

Pix2Pix与Unity 3D结合,打造专属小猫咪!
电子说
描述
图像翻译已然不是一件新鲜的事情了,但最近博主Keijiro Takahashi不仅实时的完成了这个图像生成任务,而且还将它“贴”到了3D模型上,打造了一只生动可爱的“专属小猫咪”!
看!这货竟然比神笔马良还要厉害!
随着GAN、pix2pix等技术的提出,图像翻译已然不是一件稀奇的事情。但实时且3D的图像翻译,却算的上是喜闻乐见了。
作者Keijiro Takahashi历经半个月的时间,终于“翻译”出了这只活灵活现的3D小喵咪:
专属猫咪,你值得拥有!
其实,搞出来个这样的喵咪并不难。
首先,用Sketch Pad画一个猫!
类似于非常出名的edges2cats,Sketch Pad也是一种演示方法,但它还是实时的。
其次,需要一些系统的要求:
Unity 2018.1
计算着色器功能(DX11,Metal,Vulkan等)
尽管它是以平台无关的方式实现的,但它的许多部分都针对NVIDIA GPU体系结构进行了优化。
为了完美地运行Sketch Pad,作者建议使用GeForce GTX 1070或更高版本的Windows系统。
那么,如何使用训练过的模型呢?
这个存储库不包含任何用来节省带宽和存储配额且经过训练的模型。
要在Unity Editor上运行示例项目,需下载预先训练好的edges2cats模型,并将其复制到Assets/StreamingAssets中。
该实现只支持在Christopher Hesse交互演示中使用的.pict权重数据格式。你可以选择一个预先训练好的模型或者使用pix2pix-tensorflow来训练你自己的模型。
经典Pix2pix
Pix2pix 是一个不同图像效果的转换工具,基于GAN实现。Pix2pix由UC Berkeley的Phillip Isola等人提出,论文最早在2016年11月在arxiv上公开,并被CVPR 2017录取。虽然是比较老的论文,但作为一篇很经典的论文,非常值得一读,因此我们也在这里介绍一下Pix2pix的方法。
论文研究了条件对抗网络作为一种图像到图像转换问题的通用解决方案。这些网络不仅学习从输入图像到输出图像的映射,还学习了用于训练该映射的损失函数。这使得对传统上需要非常不同的损失公式的问题应用相同的通用方法成为可能。
研究人员证明了这种方法在从标签地图合成照片,从边缘地图重建对象,以及给黑白图像上色等任务中都是有效的。这项工作表明我们可以在不需要手工设计损失函数的情况下获得合理的结果。
图1:有条件的对抗性网络是一种通用的解决方案,似乎可以很好地解决各种各样的问题。这里我们展示几种方法的结果。在每种情况下都使用相同的架构和目标,只是简单地在不同的数据上训练。
在一些任务中,可以相当快地在小数据集中获得不错的结果。例如,为了学习生成外墙(如上图所示),我们仅花了大约2小时训练了400张图像(用一个Pascal Titan X GPU)。然而,对于更困难的问题,在更大的数据集上进行训练可能是很重要的,而且需要花费很多小时甚至数天的时间。
既然是基于GAN的,那么Pix2pix也离不开生成器和判别器。
GAN是生成模型,它学习从随机噪声向量z映射到输出图像y,即:G : z → y。
相比之下,条件GAN是从观察到的图像x和随机噪声向量z,学习它们与y的映射,即:G : {x, z} → y。
生成器G是训练来产生输出的,目的是让这些输出不被对抗训练的鉴别器D将其与“真实”图像区分开来;同时,鉴别器D被训练来尽可能地检测到生成器的“假”输出。训练过程如下图所示:
训练一个从map edges到photo的条件GAN
网络架构
这里采用了深度卷积生成对抗网络DCGAN中的生成器和鉴别器的结构进行调整。生成器和鉴别器都采用了convolution-BatchNorm-ReLu的模块。
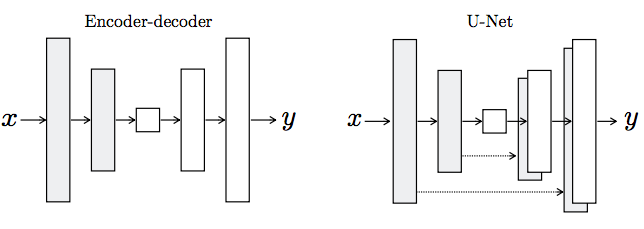
生成器架构的两种选择。“U-Net”是编码器 - 解码器,在编码器和解码器堆栈中的镜像层之间有跳过连接(skip connection)。
有关Pix2pix结构的更多细节,请阅读原论文:
https://arxiv.org/pdf/1611.07004.pdf
Pix2pix最著名的应用是“画猫”,edges2cats便是基于pix2pix-tensorflow的一个实现,请看效果:
而今天我们介绍的Pix2Pix for Unity更是脑洞大开,在3D模型之上“画猫”,让生成的猫咪动了起来。程序员撸猫还真是方便呢!
-
Unity 3D和Vuforia制作AR人物互动2018-09-21 3873
-
基于PIX模块化的底盘架构2021-08-26 2015
-
怎样通过I2C去直接读取PIX4FLOW的数据呢2021-11-12 1608
-
会眨眼的小猫咪电路图2009-11-18 1442
-
如何配置Cisco PIX防火墙2010-01-13 795
-
Aptina DR-Pix技术白皮书2017-01-19 1526
-
PIX自动驾驶与导航科技企业Fixposition达成战略合作2021-03-05 2574
-
Unity 3D引擎制作的愤怒的小鸟游戏2021-05-12 1210
-
PIX飞控电调校准技术及其教程2021-07-13 1683
-
无人机PIX固件分享2022-09-09 808
-
Pix a Sketch LED矩阵上的虚拟蚀刻草图2022-11-10 607
-
PIX日本机器人工厂正式投产2024-12-18 1456
-
PIX Moving宣布完成B1轮融资2024-12-30 1331
-
PIX Moving与RoboSense速腾聚创达成战略合作2025-10-31 2137
全部0条评论

快来发表一下你的评论吧 !
