

关于GN-GloVe的词嵌入技术详解
电子说
描述
词嵌入技术已经成为众多自然语言处理(NLP)应用的基础部分,然而,在现有语料上训练的词嵌入,常常受到社会偏见的影响,比如性别刻板印象。比如,“programmer”(程序员)是一个性别中立词(gender-neutral words),但在新闻语料库上训练的嵌入模型看来,“programmer”和“male”(男性)一词的联系比“female”(女性)更紧密。
带有这样的偏见的词嵌入模型,会给下游的NLP应用带来严重问题。例如,基于词嵌入技术的简历自动筛选系统或工作自动推荐系统,会歧视某种性别的候选人(候选人的姓名反映了性别)。除了造成这种明显的歧视现象,有偏见的嵌入还可能暗中影响我们日常使用的NLP应用。比如,在搜索引擎中输入“computer scientist”(计算机科学家),由于在嵌入空间中,“computer scientist”和男性姓名更接近,和女性姓名更疏远,基于嵌入技术的搜索算法倾向于将男性科学家排在女性科学家之前,阻碍人们认识女性科学家,进一步加剧计算机科学领域的性别不平衡性。
图片来源:Tolga Bolukbasi等
Bolukbasi等提出,通过后处理,可以缓解词嵌入的性别刻板印象(arXiv:1607.06520)。具体方法是将性别中立词投影到一个正交于性别维度的子空间,该性别维度由性别定义词(gender-definition words)定义。所谓性别定义词,是指定义中天然联系性别的词汇,例如“mother”(母亲)、“waitress”(女侍者)。
然而,这一做法有两个局限:
在投影性别中立词之前,需要首先通过分类器识别出性别中立词。如果分类器犯错,那么错误会传播到整个模型中,影响最终表现。
完全移除了性别信息,但是在某些领域(比如医学、社会科学),性别信息是不可或缺的。
而UCLA的Jieyu Zhao、Yichao Zhou、Zeyu Li、Wei Wang、Kai-Wei Chang在即将召开的EMNLP 2018上发表的论文Learning Gender-Neutral Word Embeddings(学习性别中立词嵌入),基于保护属性(protected attributes)隔离性别信息,克服了上述两个局限。
方法
这篇论文改造了GloVe模型,在其基础之上增加了性别保护属性。虽然论文选择GloVe作为基础嵌入模型,但论文提出的方法是通用的,可以应用于其他嵌入模型和属性。
GloVe
首先简单温习下GloVe。
GloVe的主要直觉是,相比单词同时出现的概率,单词同时出现的概率的比率能够更好地区分单词。比如,假设我们要表示“冰”和“蒸汽”这两个单词。对于和“冰”相关,和“蒸汽”无关的单词,比如“固体”,我们可以期望P冰-固体/P蒸汽-固体较大。类似地,对于和“冰”无关,和“蒸汽”相关的单词,比如“气体”,我们可以期望P冰-气体/P蒸汽-气体较小。相反,对于像“水”之类同时和“冰”、“蒸汽”相关的单词,以及“时尚”之类同时和“冰”、“蒸汽”无关的单词,我们可以期望P冰-水/P蒸汽-水、P冰-时尚/P蒸汽-时尚应当接近于1。
具体而言,GloVe基于加权最小二乘回归模型,输入为单词-上下文同时出现频次矩阵:
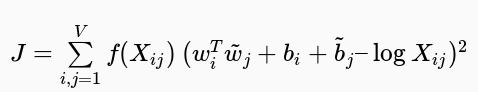
其中,f为加权函数,降低过大的同时出现频次的影响。
GN-GloVe
这篇论文提出了一个GloVe的性别中立变体,称为GN-Glove. GN-Glove将词向量w分成两部分w = [w(a); w(g)],其中w(a) ∈ ℝd-k表示中立成分,而w(g) ∈ ℝk则表示性别成分,k是为性别信息保留的维数(论文中将k设为1,即为性别信息保留一个维度)。
GN-GloVe训练的目标是将性别特征作为保护属性隔离在w(g)中,使w(a)中的信息不受性别影响。相应地,目标函数包括三部分:

其中,λd和λe为超参数,调节目标函数不同部分的影响力。
JG是我们之前给出的GloVe的目标函数,JD和JE迫使性别信息限于w(g)之中,使w(a)保持性别中立。
现在我们来考虑下,如何定义JD,可以让性别信息尽量隔离在w(g)中,也就是让w(g)表示更多的性别信息?
我们可以在监督学习的背景下考虑这个问题。假设我们有一些(人工标注的)性别定义词,那么,如果w(g)能够很好地表示这些性别定义词的信息,那么表示男性的性别定义词和表示女性的性别定义词的差距会很大,从而充分体现性别差异。比方说,“父”的w(g)是2.0,“母”的w(g)是-2.0,相比“父”的w(g)是0.02,“母”的w(g)是0.03,一般来说,前者要更好。由此,我们给出如下的JD定义:
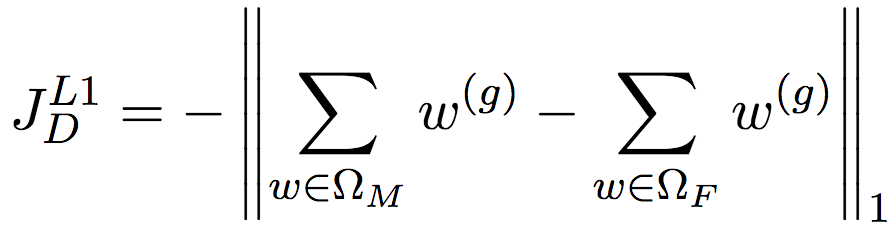
简单说明一下上面的公式,ΩM和ΩF分别是男性定义词(male-definition word)和女性定义词(female-definition word)的集合,论文基于WordNet的定义划分这两个集合。考虑的是总体的情况,所以进行了累加。因为论文为性别信息保留了一个维度,所以上面举例的时候直接使用了实数表示w(g),但实际上性别信息可以占用不止一个维度,因此JD的定义使用了矩阵运算。最后,我们需要最大化男性定义词和女性定义词之前的差距,但最终我们需要最小化目标函数值,所以最后进行了取反操作。
当然,JD的定义不止这一种。我们还可以将w(g)的取值限制在一定范围内,比如[-1, 1],然后尽可能将w(g)往两端推:(1-w父(g))2+(-1-w母)2. 比如,假设“父”向量的w(g)是1,而“母”向量的w(g)是-1,代入上式,结果为0.
由此我们可以得到JD的第二种定义。当然,同样,w(g)实际上是向量,所以我们引入一个向量e ∈ ℝk,该向量的所有分量为1. 然后我们考虑的也是ΩM和ΩF上的整体情况,所以累加一下。最后,[-1, 1]是一个比较合适的取值范围,但我们完全可以选择其他取值范围。所以我们再引入两个系数,将取值范围设定为[β2, β1]. 最终的JD定义为:
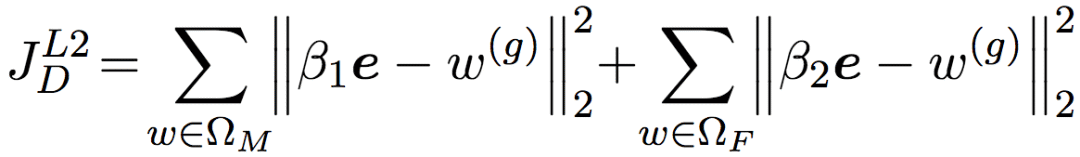
好了,接下来我们讨论JE,也就是处理w(a)的部分。
这里,我们引入了vg ∈ ℝd-k,嵌入空间的性别方向。性别方向的概念很简单。假设我们有很多对性别词,比如“father”(父)和“mother”(母)、“man”(男人)和“woman”(女人)、“国王”(king)和“queen”(王后),将这些成对的性别词向量相减,比如“父 - 母”、“男人 - 女人”、“国王 - 王后”,然后取平均,就得到了性别方向。具体来说,可以使用以下公式表示:
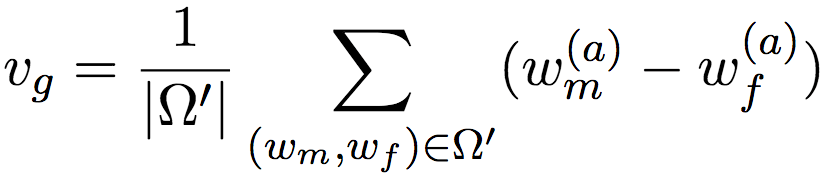
上式中,Ω'是预定义的成对性别词向量集合。这里我们没有直接将词向量w相减,而是将w(a)相减。这是因为,通常情况下,用于保留性别向量的维度很少(论文只使用了一个维度),而一般来说词向量至少有好几百维度。而且,在训练开始阶段,w(a)中同样包含很多性别信息(否则就不需要训练了)。
然后,类似ΩM和ΩF,我们可以基于WordNet划分性别中立词集合ΩN。由于是性别中立词,所以我们期望它们在性别方向上的投影接近零。这和Bolukbasi等将性别中立词投影到一个正交于性别维度的子空间的做法类似。
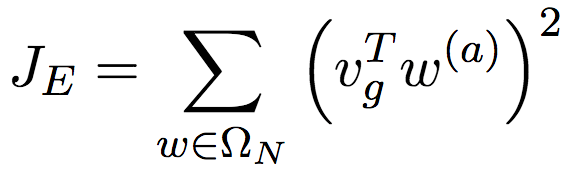
总之,我们用标记过的性别定义词来优化wg,用标记过的性别中立词来优化wa,再加上GloVe原本的优化目标,就得到了GN-GloVe的优化目标。
而且,整个目标函数J是可微的,所以论文在训练时能够采用随机梯度下降进行优化。为了简化训练词嵌入的计算复杂度,论文假定性别方向vg是一个固定向量(也就是说,在更新w(a)的时候,不计算在vg上的梯度),只在每个epoch开始的时候更新下vg.
试验
论文做了全面的试验,验证隔离性别信息至特定维度的想法的有效性:
可视化了嵌入空间,表明GN-GloVe分隔开了保护属性和其他潜属性。
在新的标注数据集上测量了GN-GloVe区分性别定义词(gender-definition words)和性别刻板词(gender-stereotype words)的能力。
评估了GN-GloVe在标准词嵌入基准数据集上的表现,表明隔离性别信息没有影响词嵌入的功能。
演示了GN-GloVe在一个下游应用中降低性别偏差的效果。
设定
对比的基线为原生GloVe和Hard-Glove(即之前提到的Bolukbasi等提出的方法)。
所有嵌入基于2017年的英文维基百科(2017 English Wikipedia dump),GloVe的超参数使用默认值。
训练GN-GloVe时,论文将每个维度的取值范围限定于[-1, 1],以避免数值问题。λd和λe均设为0.8. 根据论文作者的初步研究,模型对这些超参数不敏感。另外,除非特别注明,JD使用第一种定义(L1)。
可视化嵌入空间
论文可视化了词向量的性别分量wg在嵌入空间中的分布(为了便于查看,将横轴拉伸至[-2, 2])。
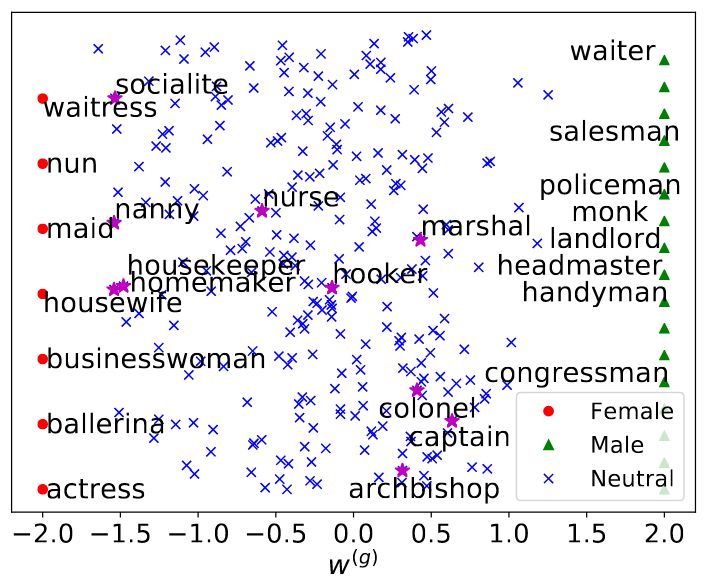
上图中,红点为女性定义词(例如waitress女侍者、nun尼姑、maid女仆、housewife家庭主妇、businesswoman女商人、ballerina芭蕾舞女演员、actress女演员),绿三角为男性定义词(例如waiter男侍者、salesman男售货员、policeman男警察、monk和尚、landlord男地主、headmaster男校长、handyman男杂务工、congressman男议员)。图中的性别定义词位于横轴的两端,这并不出乎我们的意料,毕竟目标函数中w(g)部分的优化正是基于性别定义词的集合ΩM和ΩF。
蓝叉表示性别中立词。从上图可以看到,虽然确实存在越靠近0,性别中立词的性别分量分布就越密集的趋势,但总体上来说性别中立词的性别分量分布得比较分散,这说明基于维基百科训练的性别中立词仍然包含性别信息。其中,紫五星是一些性别中立的表示职业的词汇。这些词汇的可视化表明GN-GloVe能够恰当地保留性别中立词中的性别信息。例如,图中的“nurse”(护士)的性别分量更接近女性,而“captain”(船长)的性别分量更接近男性,和日常的刻板印象一致。
为了验证GN-GloVe很好地隔离了性别信息,论文可视化了上面这些表示职业的词汇的中立成分w(a)在性别方向vg上的投影(即w(a)和vg的余弦相似度)。
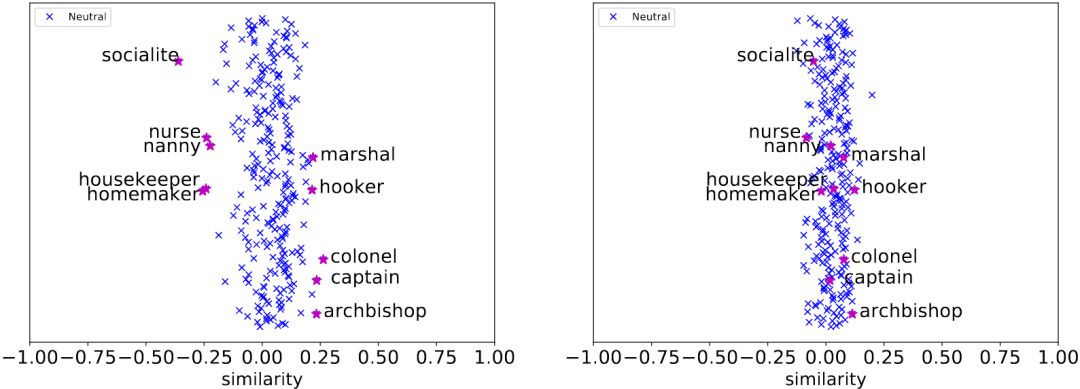
左:GloVe;右:GN-GloVe
可以看到,相比性别刻板印象严重的GloVe,GN-GloVe的中立分量在性别方向上的投影接近零,这说明GN-GloVe很好地隔离了性别信息。
论文统计了表示职业的词汇在性别子空间上的投影平均长度。GloVe是0.080,GN-Glove是0.052. 也就是说,相比GloVe,GN-Glove降低了35%的性别偏差。当然,完全去除性别信息的Hard-GloVe能取得更好的结果,0.019,然而,这也意味着Hard-GloVe损失了性别信息,并且区分性别刻板词和性别定义词的能力较差。
SemBias
为了研究模型表示的性别信息的质量,论文按照SemEval 2012 Task2的方式,创建了一个SemBias数据集。这个数据集中的每个样本包含4对单词,即一对性别定义词(例如,waiter - waitress,男侍者 - 女侍者),一对性别刻板词(例如,doctor - nurse,医生 - 护士),两对与性别无关的意思相近的词(例如,dog - cat,狗 - 猫,cup - lid,杯 - 盖)。模型需要比较这四对词中,哪一对和“he - she”(他 - 她)更接近。理想情形下,模型应当选中性别定义词对。
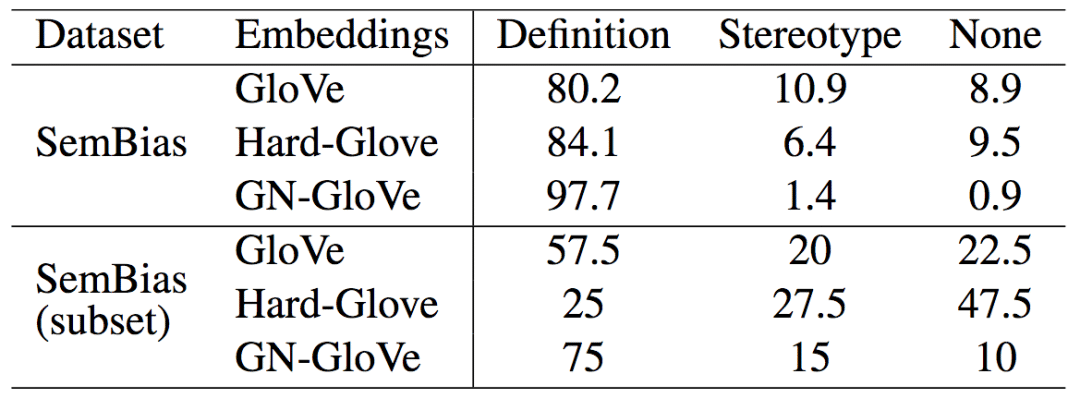
从上表我们看到,GN-Glove在SemBias上达到了97.7%的精确度,显著高于GloVe和Hard-GloVe的表现。SemBias(subset)是包含未在训练中作为种子词汇使用的单词对的数据子集。在这一子集上,GN-GloVe的表现就更突出了,这表明GN-GloVe可以很好地将基于训练集学习到的识别能力推广到其他性别定义词。相反,移除了所有性别信息的Hard-GloVe的表现就很糟糕了,几乎是在随机猜测了。
词汇相似度和类比
在标准词嵌入基准数据集上的评估表明,GN-GloVe在相似度任务上达到了更高的精确度,而在类比任务中的评分略有下降。总体而言,GN-GloVe和GloVe、Hard-GloVe表现大致相当,隔离性别信息并未影响词嵌入的一般功能。

简单说明一下上面的表格。类比任务回答“A对应B,就像C对应_?”这一问题,也就是在嵌入空间中找到最接近wA - wB + wC的词向量w. 相似度任务则评估词嵌入模型捕捉单词相似度的能力(对比人类标注)。
指代消解
最后,论文测试了GN-GloVe在下游应用指代消解上的表现。
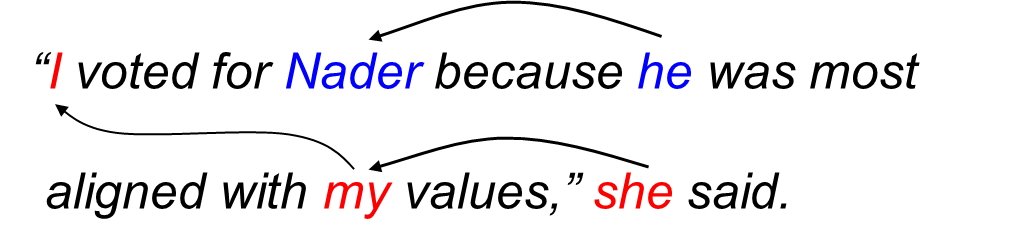
指代消解
论文使用了Ontonotes 5.0和WinoBias这两个数据集。其中,WinoBias数据集由两部分构成,PRO子集偏向刻板印象,ANTI子集反刻板印象。例如,PRO子数据集中有一个样本是“The CEO raised the salary of the receptionist because he is generous.”(CEO给接待员涨了薪水,因为他很慷慨。)在这个句子中,代词“he”(他)指代“CEO”,和社会的刻板印象一致。而ANTI子数据集包含几乎一模一样的样本,只是性别人称代词换成相反的性别,也就是把“he”(他)改成“she”(她)。这和社会的刻板印象相悖,在当前社会,女性CEO在所有CEO中所占的比例远低于男性。

上表中,Avg表示WinoBias数据集的平均F1值(PRO和ANTI的F1值的平均),Diff表示PRO和ANTI的F1值差异的绝对值(Diff越低,说明系统中的性别偏差越低)。总体上来说,在OntoNotes数据集上,GN-GloVe取得了和GloVe、Hard-GloVe相当的表现。而在WinoBias数据集上,相比GloVe,GN-GloVe显著降低了性别偏差。在只使用中立成分w(a)的情况下,GN-GloVe的性别偏差水平接近完全去除性别信息的Hard-GloVe.
结语
在本文的结尾,让我们回顾一下GN-GloVe的优势:
通用性高,适用于任何语言(只需提供预定义的种子词汇),可扩展至GloVe以外的嵌入模型和性别以外的保护属性。
隔离了性别信息,既缓解了在下游应用中加剧刻板印象的问题,又可用于社会科学研究等需要性别信息的场景而无需重新训练词嵌入。
隔离性别信息后,改善了词嵌入的可解释性。
不依赖分类器区分性别中立词,避免了分类误差传播问题。
- 相关推荐
- 热点推荐
- 自然语言处理
-
PyTorch教程15.5之带全局向量的词嵌入(GloVe)2023-06-05 574
-
嵌入式详解2021-07-30 1496
-
鸿蒙构建系统——gn官方FAQ翻译,以及gn官方文档分享2020-11-26 4931
-
词对嵌入技术,可以改善现有模型在跨句推理上的表现2018-11-12 4043
-
详解嵌入式linux 启动信息2017-10-30 1123
-
嵌入式微处理器和接口详技术详解2017-06-28 2165
-
VB中关于MSComm控件使用详解2016-12-16 1145
-
嵌入式Linux系统开发技术详解——基于ARM2016-06-24 6948
-
绝对经典教材.基于ARM嵌入式Linux系统开发技术详解2011-03-22 49791
-
嵌入式liunx开发技术详解2010-03-04 700
全部0条评论

快来发表一下你的评论吧 !
