

FPGA作为协处理器设计的原则及在相位编组算法的实现中的应用
描述
实时系统一般都不是通用的,往往是针对具体的任务而设计的。软件编程的优点是设计调试灵活。无论多复杂的任务,只要给出算法,我们一定能够通过软件编程的方式来实现,而且调试、修改都容易得多。缺点是执行指令的效率不高,单CPU只能串行地执行指令(多CPU方案确实是克服这一缺点的有效办法,但是大大增加了软硬件的复杂度)。对于一项任务,软件都要将它不断分解,最终变成CPU可执行的机器语言,这种化整为零的指令方式正是软件的优点,同时也成了它的缺点。执行一条指令一般需取指令、解码、取操作数、执行四步。虽然CPU内部有了cache,实行流水指令操作,但是如果语句中有大量的跳转语句,就会使流水线频繁中断,并且使cache的命中率降低。专用硬件的特点是速度快,便于进行并行性设计,是满足实时性要求最好的方法。其缺点在于设计周期长,调试修改不容易,受到可用器件的实际限制,复杂的算法难以完全用硬件来完成。从以上的分析中,我们看到软硬件设计有各自的优缺点,能否将软硬件各自的优点结合起来呢?FPGA出现后,由于它设计输入方式灵活,设计周期短,片内资源丰富,可无限次加载等特点,很适合对具体的任务进行设计。我们可以用它来发挥硬件速度快的特点完成低层的、大量重复使用的任务。而处理器在上层实时调用FPGA。FPGA就象一个硬件函数,这种结构既可以发挥硬件的高速性,又利用了软件的灵活性。两者的结合可以极大地提高整体处理速度,而且开发周期短,修改方便。
下面以图像处理中的直线提取算法的实现为例,来说明FPGA作为协处理器在实时系统中的应用。
1 相位编组算法实现直线提取
1.1 相位编组算法实现直线提取的原理
直线提取就是将图像中明暗变化的边缘以轮廓线或边界线的形式提取出来。相位编组算法是直线提取中比较有效的一种。其算法框图如图1。
一帧图像的象素逐行输入,计算梯度方向角是先对图像的每个像素求x方向上的差分Dx和y方向上的差分Dy。arctg(Dy/Dx)是该点梯度的正切值。

相位编组是将所有具有相同或相近方向角且几何位置连通(8连通或4连通)的点归为一个点集,该集合就是直线的点集。实际上,图像中大部分的点周围明暗变化很小,我们只对M值大于一个给定的阀值Threshold的点进行编组。为了减少下一步处理的数据量,我们把满足M大于阀值的点写成水平跑码的形式,即把水平位置相邻且方向值θ相同的点编为一个跑码。然后每一行的跑码与上一行的跑码进行比较,几何位置连通且方向值相近的跑码归为一类。这样,就得到整个图像中的所有直线的点集合了。
得到直线的点集后,用最小二乘法对每个点集拟合出直线。
1.2 系统的软硬件划分
系统在实现算法的前提下对实时性有较为苛刻的要求,图像大小为512×512,图像数据的传输速率为5MByte/s,两帧的间隔为0.6秒,要求系统提取直线的时间不得超过0.5秒。分析上面的框图,要做的处理非常多,包括对图像进行求差、求和运算、二维梯度场计算、相位编组、直线拟合等不同层次不同类别的处理和计算,如果完全由软件做,为了达到所要求的实时性,CPU的主频至少要250MHz以上,现有的高速DSP难以胜任。所以,必须考虑一部分任务由专用硬件来完成。经过严密的论证,最后系统采用了图2所示的结构。
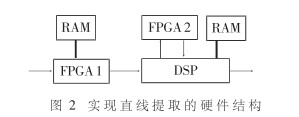
FPGA1和FPGA2选用XILINX公司的XC5210,DSP选用内部主频为20MHz的TMS320C40。求梯度、求反正切及编码等步骤属于像素级的处理,处理比较规则,而且随着像素的流水输入,一直到编码完成,没有中间数据需要存储,可由前级FPGA1完成。其中求反正切可用查表法,查表的数据放在与FPGA1相连的RAM中。跑码的数据结构为:
typedef struct tagRUNCODE{
int x0;
int len;
unsigned char orientation;
}RUNCODE;
其中x0代表初始点的X坐标, len代表跑码长度,orientation代表跑码的方向值。剩下的就是相位编组和直线拟合了。直线拟合主要是浮点运算,交给DSP完成比较合适。难度在于相位编组。相位编组约占直线提取整个工作量的70%,操作复杂,属于全局性的处理,涉及到对RAM的管理及访问,该部分无法由硬件独立完成。我们必须对这一部分进行软硬件的分割,让FPGA以协处理器的方式加快这部分的处理速度。现以表1所示跑码数据为例说明相位编组的过程,其中Ai代表当前行的第i 个跑码,Bj代表上一行的第j个跑码,图3是跑码数据的位置示意图。
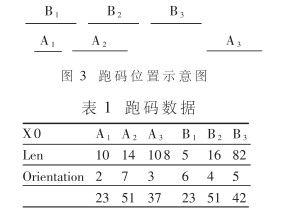
先从A1开始,拿它与上一行的各个跑码比,A1与B1位置连通,且方向值也相同,所以A1与B1连通。将A1的点放入B1所属的点集中。A1再与B2比,位置不连通,A1与B2不连通。由于B2在A2的后面,所以B2以后的跑码一定不会与A1连通,不用再比较了。我们称B2相对于A1越界。由此类推,A2与B1不连通,与B2连通,B3相对于A2越界。将A2的点放入B2所属的点集中。A3从B3前一个跑码开始比(这样可以省去与B2前面的跑码比较),A3与B2不连通,与B3也不连通。这样,一行比较完毕。将当前行上移,扫描下一行。一帧下来,就可以将所有直线的点集得到。相位编组的特点是数据结构复杂,要对内存进行复杂的操作。显然FPGA无法独立完成,如果把它交给DSP去做,其中判断Ai与Bj是否连通要经常使用,是相位编组中相对简单但大量重复使用的部分,可以写成如下函数:
int Is_Connect(RUNCODE runcodel,RUNCODE runcode2)
/*判决 位置连通性和梯度方向连通性/*
/* RETURN:255--连通0--不连通1--已经越界(runcodel.x0+runcodel.len-runcode2.x0)<0*/
{
if(runcode 1.x0<=runcode2.x0)
{ if((runcodel.x0+runcodel.len-runcode2.x0)>0)
{ if(abs(runcodel.orientation-runcode2.orientation)<Threshold)
return 255;
}
else
{ return 1;
}
}
else
{ if(runcode2.x0+runcode1.len-runcode1.0x)>0)
if(abs(runcode1.orientation-runcode2.orientation)<Threshold)
return 255;
}
return 0;
}
可以看出,函数中主要的操作是判断语句,判断语句内部的操作却不多。也就是说,在该函数中,DSP相当一部分时间里都在作判断。判断语句在汇编中对应的是条件跳转语句,这种频繁的跳转语句会使DSP内部的指令流水线中断,使cache命中率大为降低。实验表明,用DSP编程执行这段代码不能满足系统实时性的需要。硬件电路完成条件跳转指令只需要比较器和二选一开关即可,而且硬件电路实现多重判断和单一判断的速度是一样的。因此,硬件电路实现该函数不仅比较容易,而且执行速度只需一个时钟周期。于是我们用FPGA2实现此函数,让DSP来调用它,并取得了较理想的效果。
2 对FPGA用于协处理器的几点探讨
通过以上实例我们可以探讨一下FPGA用于协处理器的结构特点和设计原则。
2.1 FPGA作为协处理器所需的结构
硬件要完成某种应用方式,必须依赖于相应的系统硬件结构。FPGA在数字信号处理设计中最典型的应用有两种:一种是作为整个数据处理流程中的一个“结点”,数据沿着线状结构被不断加工处理,FPGA在这里作为处理单元,独立地完成算法中的某些功能。如图4。
图中的PE一般为DSP或单片机。上例中的前级FPGA1就是作为处理单元来应用的。另一种是作为协处理器,如图5。
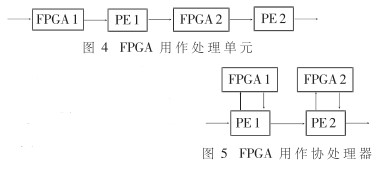
FPGA从属于PE,PE的一部分任务由FPGA分担。PE象调用软件中的函数一样来调用FPGA。只是函数内部写的不是完成该功能的语句,而是向FPGA送参数,再从FPGA接收结果。硬件的速度相对于PE的指令操作来说一般要快得多,可以认为将数据送出后马上就可得到结果。如果使用得当,这种结构可以大幅度提高PE的处理速度,需要指出的是,虽然硬件执行起来要比软件快,但是协处理器的开销主要在 PE与FPGA的接口上,要保证PE与FPGA有高速的双向通道,否则就达不到高速性的目的。在提取直线的系统中,DSP是通过自身的两个高速并行口(一发一收)与FPGA相连接的。实际上,如果想进一步提高协处理器的效率,应该考虑设计更快的接口。
2.2 FPGA作为协处理器的优点
使用FPGA作为协处理器的最大优势在于可根据具体算法的实际需要来为PE定做合适的硬件函数。传统的协处理器为了自身的通用性,实现的一般都是指令层次上的功能,如80387专门完成乘加运算,而FPGA设计和使用更灵活,可以将协处理器建立在函数层上。如直线提取中协处理器完成的函数,DSP本身不善长大量的逻辑判断,如果不结合具体的算法,在指令层次上很难解决DSP的这一弱点。只有在具体的算法中,对逻辑判断集中的一段程序进行硬件设计,才能做到比DSP高得多的效率。站在CPU的角度上看,CPU可以象调用软件函数一样来调用FPGA,而速度象汇编语句一样快。这样有效地克服了CPU的指令层次上效率低的弱点。又比如,矩阵乘法:

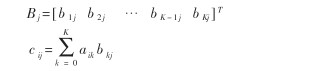
两个矩阵相乘,可以先分解为两个向量的乘法,如公式(1),继续分解为两个标量的乘法,如公式(2)。CPU的指令集只能做标量乘法,在这个层次上很难大幅度提高矩阵乘法的效率。如果用FPGA设计一个向量乘法器,则可以少MN(2K-2)条指令。如果订做一个矩阵乘法器,可以少NM(2K-1)-1条指令。
2.3 FPGA作为协处理器设计的原则
一般来讲,FPGA适合完成函数级的任务,比如矩阵乘法、查表法等。实际中,一个复杂的任务要做的处理比较多,我们不大可能把每个函数都硬件化,给FPGA分配怎样的任务才算恰当呢?在确定协处理器的任务时要整体把握,确定影响整体速度的瓶颈是哪部分,选择最有潜力可挖的部分。硬件分担的任务不是越多越好,这里面要综合考虑FPGA设计的难度,系统的实际要求等。FPGA的任务太多,可调用性变差,如果只能被调用很少的几次,它对整体速度的提高就不会有多少贡献,而且会增加FPGA设计的工作量。在直线提取的例子中,我们必须对算法框图各部分有较清楚的认识,看到判断两跑码的连通性要经常调用,而且DSP完成该函数效率不高,这两点是采用协处理器完成该函数的两个必要条件。C40的一个指令周期为50ns,如果不算调用函数时的堆栈操作,完成该函数至少需13个指令周期。而FPGA只需25.5ns就可完成。对于一幅512×512的图像,设一行里有150个跑码,平均每个跑码调用3次该函数,每调用一次FPGA比原来节省10个周期,则一帧图像可节省:
512×150×3×10×50ns=0.115s
在实际测试中,整体的运行时间比原来快了0.15s左右。
FPGA作为协处理器在相位编组算法的实现中得到了成功的应用。在较为复杂的处理中,我们可以将任务分解为上下层关系,下层简单而规则并且大量重复使用的工作交给FPGA完成,软件在上层调用它,从而提高了系统整体的处理速度。这里面,FPGA与传统协处理器相比更加灵活,这种灵活性不仅体现在FPGA可以更加帖近具体的算法进行设计上,而且依据可重构的思想,我们可以在不同的时间段上对FPGA加载不同的功能函数,系统资源从而得到了充分利用。
-
MD5信息摘要算法实现二(基于蜂鸟E203协处理器)2025-10-30 264
-
基于FPGA协处理器的算法及总线连接2022-10-27 1431
-
小白求助怎样去使用ARM协处理器呢2022-04-24 3850
-
采用FPGA协处理器实现算法加速教程2021-09-28 5131
-
为什么FPGA协处理器可以实现算法加速?2021-04-13 2708
-
举例说明FPGA作为协处理器在实时系统中有哪些应用?2021-04-08 1507
-
通过利用FPGA协处理器实现对汽车娱乐系统进行优化设计2020-07-24 1166
-
让FPGA协处理器实现代码加速的方法有哪些?2019-09-03 2158
-
如何利用串行RapidIO实现FPGA协处理器?2019-08-07 2895
-
采用FPGA的协处理器来简化ASIC仿真2019-07-23 1565
-
基于FPGA平台的嵌入式PowerPC协处理器实现算法加速设计2018-07-22 1736
-
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现2015-02-02 3723
-
FPGA协处理器的优势2011-09-29 6263
-
FPGA协处理技术介绍及进展2010-04-26 1190
全部0条评论

快来发表一下你的评论吧 !
