

是否有一种模型能在特定时间内自动识别视频中的某个人物呢?
电子说
描述
编者按:本文作者Pulkit Sharma分享了一篇有趣的项目,以《猫和老鼠》为例,计算任意视频中汤姆猫和杰瑞鼠的出镜时长。这一模型也可以用于其他电影,轻松统计各演员的上镜时间。
简介
当我开始接触深度学习时,学到的第一件事就是图像分类。这个话题非常有趣,包括我在内的很多人都沉浸在它的魅力之中。但是在我处理图像分类时总会思考,如果我能将学到的东西迁移到视频上就好了。
是否有一种模型能在特定时间内自动识别视频中的某个人物呢?结果证明的确可以做到,下面就将我的方法分享给你们!
影视明星的出镜时间是非常重要的,直接影响他们的片酬。举个例子,在《蜘蛛侠:英雄归来》中,小罗伯特唐尼仅仅出镜15分钟就有高达1000万美元的片酬。
如果我能计算任意影片中所有演员的出镜时间,那就太棒了!在这篇文章中,我将帮你理解如何在视频数据中使用深度学习。我们就用《猫和老鼠》作为例子,计算任意视频中,汤姆和杰瑞的出现时间。
注:本文需要读者有一定的深度学习图像分类的先验知识。如果没有的话,我推荐你阅读这篇文章(https://www.analyticsvidhya.com/blog/2016/10/tutorial-optimizing-neural-networks-using-keras-with-image-recognition-case-study/),了解有关深度学习和图像分类的基本概念。
目录
读取视频并提取帧
如何用Python处理视频文件
计算出镜时间——一种简单的解决方案
我的收获
读取视频并提取帧
如上面的动图所示,,每一页纸上都有不同的画面,随着我们翻动书页,可以看到一只跳舞的鲨鱼,而且翻动的速度越快,效果越好。这也可以看作一种视频,换句话说,这种视觉效果是不同图像以特定顺序排列在一起产生的。
同样的,视频也是由一系列图片组成的,这些图片称为“帧”,可以通过组合得到原始视频。所以与视频数据有关的问题和图像分类或者目标检测问题并没有什么不同。只是从视频中提取帧需要多一个步骤。
我们这次的目的试计算汤姆和杰瑞在视频中各自的出镜时间,首先让我们确定一下文中要做的步骤:
导入并读取视频,从中提取帧,将它们保存为图片
标记一些图片用于模型的训练(这一步我已经做好了)
在训练数据上搭建自己的模型
对剩余图片进行预测
计算汤姆和杰瑞各自的出镜时间
跟着以下步骤学习,将会帮助你解决很多深度学习相关的问题。
如何用Python处理视频文件
首先要下载所有必需的库:
NumPy
Pandas
Matplotlib
Keras
Skimage
OpenCV

第一步:读取视频并从中提取帧,将其保存为图像
现在我们要下载视频,并将它转换成帧的形式。首先我们可以用VideoCapture( )函数从给定目录中提取视频,然后从视频中提取帧,用imwrite( )函数将它们保存为图像。
视频下载地址:drive.google.com/file/d/1_DcwBhYo15j7AU-v2gN61qGGd1ZablGK/view

这个过程完成后,屏幕上会出现“Done!”的字样。下面我们试着对图像(帧)进行可视化,首先用matplotlib中的imread( )函数读取图像,然后用imshow( )函数显示图像。

这就是视频中的第一帧。我们从每秒中提取一帧,由于视频时长为4:58(共298秒),我们现在一共有298张照片。
我们的任务时确定哪张照片上有汤姆,哪张有杰瑞。如果我们提取出的图像能和常见的ImageNet数据集中的图片有很大的相似性,那么这个问题就能轻而易举地解决了。但是这样的乐趣在哪里?
我们的是动画片,所以要让任何预训练模型在给定的视频中定位汤姆和杰瑞还是有难度的。
第二步:标记图片训练模型
要实现标记图片,一种可能的方案是手动贴标签。一旦模型学会了特定模式,我们就能用它在之前没见过的图像上作出预测。
要记住的一点是,有些帧里可能没有汤姆和杰瑞的镜头,所以我们要将其看成是多种类的分类问题:
0:没有汤姆和杰瑞的镜头
1:杰瑞
2:汤姆
我已经给所有图片打上了标签,所以直接在mapping.csv文件中下载即可。


映射文件包含两部分:
image_ID:包含每张照片的名称
Class.Image_ID:含有每张图对应的种类
下一步是读取图片信息,即他们的Image_ID部分:

现在我们就有了图片,记住,我们要用两部分训练模型:
训练图片
对应的种类
由于这里有三种不同情况,我们将用keras.utils中的to_cateforical( )函数对他们进行独热编码。

图片再输入到VGG16训练前,尺寸需变为224×224×3,所以我们的图片在输入前要重设尺寸。我们要用到skimage.transform中的resize( )函数。

尺寸调整好后,我们还要对每个模型的需求进行预处理,否则模型就不会表现得很好。利用keras.applications.vgg16中的preprocess_input( )函数来完成这一步骤。

我们还需要一个验证集来检查模型在陌生图片上的性能,这里就需要用到sklearn.modelselection模块中的traintest_split( )函数来随机将图片分成训练集和验证集。

第三步:搭建模型
下一步就是搭建自己的模型。我们会用VGG16预训练模型来完成这一任务。首先导入所需的库:

下载VGG16与训练模型,并将其保存为base_model:

用该模型对X_train和X_valid进行预测,得到特征,再用特征重新训练模型。

Xtrain和Xvalid的尺寸分别为(208,7,7,512)和(90,7,7,512)。为了输入到神经网络,我们必须把它重新修改成1—D尺寸。

现在对图像进行预处理,去中心化,让模型收敛得更快。

最后,我们将搭建自己的模型,这一步可以分为三小步:
搭建模型
编译模型
训练模型

用summary( )函数检查模型的汇总信息:

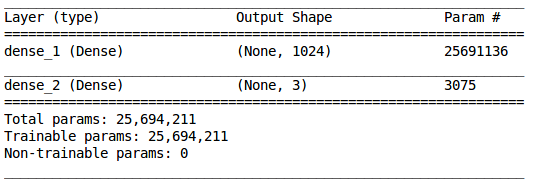
模型中有一隐藏层,有1024个神经元,输出层有3个神经元(因为我们有3种不同的预测情况)。现在我们开始编译模型。

最后一步,我们要训练模型,并且用验证集检测它在陌生图像上的表现:

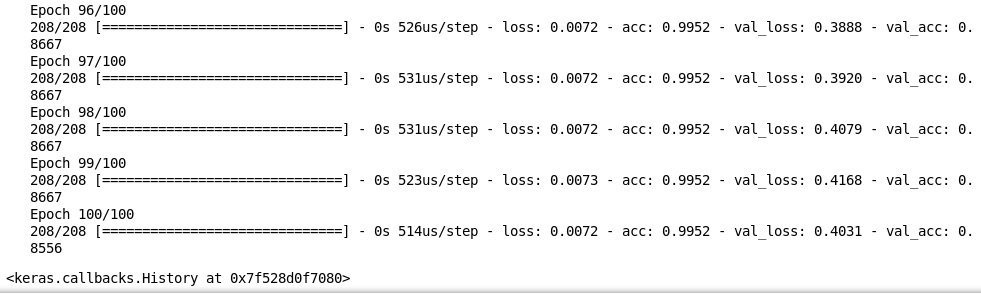
可以看到在验证集上的表现很不错,精确度达到85%。这就是我们如何在视频数据上训练模型,再对每一帧作出预测的步骤。
下面,我将计算汤姆和杰瑞在新视频中的出镜时间。
计算出镜时间——一种简单的解决方案
首先下载我们要用到的视频。一旦完成,可以从中提取帧:

从新视频中提取帧之后,我们就要下载test.csv文件,它包含每个提取出的帧的名字:

接着,我们将导入用于测试的图片,然后针对之前提到的预训练模型重新修改尺寸:


接着,我们还要对这些图片进行调整,就像之前处理训练图片那样:

由于我们之前训练了模型,就可以用它做出预测了。
第四步:对剩余图像进行预测

第五步:计算汤姆和杰瑞的出镜时间
刚刚我们规定了1代表杰瑞,2代表汤姆,这样就可以用上述的预测来计算两个角色的出镜时长了:


结果如上。
我的收获
为了完成这一项目,我遇到了很多问题。下面是我遇到的一些挑战及做出的应对对策。
首先,我尝试在没有删除最顶层的情况下使用预训练模型,结果并不理想。原因可能是由于我们的模型之前没有在动画片上接受训练。为了解决这个问题,我重新用图片训练模型,结果好了很多。
但是尽管用带有标记的图片训练,精确度仍然不理想。模型在训练图像上表现得并不好。所以,我试着增加图层数量。这种做法结果不错,但训练和验证精度之间并不对应。模型出现了过度拟合,它在陌生数据上表现得也不好。所以我在密集层之后增加了Dropout层,这样就解决了。
我注意到,汤姆的出镜时间更长,所以模型得出的很多结论都是汤姆。为了让模型平衡预测,我用了sklearn.utils.classweight模块中的computeclass_weight( )函数。它在数值计数较低的类别中分配了更高的权重,在较高的数值计数中分配较低权重。
另外,我还用Model Checkpoint保存了最佳模型。
最终,我们在验证数据上达到了88%左右的结果,在测试数据上达到了64%的精确度结果。
-
Tricore MCU是否只能在特定时序下识别连接了OCDS?2024-07-05 639
-
自动识别事件类别的中文事件抽取技术研究2010-04-24 2035
-
一种目标自动识别与跟踪算法研究2012-06-30 13680
-
DAQ测量规定时间内的采集次数2015-12-17 4874
-
求一段时间内数据的和2016-08-03 2212
-
请问CC3000是否有一套机制,在一定时间内套接字未进行通信,会自动关闭?2018-06-07 1483
-
为什么Type-C接口能在短时间内迅速取代Micro USB接口呢2021-09-14 3103
-
如何统计光电编码器一定时间内的脉冲数目呢2021-11-19 2213
-
如何点亮某个LED?如何检测按键是否按下呢2022-01-06 762
-
一种改进的步态识别方法2009-04-01 514
-
一种视频流特定人物检测方法2018-03-05 1022
-
基于视频深度学习的时空双流人物动作识别模型2018-04-17 1843
-
谷歌推出视频智能API 自动识别物体2018-05-05 2993
-
电力电容器为什么不允许短时间内过电压运行2024-02-26 2214
-
水位自动识别摄像机2024-07-31 1109
全部0条评论

快来发表一下你的评论吧 !
