

Vivado HLS实现Canny边缘检测硬件加速实现方法
电子说
描述
摘要:
针对Canny边缘检测算法在实时图像处理过程中运算耗时长、数据运算量大的缺点,研究了利用Vivado HLS实现Canny边缘检测算法的硬件加速方法。该方法由FPGA的逻辑资源生成算法对应的RTL级硬件电路,实现算法硬件加速。实验结果表明,该方法能快速实时检测图像边缘,有效降低FPGA设计图像算法的难度,可以应用到实时视频图像处理中。
0 引言
边缘检测是图像特征提取、目标识别的基础,图像边缘提取的好坏直接影响后续处理的难易度和准确度。在众多边缘提取算法中,Canny边缘提取算法由于其良好的检测效果在图像处理中得到广泛应用。而现阶段的工业视觉检测中,图像处理多为PC平台或者ARM平台,在这些平台下,Canny边缘检测由于计算量大、耗时长,对平台本身性能要求也很高。FPGA凭借高速并行性的特性,在进行图像处理时能很好地保证系统的实时性,因此越来越多开发人员使用FPGA进行图像处理[1-3]。但在现有的文献中,有些受FPGA的历史功能设计局限,过多地关注FPGA底层设计,有些采用中值滤波、改进高斯滤波模板进行Canny边缘检测,设计周期较长,硬件加速效果不明显。武汉科技大学彭习武等采用了Xilinx公司的Vivado HLS(高层次综合)实现改进的Sobel边缘检测[4],取得了较好的实时检测效果,但需选择不同的结构元素对不同的目标图像进行膨胀腐蚀,算法占用硬件资源较多。本文采用Vivado HLS实现Canny边缘检测硬件加速实现方法,研究通用性好、设计周期短、硬件资源消耗少的FPGA加速算法。
1 Canny算法基本原理
Canny边缘检测[5]算法是CANNY J于1986年提出的,算法目标是在图像中找到最佳边缘。其主要步骤为:
(1)图像高斯滤波:对原始图像进行高斯滤波,降低输入图像中的噪声对后续图像处理的干扰,有效提升算法抗噪能力。
(2)梯度计算:选择Sobel的水平与垂直方向3×3窗口模板算子与图像阵列进行计算,原始图像为I(i,j),得到水平与垂直方向的偏导数,水平、垂直方向梯度偏导数分别为Gx和Gy:

(3)非极大值抑制:遍历图像,若像素点的幅值大于其梯度方向的幅值,则可能为边缘点;否则不是边缘,对其进行抑制。
(4)双阈值处理:通过设定阈值Th、Tl(一般情况下Tl=0.4Th),抑制后的图像像素梯度值大于Th的是边缘点,小于Tl的一定不是边缘点,如果处于两者之间,判断当前像素的邻域像素中是否有边缘点,若有,则为边缘点,否则就不是边缘。
2 Vivado HLS实现方式
Vivado HLS是Xilinx公司推出的加速数字系统设计开发工具,直接使用C、C++或SystemC开发的高层描述来综合数字硬件,替代用VHDL或Verilog实现FPGA硬件设计[6],实现设计的功能和硬件分离,不需要关心低层次具体细节,具有很强的灵活性,有效降低数字系统设计开发周期。Vivado HLS在算法优化指标和FPGA硬件设计方式指标是一致的:(1)面积,算法硬件资源使用的数量;(2)速度,硬件电路处理数据的速率。一般的设计是对两者之间的特殊需求进行优化,得到合理的方案。
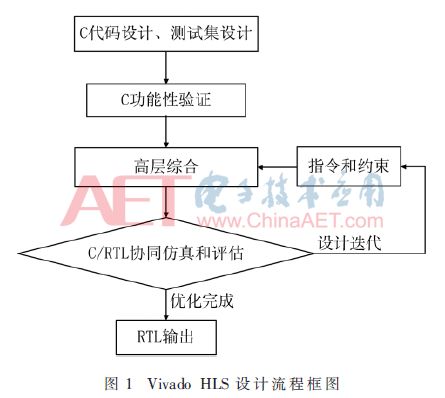
2.1 Vivado HLS设计流程
Vivado HLS设计流程如图1所示。C代码设计和C测试集设计是HLS设计流程的输入;C功能性验证能确保代码功能的完整性;高层综合能产生所需的各个设计文件;C/RTL协同仿真可以进行预期值与输出的对比;设计迭代是通过不断地调整指令得到预期需要的优化设计,在不改变C代码的情况下,由优化指令转化成小面积高吞吐率的RTL电路[7];最后RTL电路被综合成FPGA逻辑模块。
2.2 Vivado HLS图像实时加速
Vivado HLS图像实时加速设计的方式如图2所示。
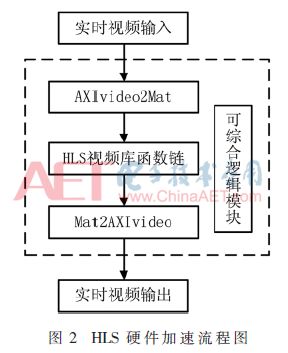
视频流进入FPGA后,由AXI4-Stream协议将数据流转换为HLS视频库下的hls::Mat格式,在进行对应的图像FPGA加速处理后,将hls::Mat格式重新转换为AXI4-Stream数据流。
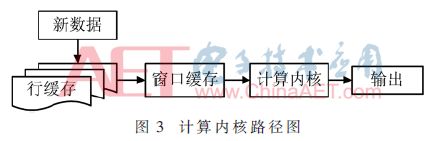
Vivado HLS提供了以下几个方面功能对图像视频处理建模[8]:(1)内存行缓存(Memory Line Buffer);(2)内存窗口缓存(Memory Window Buffer);(3)视频数据支持格式类型;(4)视频函数库。HLS内存行缓存实质是能存储多行像素数据的多维移位寄存器[9],而窗口缓存是行缓存的一个子集,这两种存储结构一般被综合为Block RAM,并且行缓存的宽度决定了图像算法能进行硬件加速的最大图像宽度。Vivado HLS对一帧图像像素的遍历是通过创建上述两种缓存实现的,图3是遍历图像像素的计算内核路径。Vivado HLS下图像处理基于视频流访问,因此,基于随机存储访问的图像处理方式需要进行转换,综合为FPGA处理下的图像数据流处理方式,实现图像算法的硬件加速。
3 Vivado HLS实现Canny边缘检测
根据Vivado HLS设计流程,Canny边缘检测的硬件加速实现流程如图4所示。
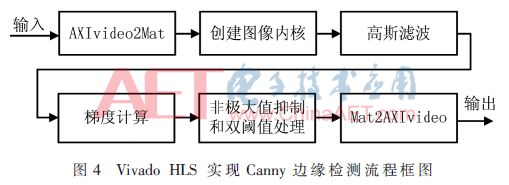
3.1 图像数据流输入
图像数据通过AXI4-Stream输入到Canny边缘检测IP,由AXIvideo2Mat将数据流转换为hls::Mat类型,完成Canny边缘检测IP的硬件加速设计。
3.2 图像计算内核创建
创建类型为hls::Window、大小为1×3和3×3的窗口缓存,以及类型为hls::LineBuffer、大小为3×1 920的行缓存。将图像像素写入第一行行缓存,每写入一次新的图像数据,读出对应行缓存的数据到1×3的窗口缓存,同时3×3的窗口缓存右移,把1×3的窗口缓存数据写入3×3的窗口缓存的第一列,每一行行缓存写满时,当前行缓存数据移位写入下一行。通过上述方式,由3×3窗口缓存构成的计算内核完成图像的遍历。
3.3 图像滤波
考虑到滤波器窗口太大图像边缘会被过度平滑,选择高斯滤波器为3×3的滤波窗口,σ值为1.5,由于模版系数归一化后均为小数,对于FPGA而言,需要增加硬件资源消耗实现浮点类型,因此,将模板系数全部乘以256后取整,对于实际处理而言,这种近似值产生的误差不会对滤波效果产生很大影响,实际模板系数为:
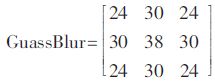
将滤波模板GuassBlur与计算内核进行卷积,卷积后的结果右移8位(除以256),移位操作不会消耗FPGA的DSP资源,节约了FPGA资源,由上述的移位运算后,完成图像数据的高斯滤波。
3.4 梯度计算
创建3×3滤波后的图像计算内核窗口,将计算内核分别与Sobel的水平与垂直方向3×3窗口算子卷积,求得水平、垂直方向梯度偏导数Gx和Gy大小,由于硬件实现平方根需要的资源较多,故通过Gx和Gy的绝对值之和求梯度G的幅值。对于梯度的方向θ=arctan(Gy/Gx),硬件实现较为困难,需要消耗很多硬件资源,一般是比较像素领域窗口,对于3×3窗口而言,求其领域8个方向,由于对称性,只需要求得4个方向,0°、45°、90°和135°,即把梯度Gy的值与Gxtan22.5°和Gxtan67.5°比较,同时判断GyGx乘积的正负性,可求得梯度的方向θ值的大小。为节约硬件资源可以采取对Gy左移4位,Gxtan22.5°左移4位,取值约为6.625Gx,Gxtan67.5°左移4位,约为38.625Gx,即:
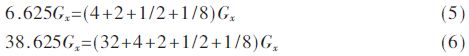
通过简单移位判断大小和正负性,得到梯度方向θ的近似值。
3.5 非极大值抑制和双阈值处理
定义位宽为2位的寄存器,4个方向对应寄存器值0,1,2,3,将该寄存器与存储梯度值G寄存器组合输出到新创建的图像行缓存,并创建新的3×3计算内核,通过计算内核窗口判断图像数据的方向,进行极大值抑制。计算内核中心点与对应梯度方向的像素点、高阈值Th、低阈值Tl进行比较,若计算内核中心点最大则为图像强边缘点;若计算内核中心点大于梯度方向,处于Tl和Th之间,为弱边缘点;其他情况均不是图像的边缘点。
创建新的行缓存写入上述图像边缘数据,由新的3×3计算内核做进一步处理:若计算内核中心点是强边缘点输出255;若计算内核是弱边缘点,判断其八邻域是否存在强边缘点,不存在强边缘点则输出0,存在则输出255,同时把中心点值改变为强边缘点值;其他情况直接输出0。
3.6 图像数据流输出
处理后的数据通过AXIvideo2Mat将hls::Mat格式重新转为AXI4-Stream数据流,图像数据通过上述的处理完成Canny边缘检测的硬件加速。
3.7 指令优化迭代
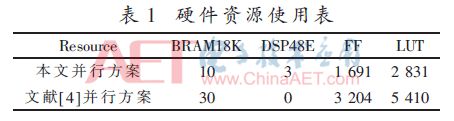
采用Vivado HLS提供的模块优化指令如inline、pipeline、dataflow以及对循环展开的unroll等,完成算法硬件加速的优化,达到硬件资源消耗和算法处理速度之间的平衡。一般的优化为串行方式和并行方式两种,串行优化方式使用硬件资源少,并行优化方式处理速率高[4]。为获得良好的硬件加速效果,选择并行优化方式,具体措施为:(1)对模块内部循环展开;(2)循环、模块内部流水化处理;(3)模块之间流水化处理。为验证本方案的资源占用情况,选取文献[4]进行对比分析,在保证运算速度基本相同的情况下,选取并行方案对硬件资源使用情况列于表1。从表1可以看出,本文边缘检测算法的硬件资源使用少。
4 边缘检测效果与速度验证
以Zedboard开发板为算法验证平台,开发板FPGA芯片型号为xc7z020484-1,图像由开发板PS端输入到FPGA算法IP中,通过HDMI将原始图像和处理后图像输出到显示屏。
图5(a)为512×512测试图像;图5(b)为PC进行的Canny边缘检测图像;图5(c)为FPGA验证的图像;PC的主频为2.3 GHz,对应的图5(b)处理时间约为10 ms左右;FPGA的时钟频率为100 MHz,图5(c)处理时间约为3 ms。
由图5(c)和图5(b)处理时间的对比可知,图5(c)算法处理时间不到图5(b)的1/3,说明加速效果明显。从文献[1]中可知,在相同系统时钟下处理512×512的图像,时间约为20 ms,远小于图5(c)的处理速度。因此,Vivado HLS实现的Canny边缘检测算法能在较复杂的情况下检测到图像边缘,且运算速度快。
5 结论
由Vivado HLS进行FPGA图像算法硬件加速设计方式,既避免了传统FPGA图像算法开发中过于关注底层细节,又能有效地缩短开发周期。通过仿真与FPGA验证,采用Vivado HLS实现的Canny边缘检测算法能在较复杂的情况下检测到图像边缘,运算速度快,资源消耗少,可以应用到实时视觉检测中。
-
基于Canny边缘检测算子的图像检索算法2010-04-24 0
-
用OpenCV和Vivado HLS加速基于Zynq SoC的嵌入式视觉应用开发2014-04-21 0
-
【Z-turn Board试用体验】+ 基于Z-turn的图像边缘检测系统(三)2015-07-07 0
-
关于canny算子边缘检测的问题2017-04-04 0
-
【KV260视觉入门套件试用体验】 硬件加速之—使用PL加速FFT运算(Vivado)2023-10-02 0
-
【KV260视觉入门套件试用体验】硬件加速之—使用PL加速矩阵乘法运算(Vitis HLS)2023-10-13 0
-
基于Canny 法的红外小目标边缘检测方法2009-05-27 563
-
canny边缘检测2016-06-06 399
-
精确分类的视角无关人脸检测方法与硬件加速体系结构2016-09-18 572
-
硬件加速边缘检测优化处理方案2017-11-15 2277
-
使用iVeia视觉套件进行Canny边缘检测HLS IP2018-11-30 3068
-
Canny图像算法仿真验证原理与实现2021-10-15 2030
-
UltraFast Vivado HLS方法指南2023-09-13 293
-
python中用Canny边缘检测和霍夫变实现车道线检测方法2023-11-17 1258
-
Canny双阈值边缘检测和弱边缘连接详解2023-11-18 3109
全部0条评论

快来发表一下你的评论吧 !
