-29 5433
-
在QT上构建ffmpeg环境实现音频的解码2022-06-09 1946
-
如何去设计ADPCM语音编解码电路?2021-05-06 1285
-
如何使用L9320实现ADPCM语音编解码2019-12-20 1576
-
FFmpeg硬解码2019-11-20 3172
-
基于FPGA验证所设计的ADPCM算法语音编解码电路2019-07-02 4227
-
基于STM8的ADPCM音频解码输出DAC语音的程序源码2018-01-24 2482
-
【NXP LPC54110试用体验】ADPCM音频压缩2017-10-14 6170
-
振南对ADPCM音频编解码原理的一些通俗阐述【附振南的ADPCM解码原代码】2016-06-17 6988
-
ADPCM语音编解码VLSI芯片的设计方法2010-09-03 3044
全部0条评论

快来发表一下你的评论吧 !
