

推理<2ms!Ultralytics最新YOLO26+树莓派+国产AI加速卡实现 500 FPS 端侧 AI 性能巅峰!
描述
关键词:YOLO26、树莓派、国产AI加速卡、M5Stack、边缘AI
速度快、功耗低、纯国产,树莓派终于有了真正实用的 AI 加速方案
近年来,随着 AI 技术的爆发式发展,边缘智能设备正成为行业布局的重点。从工业质检到智能安防,从机器人视觉到车载感知,AI 模型正快速从“云端”走向“终端”。然而,边缘设备往往受限于计算资源与功耗,如何在有限资源下实现高效、实时的 AI 推理,一直是技术落地的关键挑战。
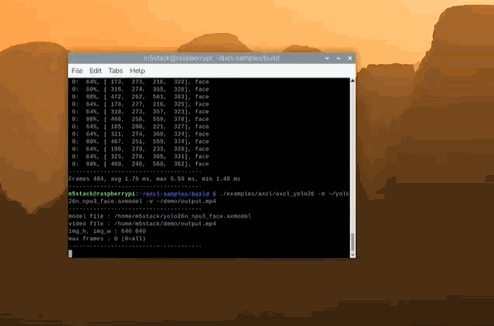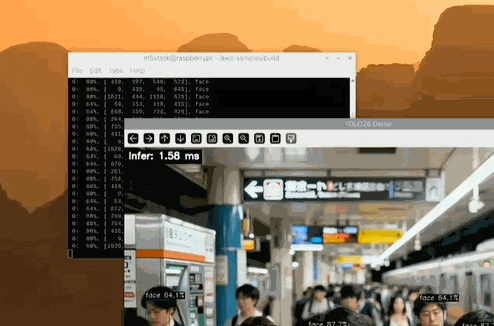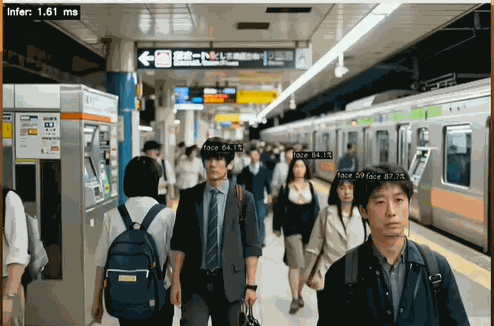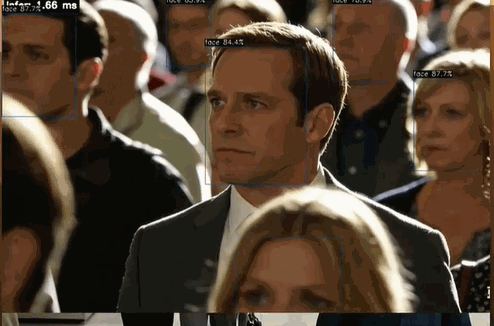
左上角可以清晰看到 Infer 时间 < 2ms
- Ultralytics 最新 YOLO26 +树莓派+国产AI 加速卡实现 500 FPS 端侧 AI 性能巅峰!
- 代码:https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
- 模型:https://huggingface.co/AXERA-TECH/yolo26
- 文档:https://docs.m5stack.com/zh_CN/ai_hardware/LLM-8850_Card
- 4000 字,阅读 13 分钟,播客 14 分钟
相关推荐
- 让手机CPU,GPU,NPU协同!浙大端侧AI“超级记忆”AME硬件感知引擎:7倍索引加速,6倍插入提速,隐私与速度兼得!
- 小语言模型量化基准体系 SLMQuant:8 位近无损与 W4A8 低比特效能研究
- HeteroLLM:利用移动端 SoC 实现 NPU-GPU 并行异构 LLM 推理!以 高通8 Gen 3的NPU GPU为例
今天,我们为大家带来一套纯国产、高性能、易部署的边缘 AI 解决方案:M5Stack LLM-8850-Card(国产 AI 加速卡) 与 Ultralytics YOLO26n(新一代端侧检测模型) 的强强组合,让树莓派等低成本开发板也能轻松实现 < 2 ms 级目标检测。

左上角可以清晰看到 Infer 时间 < 2ms
相比树莓派单靠 CPU 运行 YOLO26n 模型,性能提升达几十到几百倍:
| 运行环境 | 模型 | 运行时间 | 备注 |
|---|---|---|---|
| ncnn | yolo26n(输入尺寸640) | 63.30 ms | CPU 4线程 |
| pytorch | yolo26n(输入尺寸640) | 288.6 ms | CPU,Ultralytics框架 |
| onnx | yolo26n(输入尺寸640) | 133~142 ms | CPU,Ultralytics框架 |
| axmodel | yolo26n(输入尺寸640) | 1.5~1.6 ms | 国产AI加速卡LLM8850 |
本文目录unsetunset
- 一、YOLO26n:为边缘而生的新一代检测模型
- 二、M5Stack LLM-8850-Card:树莓派 AI“小钢炮”
- 2.1 硬件参数
- 2.2 NPU 工具链与软件生态
- 2.3 部分模型 benchmark:视觉、LLM、VLM 模型
- 三、实战:在树莓派+LLM-8850 上跑通 YOLO26n
- 3.1 实现步骤:核心代码讲解
- 3.2 编译与运行
- 四、性能实测:推理< 2ms,帧率高达 500+FPS
- 总结:国产边缘 AI 生态正当时
交流加群请在 NeuralTalk 公众号后台回复:加群
unsetunset一、YOLO26n:为边缘而生的新一代检测模型unsetunset
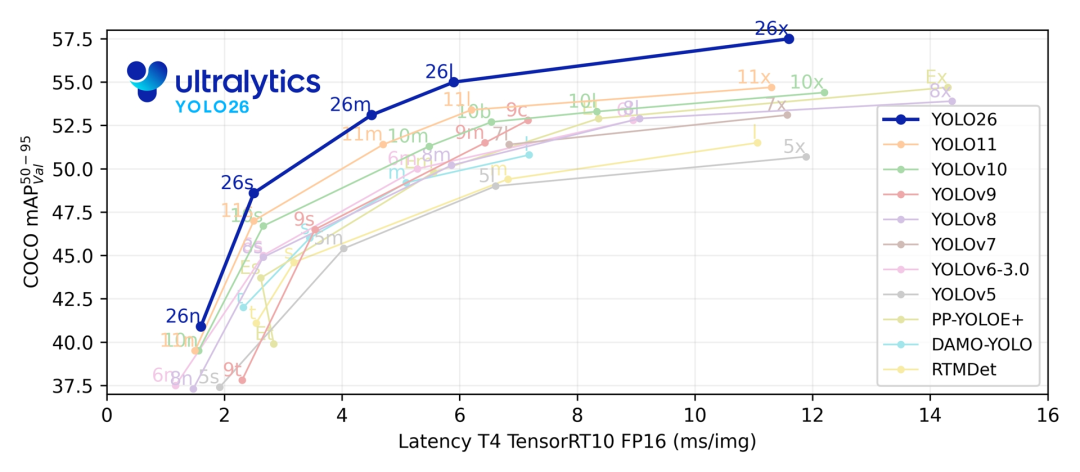 Ultralytics YOLO26 与系列前代模型的性能对比可视化。聚焦精度、推理速度、硬件适配性等核心维度。直观呈现 YOLO26 在移除 DFL 模块、采用 MuSGD 优化器后,于边缘设备场景下的优势
Ultralytics YOLO26 与系列前代模型的性能对比可视化。聚焦精度、推理速度、硬件适配性等核心维度。直观呈现 YOLO26 在移除 DFL 模块、采用 MuSGD 优化器后,于边缘设备场景下的优势
YOLO26 是 Ultralytics 在 2026 年发布的最新版本[1],专为边缘与低功耗设备优化设计。其核心特点包括:
- 端到端无 NMS 推理:首次实现真正的端到端预测,无需后处理中的非极大值抑制(NMS),大幅简化部署流程、降低延迟,提升系统稳定性。
- 去除 DFL 模块:移除了传统的分布焦点损失(DFL),提升模型导出兼容性,更适合各类边缘硬件部署。
- CPU 推理性能大幅提升:相比前代,YOLO26 在 CPU 上的推理速度提升最高达 43%,为无 GPU 的设备带来实时的 AI 处理能力。
- 支持多任务统一架构:一个模型家族覆盖检测、分割、分类、姿态估计、旋转框检测五大任务,极大简化开发与维护成本。
下面表格展示了 YOLO26 系列 5 个不同规模模型在 COCO 目标检测数据集上的核心性能指标,清晰呈现了模型精度、推理速度、参数量和计算量的权衡关系,为不同部署场景的模型选型提供依据。
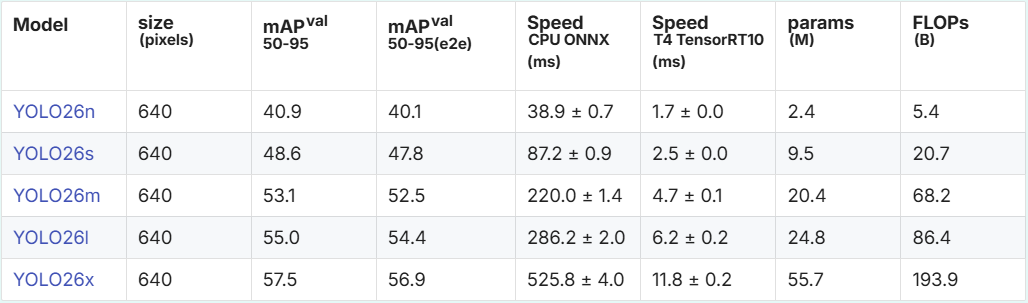
本次我们重点使用的是其最小尺寸版本——YOLO26n,其模型参数仅 2.4M,在 COCO 数据集上仍能实现 40.9% 的 mAP,是边缘设备上平衡精度与速度的理想选择。
unsetunset二、M5Stack LLM-8850-Card:树莓派 AI“小钢炮”unsetunset
尽管树莓派等开发板生态丰富、用户基数庞大,但其本身缺乏专用的 NPU(神经网络处理单元),依赖 CPU 进行 AI 推理往往速度慢、占用率高,难以满足实时性要求。虽然树莓派官方有 Hailo 等加速方案,但多为国外芯片,国内开发者面临采购与技术支持的不便。
2.1 硬件参数

在此背景下,深圳 M5Stack 基于爱芯元智(AXERA) AX8850 国产 AI SoC,精心打造了一款 M.2 M-KEY 2242 形态的 AI 加速卡——LLM-8850-Card,堪称树莓派 AI“小钢炮”。
 LLM‑8850Card 是一款面向边缘设备的 M.2 M-KEY 2242 AI 加速卡,把 42mm 的袖珍体积与 Axera AX8850 SoC 的 24 TOPS@INT8 算力结合起来,为 Raspberry Pi 5、RK3588 SBCs、x86 PC 等主机 “一插即强” 地扩展多模态大模型与视频分析能力
LLM‑8850Card 是一款面向边缘设备的 M.2 M-KEY 2242 AI 加速卡,把 42mm 的袖珍体积与 Axera AX8850 SoC 的 24 TOPS@INT8 算力结合起来,为 Raspberry Pi 5、RK3588 SBCs、x86 PC 等主机 “一插即强” 地扩展多模态大模型与视频分析能力
这款计算模块在性能与体积上实现了完美平衡:
- 它搭载了 AX8850 芯片,集成八核 Cortex-A55 CPU 并提供高达 24 TOPS @ INT8 的 NPU 算力,同时配备 8GB LPDDR4x 大内存,为多模型、多任务并行提供了充足的带宽与强劲算力支持。
- 在多媒体处理方面,该模块集成了强大的硬件视频引擎,支持 8K H.264/H.265 编解码,可同时处理 16 路 1080p 视频流,从而实现“视频+AI”的一站式高效处理。

尽管性能强大,其体积却极为小巧精悍 42.6 × 24.0 × 9.7 mm,采用 M.2 2242 标准尺寸,可直接插入树莓派 5、RK3588 等开发板的 M.2 接口,真正做到即插即用;为了确保长时间满载运行的稳定性,模块还内置了微型涡轮风扇与铝合金一体化散热片,并由板载 EC 智能温控系统进行精准调节。
2.2 NPU 工具链与软件生态
Pulsar2 由爱芯元智自主研发 的 all-in-one 新一代神经网络编译器[2],即转换、 量化、 编译、 异构 四合一,实现深度学习神经网络模型 快速、 高效 的部署需求。
针对 NPU 特性进行了深度定制优化,充分发挥片上异构计算单元(CPU+NPU)算力, 提升神经网络模型的产品部署效率。
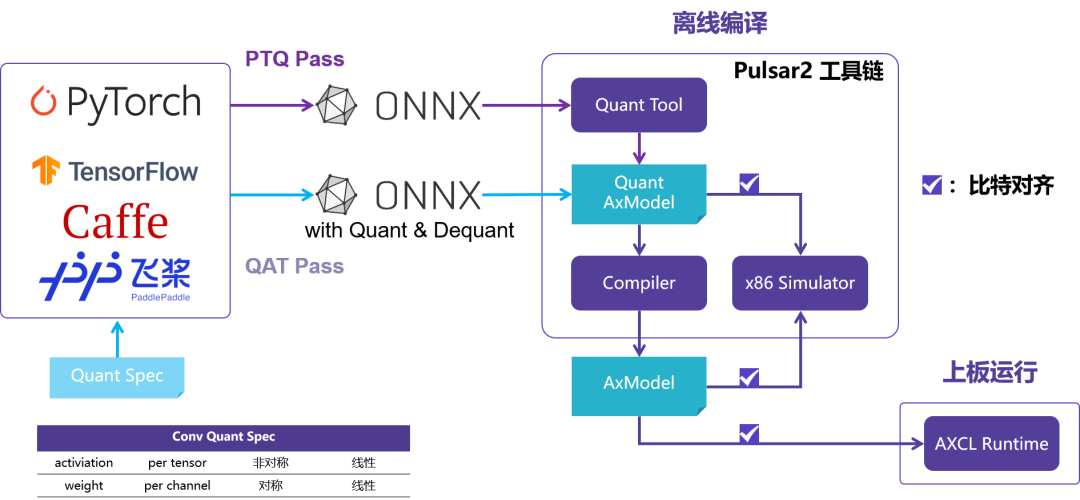 Pulsar2 NPU 工具链从模型量化到部署全流程:从 PyTorch/TensorFlow 等框架导出 ONNX 模型,经 Pulsar2 工具链量化、编译,生成 AxModel,经比特对齐验证后,通过 AXCL Runtime 在上板运行
Pulsar2 NPU 工具链从模型量化到部署全流程:从 PyTorch/TensorFlow 等框架导出 ONNX 模型,经 Pulsar2 工具链量化、编译,生成 AxModel,经比特对齐验证后,通过 AXCL Runtime 在上板运行
而 AXCL[3] 是用于在 AXERA 芯片平台上开发深度神经网络推理、转码等应用的 C、Python 语言 API 库。其能力提供运行资源管理,内存管理,模型加载和执行,媒体数据处理等 API。
在软件生态上,基于完善的 AXCL Runtime[4]能力,其不仅支持 C / Python API,更已集成对 YOLO 系列、CLIP、Whisper、Llama3.2、InternVL3、Qwen3 等主流 CNN、Transformer、LLM 与多模态模型的一键部署能力,极大地降低了开发门槛。
2.3 部分模型 benchmark:视觉、LLM、VLM 模型
下面是部分视觉、LLM、VLM 模型 benchmark 数据,更多数据见 benchmark[5]:
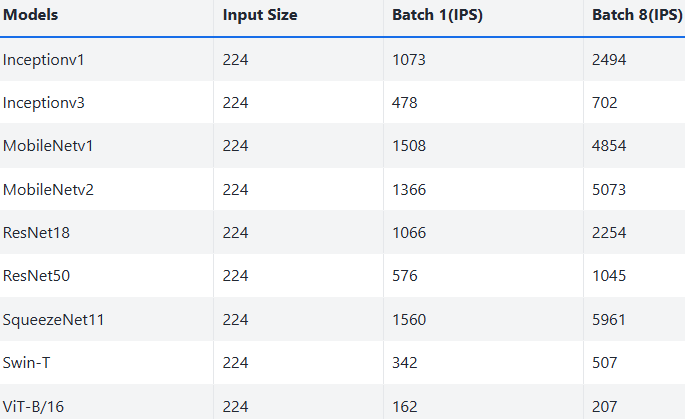
Vision 模型在 NPU 上的推理性能测试表,IPS 是每秒处理图像数(Images Per Second),是衡量计算机视觉(CV)模型推理速度和吞吐量的核心指标
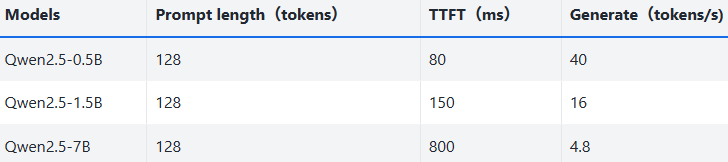
LLM 模型在 NPU 上的性能测试表,展示 Qwen2.5 系列(0.5B/1.5B/7B)在 128 tokens 提示下的表现:TTFT 是首次 token 生成延迟(数值越小越快),Generate 是持续生成速度(数值越大越快),模型参数量越大,性能通常越低
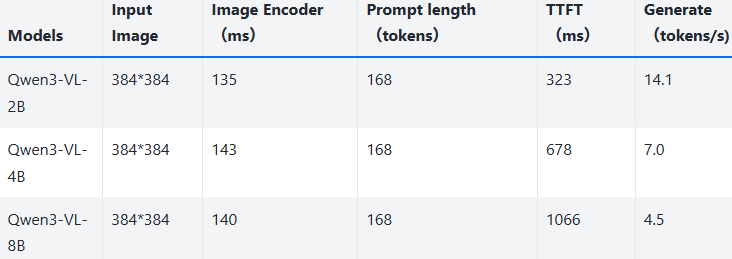
Qwen3-VL 多模态模型的 NPU 性能测试表,展示 2B/4B/8B 参数量版本的表现:输入图像规格均为 384*384,提示词长度 168 tokens;参数量越大,图像编码器耗时、首次 token 生成延迟(TTFT)越高,持续生成速度(tokens/s)越低
unsetunset三、实战:在树莓派+LLM-8850 上跑通 YOLO26nunsetunset
目前,爱芯元智官方已在开源仓库 axcl-samples[6] 中提供了 YOLO26 在 AX8850 平台上的完整 C++ 示例代码,并已将预训练模型发布在 HuggingFace[7] 上。
3.1 实现步骤:核心代码讲解
以下是基于 ax_yolo26_steps.cc 的核心实现步骤解析如下:
原始图像 → Letterbox缩放 → RGB转换 → 设备内存 → NPU推理
↑ ↓
保存结果 ← 绘制框 ← 坐标映射 ← 多尺度解析
- 步骤一:读图
- 使用OpenCV的cv::imread,默认BGR格式,保持原始分辨率
- 代码中检查了图像是否为空,有错误处理
- 步骤二:Letterbox 预处理
- 关键算法:保持长宽比的缩放,不足部分填充灰色
- 数据排布:转换为HWC格式的RGB连续内存
- 优化:避免了不必要的内存拷贝,直接操作原始数据
- 步骤三:设备初始化
- 禁用虚拟NPU,使用物理NPU
- 只初始化一次,后续可重复使用
- 步骤四:模型加载与输入
- 模型格式:.axmodel 是 AXera 平台专有的优化模型格式
- 预热:5 次预热推理,避免首次推理的冷启动延迟
- 步骤五:推理过程。输出结构为:6个tensor = 3个尺度 × (box + cls)
- box: 4个值(x, y, w, h)或者(x1, y1, x2, y2)
- cls: 80个类别的置信度
- 计时:精确记录每次推理时间,用于性能分析
- 步骤六:后处理,generate_proposals_yolo26() → 坐标映射 → 绘制
- 坐标转换:从 640×640 的 letterbox 坐标映射回原始图像坐标
- 多尺度融合:3个尺度(80×80, 40×40, 20×20)分别处理后合并
- 可视化:不同类别用不同颜色,显示类别名和置信度
通过 “读图 → Letterbox → 上电 → 喂模型 → 推理 → 后处理”这 6 步,就把整个 AXCL-YOLO 流程串起来了。完整代码见examples/ax650/ax_yolo26_steps.cc[8]。
3.2 编译与运行
了解了执行流程,下面先给出我们编译 axcl-samples[9] 和推理图片的视频,性能结果包含推理时间,后处理时间等,最后会有推理结果展示。
为了方便大家复制粘贴,下面给出视频中用到的脚本和相关文件如模型、图片等。
1. 编译 axcl-sample
git clone https://github.com/Abandon-ht/axcl-samples.git
cd axcl-samples
mkdir build
cd build/
cmake ..
make -j4
2. 输入图片并执行推理
# 拉取代码仓库
wget -c https://github.com/Abandon-ht/YOLO26.axera/releases/download/v0.2/bus.jpg
# 下载 yolo26n 模型
wget -c https://github.com/Abandon-ht/YOLO26.axera/releases/download/v0.2/yolo26n_npu3_new.axmodel
# 执行推理
./examples/axcl/axcl_yolo26 -m yolo26n_npu3_new.axmodel -i bus.jpg
上面最后一行命令会执行推理,如下所示:

检测结果如下图所示:

检测结果为 1.59 ms,执行日志详情如下:

unsetunset四、性能实测:推理< 2ms,帧率高达 500+FPSunsetunset
作为性能实测的对比,下面是树莓派 CPU A76 运行 yolo26n 的性能数据:
| 运行环境 | 模型 | 运行时间 | 备注 |
|---|---|---|---|
| ncnn | yolo26n(输入尺寸640) | 63.30 ms | CPU 4线程 |
| pytorch | yolo26n(输入尺寸640) | 288.6 ms | CPU, Ultralytics框架 |
| onnx | yolo26n(输入尺寸640) | 133~142 ms | CPU,Ultralytics框架 |
| axmodel | yolo26n(输入尺寸640) | 1.5~1.6 ms | 国产AI加速卡LLM8850 |
将代码从图片检测修改为视频检测,即图片输入改成摄像头读取输入。cv::imwrite改成cv::show效果如下:
左上角可以清晰看到 Infer 时间 < 2ms

左上角 Infer 时间在 1.60 ms 左右
unset
结合根据社区实测与官方示例数据,在 M5Stack LLM-8850-Card + YOLO26n 组合下:
- 单帧推理时间(含前后处理)可稳定在 2 毫秒以内。
- 相当于 500+ FPS 的超高帧率,足以应对绝大多数实时视频流分析场景。
- 相比树莓派单靠 CPU 多线程运行 YOLO26n 模型,性能提升相比 CPU 多线程达几十到几百倍,且 CPU 占用率大幅降低。
完整实测视频如下
注:左上角为推理时间,需要说明的是,在远程桌面 + Raspberry Pi 这种场景下,推理时间比观察到的 FPS 更可靠,原因如下:
- 显示瓶颈不影响推理时间:远程桌面传输和屏幕渲染可能成为瓶颈(比如只能达到 60 FPS),但这不代表模型本身慢
- 推理时间能准确反映 "预处理→推理→后处理" 的真实计算耗时
综合上面性能表现,使得树莓派这类低成本、高普及率的开发板,真正具备了部署实时多路视频 AI 分析的能力,可广泛应用于:
- 智能安防:人脸识别、行为分析、车牌识别。
- 工业视觉:零件质检、缺陷检测、流水线监控。
- 机器人:实时环境感知、自主导航、手势交互。
- 教育与创客:低门槛的 AI 项目开发与原型验证。
unsetunset总结:国产边缘 AI 生态正当时unsetunset
M5Stack LLM-8850-Card 与 YOLO26n 的组合,不仅为树莓派用户提供了一个高性能、易用的 AI 加速方案,更展现了国产芯片与开源算法在边缘计算领域的深度融合与快速落地能力。
对于开发者而言,这意味着:
- 更低的门槛:无需复杂硬件设计,插卡即用。
- 更高的性能:毫秒级推理,满足实时性要求。
- 更优的成本:国产方案性价比突出,供货稳定。
- 更全的生态:从芯片、硬件到算法、示例[10],全栈开源支持。
目前,相关代码、模型与文档均已开源,欢迎开发者前往以下链接获取资源,亲手体验这款“国产小钢炮”带来的边缘 AI 加速魅力:
- 代码仓库:https://github.com/AXERA-TECH/ax-samples[11]
- 模型下载:https://huggingface.co/AXERA-TECH/yolo26[12]
- 产品信息:M5Stack LLM-8850-Card[13],https://docs.m5stack.com/zh_CN/ai_hardware/LLM-8850_Card
边缘 AI 的未来,正在每一位开发者的手中加速到来。
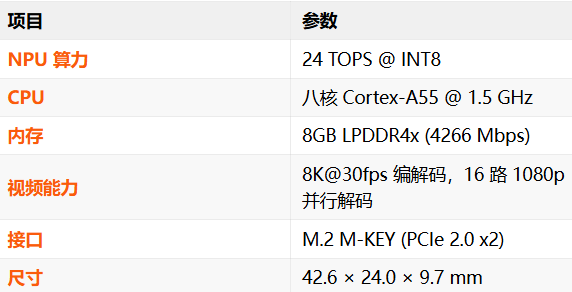
M.2 M-KEY 2242 形态的 AI 加速卡——LLM-8850-Card 关键参数如下所示:
除了本文的 YOLO26n 模型,LLM-8850 还支持更多模型,关于入额快速上手和支持模型列表(包含VLM、LLM、多模态、音频、生成模型等)见:https://docs.m5stack.com/zh_CN/guide/ai_accelerator/overview
参考资料[1]
Ultralytics YOLO26: https://docs.ultralytics.com/models/yolo26/
[2]
Pulsar2 工具链: https://pulsar2-docs.readthedocs.io/zh-cn/latest/pulsar2/introduction.html
[3]
AXERA 运行时库 AXCL: https://axcl-docs.readthedocs.io/zh-cn/latest/doc_introduction.html
[4]
the python api for axengine runtime: https://github.com/AXERA-TECH/pyaxengine/
[5]
NPU Benchmark: https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_npu_benchmark.html
[6]
ax-samples: https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[7]
YOLO26 模型: https://huggingface.co/AXERA-TECH/yolo26
[8]
ax-samples: https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[9]
ax-samples: https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[10]
doc_guide_npu_samples: https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_npu_samples.html
[11]
examples/axcl/ax_yolo26_steps.cc: https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[12]
huggingface.co/AXERA-TECH/yolo26: https://huggingface.co/AXERA-TECH/yolo26
[13]
M5Stack LLM-8850-Card: https://docs.m5stack.com/zh_CN/ai_hardware/LLM-8850_Card
-
首创开源架构,天玑AI开发套件让端侧AI模型接入得心应手2025-04-13 1103
-
【幸狐Omni3576边缘计算套件试用体验】YOLO26 板端部署2026-04-19 642
-
基于SRAM的方法可以加速AI推理2020-12-30 1990
-
MLU220-M.2边缘端智能加速卡支持相关资料介绍2022-08-08 6691
-
瞬变对AI加速卡供电的影响2023-12-01 1685
-
大模型向边端侧部署,AI加速卡朝高算力、小体积发展2024-09-17 6754
-
EPSON差分晶振SG3225VEN频点312.5mhz应用于AI加速卡2024-09-10 598
-
树莓派新推AI HAT+:26 TOPS高性能版本震撼登场2024-11-07 2834
-
边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案2025-05-06 1249
-
如何在树莓派 AI HAT+上进行YOLO目标检测?2025-07-19 2112
-
如何在树莓派 AI HAT+上进行YOLO姿态估计?2025-07-20 1400
-
这个套件让树莓派5运行几乎所有YOLO模型!Conda 与 Ultralytics!2025-07-31 6143
-
此芯科技发布“合一”AI加速计划,赋能边缘与端侧AI创新2025-09-15 2011
-
算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆2025-11-14 10934
-
迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读2025-12-14 2573
全部0条评论

快来发表一下你的评论吧 !
