

从冷战到深度学习,机器翻译历史不简单!
便携设备
描述
深度学习 机器翻译
实现高质量机器翻译的梦想已经存在了很多年,很多科学家都为这一梦想贡献了自己的时间和心力。从早期的基于规则的机器翻译到如今广泛应用的神经机器翻译,机器翻译的水平不断提升,已经能满足很多场景的基本应用需求了。近日,Ilya Pestov用俄语写的机器翻译介绍文章经Vasily Zubarev翻译后发表到了Vas3k.com上。机器之心又经授权将其转译成了汉语。希望有一天,机器自己就能帮助我们完成这样的任务。
我打开谷歌翻译的频率是打开Facebook的两倍,价格标签的即时翻译对我而言再也不是赛博朋克了。这已经成为了现实。很难想象这是机器翻译算法百年研发之战的结果,而且在那段时间的一半时间里其实都没什么明显的成功。
我在本文中讨论的确切发展将立足于所有的现代语言处理系统——从搜索引擎到声控微波。我将探讨的是当今的在线翻译技术的演化和结构。
P. P. Troyanskii的翻译机器(根据描述绘制的图片。很遗憾没有照片留下。)
起初
故事开始于1933年。苏联科学家Peter Troyanskii向苏联科学院提交了《用于在将一种语言翻译成另一种语言时选择和打印词的机器》。这项发明非常简单——它有四种语言的卡片、一台打字机和一台旧式胶片相机。
操作员先取文本的第一个词,然后找到对应的卡片,拍一张照片,再在打字机上键入其形态特征(名词、复数、性别等)。这台打字机的按键编码了其中一项特征。打字带和相机胶片是同时使用的,从而得到一组带有词及它们的形态的帧。
尽管看起来很不错,但和苏联的很多事情都一样,人们认为这项发明是“没用的”。Troyanskii用了20年时间试图完成他的发明,之后因心绞痛逝世。在1956年两位苏联科学家找到他的父母之前,这世上没人知道这种机器。
那是冷战的铁幕刚刚降下的时候。在1954年1月7日,IBM在纽约的总部启动了 Georgetown-IBM实验。IBM 701计算机有史以来第一次自动将60个俄语句子翻译成了英语。
“一位不认识任何一个苏联语言词汇的女孩在IBM卡片上敲出了这些俄语消息。这个“大脑”以每秒两行半的惊人速度在一台自动打印机上赶制出了它的英语翻译。”——IBM的新闻稿
但是,宣告胜利的头条新闻里却隐藏了一个小小的细节。没人提到这些翻译得到的样本是经过精心挑选和测试过的,从而排除了歧义性。对于日常使用而言,该系统并不比口袋里的常用语手册更好。尽管如此,军备竞赛还是开始了:加拿大、德国、法国以及(特别是)日本全都加入到了机器翻译竞赛中。
机器翻译竞赛
改进机器翻译的徒劳工作持续了四十年之久。1966年,US ALPAC在其著名的报告中称机器翻译是昂贵的、不准确的和毫无希望的。他们转而建议将重点放在词典开发上,这将美国研究者排除在了竞赛之外近十年时间。
即便如此,仅凭科学家和他们的尝试、研究和开发,现代自然语言处理的基础还是建立了起来。多亏了这些彼此监视的国家,当今所有的搜索引擎、垃圾信息过滤器和个人助理都出现了。
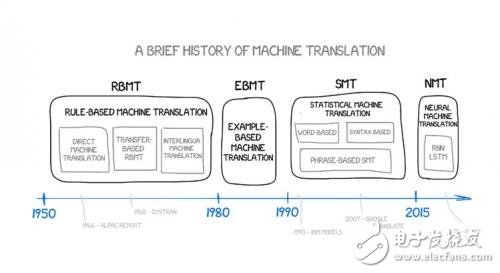
基于规则的机器翻译(RBMT)
最早的基于规则的机器翻译思想出现于70年代。科学家研究了翻译员的工作,试图让当时还极其缓慢的计算机也能重复这些行为。这些系统包含:
双语词典(比如,俄语->英语)
每种语言一套语言学规则(比如,以-heit、-keit、-ung等特定后缀结尾的名词都是阴性词)
这就是这种系统的全部。如有需要,该系统还能得到一些补充,比如增加姓名列表、拼写纠错器和音译功能。
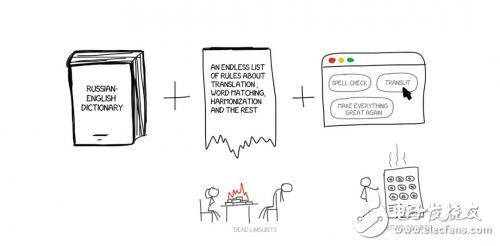
PROMPT和Systran是RBMT系统中最有名的案例。如果你想感受下那个黄金时代的柔和气息,去试试 liexpress吧。
但即使它们也有一些细微差别和亚种。
- 相关推荐
- 热点推荐
-
机器翻译研究进展2023-07-06 2204
-
基于DNN与规则学习的机器翻译算法综述2021-06-29 1003
-
神经机器翻译的方法有哪些?2020-11-23 2050
-
MIT和谷歌开发失传语言的机器翻译系统2019-07-17 957
-
机器翻译走红的背后是什么2019-07-14 1411
-
换个角度来聊机器翻译2019-04-24 4185
-
机器翻译的真实水平如何,梦想与现实的距离到底有多远?2019-03-22 4873
-
阿里巴巴机器翻译在跨境电商场景下的应用和实践2018-07-31 801
-
机器翻译三大核心技术原理 | AI知识科普2018-07-06 7285
-
从冷战到深度学习_机器翻译历史不简单2018-06-01 1520
-
当机器翻译遇见深度学习2018-05-18 3034
-
专栏 | 深度学习在NLP中的运用?从分词、词性到机器翻译、对话系统2017-08-18 8294
-
搜狗“知音”实时翻译可实现语音识别与机器翻译融合2016-12-01 3092
全部0条评论

快来发表一下你的评论吧 !
