

使用VHDL语言和FPGA技术实现高效微控制器内核的设计
描述
与传统投片实现ASIC相比,FPGA具有实现速度快、风险小、可编程、可随时更改升级等一系列优点,因而得到了越米越广泛的应用。MCS-51应用时间长、范围广,相关的软硬件资源丰富,因而往往在FPGA应用中嵌人MCS-51内核作为微控制器。但是传统MCS-51的指令效率太低,每个机器周期高达12时钟周期,因此必须对内核加以改进,提高指令执行速度和效率,才能更好地满足FPGA的应用。
通过对传统MCS-51单片机指令时序和体系结构的分析,使用VHDL语言采用自顶向下的设计方法重新设计了一个高效的微控制器内核。改进了的体系结构,可以兼容MCS-51所有指令,每个机器周期只需1个时钟周期,同时增加了硬件看门狗和软件复位功能,提高了指令执行效率和抗干扰能力。
1 系统设计
1.1 模块划分
本内核在划分和设计模块时,基于以下几条原则:
(1)同步设计,提高系统稳定性和可移植性;(2)功能明确,功能接近的放在同一个模块内以减少模块的数量和模块之间的互连线,同时利于综合时的优化;(3)模块之间的接口时序预先定义好,并严格按定义的时序要求编写每个模块;(4)模块信号的输出采用寄存器输出的方式。这样可以提高系统的可靠性,一旦出错也容易确定问题所在。
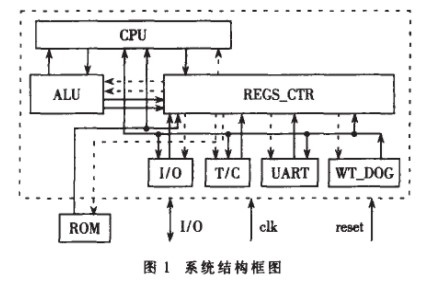
本内核由以下几个部分组成:中央控制单元(CPU),算术逻辑运算单元(ALU),寄存器组控制器(REGS_CTR),定时器/计数器(T/C),通用串行接口(UART),看门狗(WT_DOG),如图1所示。
1.2 提高速度的方法
本内核采用以下几种办法来提高速度。
(1) 采用多数据通道:本内核取消了传统MCS-51系列单片机的单一总线,采用直连结构,各模块的数据传输使用单向专用数据线,尤其在数据交换频繁的ALU与REGS_CTR之间采用四条单向数据线相互连接,提高了数据传输的并行度,从而加快了数据的传输。
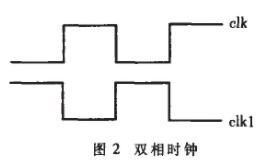
(2) 采用双相时钟:如图2所示。CLK时钟上升沿CPU发出控制信号,I/O端口采样外部信号即图1中流入REGS_CTR的数据或控制信号;CLK1时钟上升沿把数据写入寄存器中并把刷新后的数据或控制信号发出,即图1中虚箭头表示的数据流向。这样REGS_CTR的读写分别在两个时钟的上升沿,减少了一个时钟周期的等待,时钟频率提高了一倍。
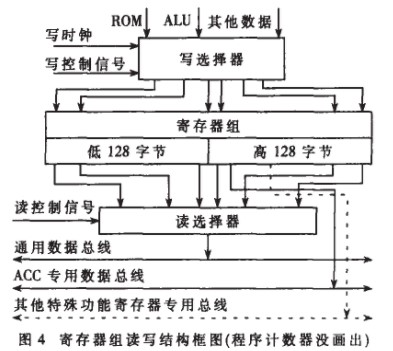
(3) 采用寄存器组:FPGA内部有极为丰富的寄存器资源,本内核取消了传统的同一时间只能读或者写的RAM块,代之以可同时进行不同地址读写操作的寄存器组。一些特殊功能寄存器有专用总线输出,如图3所示。
(4) 提高时钟频率:对电路的关键路径进行了改造,以减少逻辑电路级数从而提高时钟频率。通过这些设计,保证了每个机器周期只需一个时钟周期,提高了指令执行效率,同时也提高系统的时钟频率。
1.3 兼容性方面的考虑
MCS-51系列单片机有丰富的软硬件资源,为充分利用这些资源,在本内核设计时尽量考虑增强其兼容性。除机器周期变为原来的1/12以及新增加一个特殊功能寄存器(地址F8H)用于控制看门狗和软件复位外,其他没有变化。因而单个内核应用时,以前的程序可完全移植;在与外界通信时因机器周期与MCS-51单片机有差别可能需对一些程序作相应改动。这样可以使系统在提高性能的同时无需其他开销,便于推广使用。
2 功能模块的设计
2.1 中央控制器(CPU)的设计
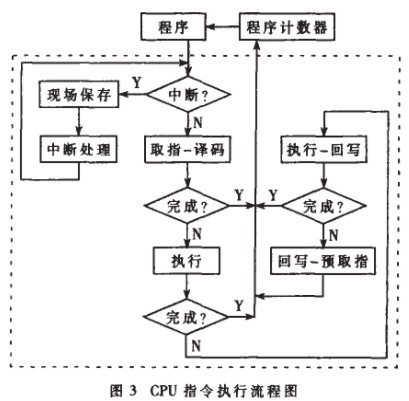
这是微控制器的核心,负责中断处理及指令执行。中断处理分为中断取样、中断高低优先级的判断及执行相应的处理过程。CPU对指令的执行分为四个阶段:取指-译码、执行、执行-回写、回写-预取指。指令执行流程如图4所示。
在编码实现方式上,本模块是一个大的父子两级状态机,父状态机为指令的类型,子状态机为每种指令的执行步骤。这样结构清晰,利于编程、查错及仿真。
2.2 寄存器组(REGS_CTR)的设计
本模块在CPU的控制下完成:程序地址的产生、高低128个寄存器的读写。程序计数器根据控制信号与来自寄存器组的数据产生相应的指令地址并送往ROM。在寄存器组的读写中,用读译码电路选择输出操作数据,写译码电路写入结果数据。这种结构可以在对一个寄存器写的同时读另一个寄存器。如图3所示,通用的数据总线可以取得任何一个寄存器的数据,各个专用寄存器也有各自的专用数据线输出。例如执行指令ADDA,DIRECT时,由于累加器ACC有专门的总线,只要给出相应的读控制信号就可以从通用数据总线上得到来自寄存器组的DIRECT数据,这样ALU在同一周期内就可以得到所需的两个操作数。
2.3 看门狗(WT_DOG)的设计
传统的MCS-51系列单片机为提高抗干扰能力通常使用外置看门狗或者采用软件陷阱的方式使系统复位。本内核增加了硬件看门狗及软件复位功能,通过新增加一个特殊功能寄存器(地址F8H)来控制是否启用看门狗或软件复位以及设置看门狗的喂狗时间。除非掉电或用程序重新设置,F8H寄存器的数值一直保存,这样避免了看门狗复位后其自身失效的问题。
2.4 算术逻辑运算单元(ALU)的设计
累加器在CPU发出的指令控制下,对来自ROM与REGS_CTR的数据完成相应的操作,包括算术运算(加减乘除)与逻辑运算(与或非)及BCD码调整。所有操作的结果在一个时钟周期内得出,在clkl上升沿到来后写入REGS_CTR。
2.5 串行模块及定时/计数器的设计
串行模块和定时/计数器的工作模式与传统的MCS-51系列单片机相同。定时/计数器一个时钟周期计数一次,与传统MCS-51单片机一个机器周期计数一次效果等同。在与外界用串行端口通信时机器周期有差别。
3 仿真、综合优化及实现
3.1 仿真
为了保证内核正确地工作,必须对电路做充分的仿真以保证设计的正确性。系统设计完成后用ModelSim Se PLUS 6.0D对电路进行了功能仿真,对组合逻辑模块(如ALU)采用了穷举测试向量的方法予以功能仿真,对于时序模块如CPU,先测试能否正确执行中断及每一条指令,再测试随机指令及随机中断。仿真结果表明,内核能满足设计的要求。ALU的仿真结果如同5所示。
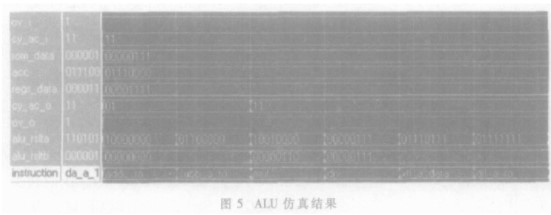
其中rom_data、acc、regs_data为ALU的操作数,in-struction为指令的类别,alu_rslta、alu_rsltb为ALU的操作结果的高、低字节。由图5可见,在输入操作数和进位溢位标志位不变的情况下,不同的指令都能输出相对应的正确结果。ALU操作结果的数据予以锁存,直到下一个指令或数据到来时才改变。在保持指令不变的情况下改变输入数据和进位溢位标志位也能得到正确的结果。
3.2 综合优化
为了尽可能提高时钟频率,必须降低关键路径的延时。由于ALU所有的操作都要在一个周期内完成,因而操作所需的最长时间也是时钟周期的最小值。综合分析后发现操作时间最长的是除法运算,采用通移位相减除法器所需时间为39ns,如果采用并行除法器后则只需23ns,从而显著提高了时钟频率。内核综合后消耗的LUT为4500个。
3.3 实现
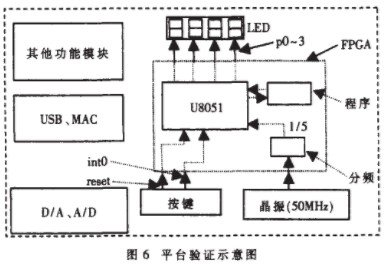
本内核的全部工作都在ISE7.1开发环境下完成。其中,仿真用的是ModelSim Se PLUS 6.0D,综合用的软件是Synplify Pro 8.0。验证采用的平台足CREAT-SOPC1000X试验箱,它的核心芯片即FPGA使用的是Xilinx公司的Virtex-Ⅱxc2v1000-6 fg456,等效为100万门电路,如图6所示。平台上集成了一些常用的功能模块,其中的晶振为50MHz,超过了本内核综合后的最高频率,因而设计了一个5分频模块使时钟为10MHz。内核运行的测试程序和数据以事先机器代码的形式“固化”在一个程序模块内替代ROM,系统可以像ROM一样对其读取数据和程序。P0-3输出观察数据,检验程序是否正确执行。验证结果表明,内核能正确执行加载的程序并稳定运行在10MHz的频率上。
为克服传统MCS-51单片机执行效率偏低的缺点,满足现在的FPGA对嵌入式软核速度较高的要求,重新设计了一个兼容MCS-51指令的嵌入式软核。该软核指令效率提高了12倍,同时增加了实用的功能:硬件看门狗和软件复位。内核通过FPGA验证具有一定的应用价值。
-
请问如何实现微控制器与FPGA的接口设计?2021-05-06 1851
-
怎么使用VHDL语言设计一个高效的微控制器内核?2021-04-13 1768
-
基于FPGA的DSP技术实现伺服控制器的应用方案与设计2020-11-30 3402
-
基于VHDL语言和可编程逻辑器件实现Petri网逻辑控制器的设计2020-09-22 1459
-
基于VHDL语言和FPGA开发板实现数字秒表的设计2019-07-24 5282
-
请问VHDL语言和verilog语言有什么区别?2019-03-28 3031
-
怎么通过FPGA实现微控制器?2019-03-22 3551
-
利用VHDL硬件描述语言和FPGA技术完成驱动时序电路的实现2017-11-24 2198
-
基于VHDL的SDRAM控制器的实现2017-01-22 1111
-
FM收音机的解码及控制器VHDL语言实现2016-06-07 1011
-
针对微控制器应用的FPGA的实现2012-08-20 2565
-
基于VHDL的DRAM控制器设计2012-02-02 1992
-
基于VHDL语言的智能拨号报警器的设计2009-10-12 1664
全部0条评论

快来发表一下你的评论吧 !
