

基于ADSP—BF533硬件平台上实现H.264实时解码器的设计
描述
引 言
H.264是ITU T的VCEG和ISO/IEC的MPEG联合成立的联合视频组JVT(Joint Video Tearn)共同制定的新视频编码标准,定位于覆盖整个视频应用领域。H.264标准采用了基于可变大小宏块的运动补偿、多帧参考、整数变换、基于1/4像素精度的运动估计、去块效应滤波器等新技术,因而获得更好的压缩性能,同时也导致了运算量的大幅度增加。
Blackfin处理器采用了ADI公司和英特尔公司共同开发的微信号结构,在结构中加人专门的视频处理指令,工作频率高达756 MHz,能完成12OOM次/s乘加操作。与采用超标量结构或超长指令集的DSP(如TI的C6000系列)相比,Blackfin处理器在功耗、成本方面具有很大的优势,非常适合嵌入式的视频应用。
1 H.264视频编码标准
H.264视频编解码器的基本结构与早期的编码标准(H.263、MPEG4等)相似,都是由运动补偿、变换、量化、熵编码、环路去块效应滤波器等功能单元组成的。H.264标准的改进主要体现在各功能模块内部。H_264的重大改进表现在以下几个方面:
①高精度的基于1/4像素精度的运动预测。
②多种宏块划分模式。每个宏块(16×16像素)的亮度分量有7种分区方法:16×16、16×8、8×16、8×8、8×4、4×8、4×4。
③多帧预测。在帧间编码时,可选5个不同的参考帧。
④整数变换。采用基于4×4像素块的整数变换代替DCT变换。
⑤H_264/AVC支持两种熵编码方法,即CAVLC(基于上下文的自适应可变长编码)和CABAC(基于上下文的自适应算术编码)。CAVLC的抗差错能力比较高,而编码效率比CABAC低;CABAC编码效率高,但需要的计算量和存储容量更大。
⑥帧内预测编码。H.264采用了多种设计合理的帧内预测模式,大大降低了I帧的编码率。
⑦网络适配层NAL(Network Abstraction Layer)为视频编码层提供一个与网络无关的统一接口,使视频编码数据能适应不同的网络应用环境。
H.264分为7种不同的框架(profile)——Baselineprofile、Main profiIe、Extended profile、High profik、High10 profik、High4:2:2 profile和High 4;4:4,分别代表不同的技术限制和算法集合。其中baseline prome的使用是不收版权费的。
2 基于ADSP—BF533的软硬件实现平台
硬件平台采用ADI公司的ADSP—BF533 EZ—kit Lite评估板。此评估板包括l块ADSP—BF533处理器,32MB SDRAM,2 MB? Flash,ADVl836音频编解码器外接4输入/6输出音频接口,ADV7183视频解码器和ADV7171视频编码器外接3输入/3输出视频接口,1个UART接口,1个USB调试接口,1个JTAG调试接口。评估板系统结构框图如图1所示。
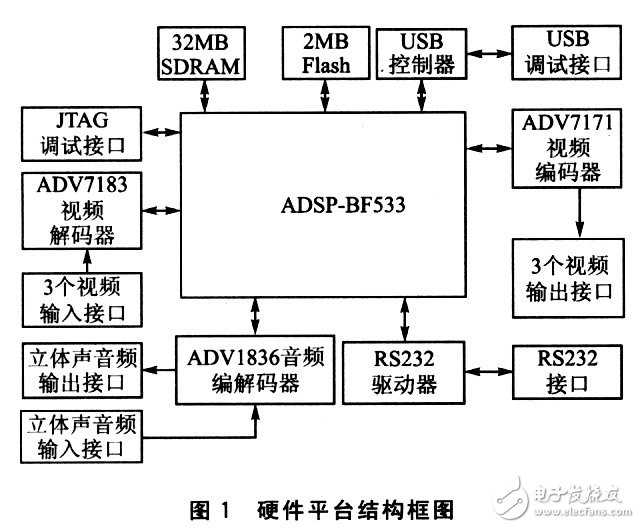
评估板上采用的ADSP—BF533处理器,工作频率高达756 MHz。该处理器有以下特点:双16位乘法累加器;双40位算术逻辑单元(ALU);4个8位视频ALU;1个40
位移位器;专用的视频信号处理指令;148 KB的片内存储器(16 KB可作为指令Cache,32 KB可作为数据Cache);动态电源管理功能等。Blackfin处理器还包括丰富的外设和接口:EBIU接口(4个128 MB SDRAM接口,4个l MB异步存储器接口),3个定时/计数器,1个UART,1个SPI接口,2个同步串行接口,1路并行外设接口(支持ITU一656数据格式)等等。Blackfin处理器在结构上充分体现了对媒体应用(特别是视频应用)算法的支持。
软件验证采用如下方式:首先,通过DSP仿真器将H.264编码文件拷贝到评估板的存储器里。然后,软件从存储器中读取编码文件的数据,进行解码操作。最后,将解码的数据通过PPI接口输出到ADV7171芯片,ADV7171芯片将输入的视频数据编码为PAL格式输出到显示器上二进行显示。
Blackfin处理器的软件开发平台是VisualDSP++4.0。
3 H 264实时解码器软件设计
3.1软件总体设计
为了实现实时解码的要求,需要优化程序的设计。优化流程如下:
①在PC机上进行算法的验证和评估、优化程序的流程设计和数据结构设计。
②将程序代码移植到Blackfin处理器。在Visual—DSP++集成开发环境里进行编译,删除PC平台相关的代码,添加DSP平台相关的代码。
③进行基于DSP平台的优化操作。设置速度优化的编译参数,进行C语言级的优化,用汇编指令改写最耗时的函数,通过使用专用的向量指令和并行指令减少函数的执行时间。
3.2 在PC机上实现并优化解码器程序
解码器程序参考了JM9.6,并在以下方面作了优化:
①由于只支持Baseline profile,删除有关B帧、SI片、SP片和数据分割等不支持特性的冗余程序代码;
②修正JM9.6,每次处理一个Slice时都要分配内存,读取其中信息,再释放内存,合理安排内存空间的分配和释放;
③将I帧、P帧分别独立解码,宏块解码也按预测模式和预测方向分成不同的解码模块,以省去中间的重复判断,提高解码速度;
④优化CAVLC码表的查询方法。
3.3 程序移植
VisualDSP++是一款支持Blackfin处理器的集成开发、调试环境,包括VisuaIDSP++内核(VDK)、C/C++编译器、高级图形绘制工具、调试工具、器件模拟器等多种功能;能够很好地支持在Blackfin处理器上用C/C++语言进行开发工作。
移植的第一步是除去所有的编译环境不支持的函数(例如某些时间相关的函数),将文件操作修改为读取文件数据缓存的操作,删除SNR信息收集和信息打印输出等DSP平台实现不需要的代码。第二步是添加与硬件相关的代码。这些代码包括系统初始化代码、输出模块代码、中断服务程序和解码速率控制程序等程序代码。
移植完毕后,就实现了基于ADSP-BF533处理器的H_264解码器;但速度达不到实时解码的要求,还需要进行优化。
3.4 基于DSP平台的优化
基于DSP平台的优化分为系统级优化、C程序级优化和汇编级优化。
(1)系统级优化
打开编译器中的优化开关,设置为速度最优化;打开自动内联开关;打开“Interprocedural optimization”(过程间优化)开关;使用VisualDSP++编译器的PGO(Profile—Guided Optimization)优化编译技术。
(2)C程序级优化
C程序级的优化主要是针对BIackfin处理器的具体特点进行优化:
①编写链接描述文件,将经常用的数据存储在片内存储器,例如CAVLC熵解码的码表;启用指令Cache和数据Cache,设置好启用Cache机制的指令地址和数据地址。
②将除法操作转换为乘法操作或者采用查表法计算。
③减少对片外存储器的访问次数。对于经常访问的片外存储器区域,设置Cache使能,并可设置Cache锁定,防止被缓存的数据被替换,减少Cache未命中的几率。
④对于能够用较短的数据类型表达的数据改用较短的数据类型表达,例如原定义为int类型的4×4逆整数变换的输人数据,实际上可以定义为short类型。
(3)汇编级优化
汇编级优化通常遵循以下原则:
① 使用寄存器代替局部变量。如果局部变量用来保存计算的中间结果,那么用寄存器
代替局部变量可以省掉很多访问内存的时问。
② 使用硬件循环代替软件循环。.Blackfin处理器有专用的硬件支持两级嵌套的零开销
硬件循环。用硬件循环代替软件循环可避免堵塞流水线,提高速度。
③ 使用并行指令和向量指令。使用并行指令和向量指令,可以充分利用Blackfin处理器的SIMD系统结构的优点和内部硬件资源的并行处理优点,减少指令执行次数和提高指令执行效率。使用1条并行指令同时执行2条或3条非并行指令。向量指令可以同时对多个数据流进行相同的加工操作。
④ 使用视频处理指令。视频处理应用可以使用Blackfin处理器专用的视频处理指令,提高执行效率。
将最耗时的一些函数用汇编语言改写,充分利用Blackfin处理器的S1MD结构的优点和硬件上的并行性,在一个指令周期内执行多个操作,减少函数执行需要的指令周期。最耗时的函数有宏块解码函数decode_one_macroblock、逆整数变换函数itrans、去块效应滤波函数EdgeLoop、滤波门限计算函数Get_Strength等函数。
下面以4×4矩阵逆整数变换函数itrans和1/4像素插值滤波get_block(),说明用汇编指令优化带来的性能提高。4×4矩阵的逆整数变换函数itrans采用的是2级蝶形运算,先对4×4矩阵的每一行分别做行逆变换,再对每一列做列逆变换。一维变换采用如图2所示的蝶形算法。
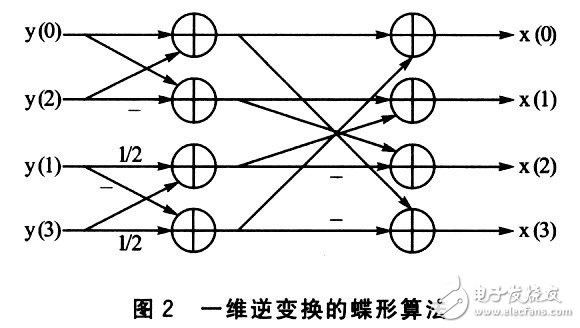
Blackfin处理器的SIMD结构支持向量操作,最多可以在1个周期内完成4个16位的加法操作。它的并行指令能同时进行算术运算和两个数据的装载/存储操作。例如上述的蝶形运算可以用如下指令实现(设寄存器IO中保存了输人数据y的地址,I2中保存了系数数组cof={0x7fff,0x4000}的地址,Il中保存了临时变量tmp的地址,R2和R1保存的是中问结果):
R7=[IO++];
Al=R6.I*R7.1,AO=R6.1*R7.1(IS)┃│I R5=
[10++]┃┃[││++]=R2;
R4.h =(A1一一R5.1*R6.1),R4.1=(AO+=R5.1*R6.1)(IS)││W[I1++]=R1.h;
R7.1=R6.1*R5.h(IS)1 W[11++]=R1.1;
R5=R7》》》1(v);
A1=R6.1*R5.h,AO—R6.1*R5.1(IS);
R3.h一(A1+一R6.1*R7.1), R3.1一(AO =R6.1*R7.h)(IS);
R2=R4+l+R3,R1=R4一│ 一R3:
完成一次一维逆变换只需8条指令,算上函数调用的开销和其他一些辅助指令,完成一个4×4矩阵的逆整数变换时总共需要82条指令周期。表1是优化前、后的比较。

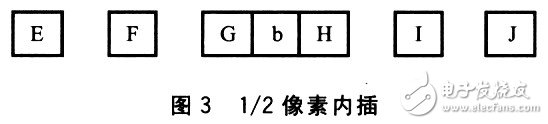
get_block函数对像素矩阵进行1/4像素插值操作。先用六阶滤波器进行1/2像素插值,然后用线性内插法进行l/4像素插值。
l/2像素b计算方法为:b=round((E一5F+20G+20H一5I+j)/32)。示意图如图3所示。E、F、G、H、I、J是整数像素,b是G和H之问的1/2像素。
像素的亮度值为unsigned char类型,先利用并行指令可以在1个指令周期内将8个像素的亮度值读到寄存器,然后利用视频专用指令将4个字节解包到1个寄存器对(R1:O或R3:2)中去,利用向量指令在1个周期内进行2次乘加操作。通过视频专用指令、向量指令和并行指令的使用,减少了函数指令的指令周期数。
4 实验结果
在EZKit533开发板上测试了解码器算法,对CIF格式(352×288)的foreman测试序列,可以达到45~50帧/s的解码速度;对CIF格式的mobile测试序列,能够达到40帧~44帧的解码速度。如果增加解码速率控制模块,可以稳定地实现以30帧/s的速率播放CIF测试序列。实验结果证明,在Blackiln处理器上实现H.264实时解码器是可行的。ADI公司甚至声称可以在600 Mtz的BF533处理器上实现D1(720×576)格式的视频实时解码器。
BIackfin处理器有低功耗、低成本和高性能的特点。在Blackfin处理器上实现的H.264视频解码器很适合用于IP机顶盒、可视电话、PMP(便携式媒体播放器)等嵌人式视频应用中。
-
EE-229: ADSP-BF531/BF532/BF533 Blackfin功耗估算2025-01-06 674
-
怎么实现基于ADSP-BF561的H.264编码器设计?2021-06-07 1363
-
如何去实现并优化H.264解码器算法?2021-06-02 1809
-
ADSP-BF531/BF532/BF533黑丙烯BSDL 176-Pin LQFP包(02/2004)2021-05-21 1015
-
EE-203:通过异步端口将ADSP-BF535/ADSP-BF533 Blackfin®处理器连接到NTSC/PAL视频解码器。2021-05-20 1040
-
ADSP-BF531/BF532/BF533 Blackfin®功耗估算(Rev 4, 12/2007)2021-03-19 1226
-
基于USB 2.0集成芯片的H.264解码器芯片设计2018-10-31 1286
-
在ADSP-BF561上实现与优化的H.264解析2017-10-25 1058
-
网络视频编解码器H.2642016-12-23 1173
-
基于ADSP-BF533处理器的H.264解码器2011-02-28 1113
-
基于ADSP-BF533处理器的去方块滤波器的实现及优化2010-01-26 723
-
基于BF533和H264的视频服务器的实现2009-08-31 1100
-
基于ADSP-BF561的H.264视频编码器的实现2008-12-26 966
全部0条评论

快来发表一下你的评论吧 !
